 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored Policy Optimization: Mitigating Exploration Collapse Via Support-Constrained Rectification
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is increasingly viewed as a tree pruning mechanism. However, we identify a systemic pathology termed Recursive Space Contraction (RSC), an irreversible collapse driven by the combined dynamics of positive sharpening and negative squeezing, where the sampling probability of valid alternatives vanishes. While Kullback-Leibler (KL) regularization aims to mitigate this, it imposes a rigid Shape Matching constraint that forces the policy to mimic the reference model's full density, creating a gradient conflict with the sharpening required for correctness. We propose Anchored Policy Optimization (APO), shifting the paradigm from global Shape Matching to Support Coverage. By defining a Safe Manifold based on the reference model's high-confidence support, APO permits aggressive sharpening for efficiency while selectively invoking a restorative force during error correction to prevent collapse. We theoretically derive that APO serves as a gradient-aligned mechanism to maximize support coverage, enabling an Elastic Recovery that re-inflates valid branches. Empirical evaluations on mathematical benchmarks demonstrate that APO breaks the accuracy-diversity trade-off, significantly improving Pass@1 while restoring the Pass@K diversity typically lost by standard policy gradient methods.
Enhancing Diffusion-Based Quantitatively Controllable Image Generation via Matrix-Form EDM and Adaptive Vicinal Training
Feb 02, 2026Continuous Conditional Diffusion Model (CCDM) is a diffusion-based framework designed to generate high-quality images conditioned on continuous regression labels. Although CCDM has demonstrated clear advantages over prior approaches across a range of datasets, it still exhibits notable limitations and has recently been surpassed by a GAN-based method, namely CcGAN-AVAR. These limitations mainly arise from its reliance on an outdated diffusion framework and its low sampling efficiency due to long sampling trajectories. To address these issues, we propose an improved CCDM framework, termed iCCDM, which incorporates the more advanced \textit{Elucidated Diffusion Model} (EDM) framework with substantial modifications to improve both generation quality and sampling efficiency. Specifically, iCCDM introduces a novel matrix-form EDM formulation together with an adaptive vicinal training strategy. Extensive experiments on four benchmark datasets, spanning image resolutions from $64\times64$ to $256\times256$, demonstrate that iCCDM consistently outperforms existing methods, including state-of-the-art large-scale text-to-image diffusion models (e.g., Stable Diffusion 3, FLUX.1, and Qwen-Image), achieving higher generation quality while significantly reducing sampling cost.
InstructDiff: Domain-Adaptive Data Selection via Differential Entropy for Efficient LLM Fine-Tuning
Jan 30, 2026Supervised fine-tuning (SFT) is fundamental to adapting large language models, yet training on complete datasets incurs prohibitive costs with diminishing returns. Existing data selection methods suffer from severe domain specificity: techniques optimized for general instruction-following fail on reasoning tasks, and vice versa. We observe that measuring entropy differences between base models and minimally instruction-tuned calibrated models reveals a pattern -- samples with the lowest differential entropy consistently yield optimal performance across domains, yet this principle manifests domain-adaptively: reasoning tasks favor entropy increase (cognitive expansion), while general tasks favor entropy decrease (cognitive compression). We introduce InstructDiff, a unified framework that operationalizes differential entropy as a domain-adaptive selection criterion through warmup calibration, bi-directional NLL filtering, and entropy-based ranking. Extensive experiments show that InstructDiff achieves 17\% relative improvement over full data training on mathematical reasoning and 52\% for general instruction-following, outperforming prior baselines while using only 10\% of the data.
Heterogeneous Multi-Expert Reinforcement Learning for Long-Horizon Multi-Goal Tasks in Autonomous Forklifts
Jan 12, 2026Autonomous mobile manipulation in unstructured warehouses requires a balance between efficient large-scale navigation and high-precision object interaction. Traditional end-to-end learning approaches often struggle to handle the conflicting demands of these distinct phases. Navigation relies on robust decision-making over large spaces, while manipulation needs high sensitivity to fine local details. Forcing a single network to learn these different objectives simultaneously often causes optimization interference, where improving one task degrades the other. To address these limitations, we propose a Heterogeneous Multi-Expert Reinforcement Learning (HMER) framework tailored for autonomous forklifts. HMER decomposes long-horizon tasks into specialized sub-policies controlled by a Semantic Task Planner. This structure separates macro-level navigation from micro-level manipulation, allowing each expert to focus on its specific action space without interference. The planner coordinates the sequential execution of these experts, bridging the gap between task planning and continuous control. Furthermore, to solve the problem of sparse exploration, we introduce a Hybrid Imitation-Reinforcement Training Strategy. This method uses expert demonstrations to initialize the policy and Reinforcement Learning for fine-tuning. Experiments in Gazebo simulations show that HMER significantly outperforms sequential and end-to-end baselines. Our method achieves a task success rate of 94.2\% (compared to 62.5\% for baselines), reduces operation time by 21.4\%, and maintains placement error within 1.5 cm, validating its efficacy for precise material handling.
Infer As You Train: A Symmetric Paradigm of Masked Generative for Click-Through Rate Prediction
Nov 18, 2025Generative models are increasingly being explored in click-through rate (CTR) prediction field to overcome the limitations of the conventional discriminative paradigm, which rely on a simple binary classification objective. However, existing generative models typically confine the generative paradigm to the training phase, primarily for representation learning. During online inference, they revert to a standard discriminative paradigm, failing to leverage their powerful generative capabilities to further improve prediction accuracy. This fundamental asymmetry between the training and inference phases prevents the generative paradigm from realizing its full potential. To address this limitation, we propose the Symmetric Masked Generative Paradigm for CTR prediction (SGCTR), a novel framework that establishes symmetry between the training and inference phases. Specifically, after acquiring generative capabilities by learning feature dependencies during training, SGCTR applies the generative capabilities during online inference to iteratively redefine the features of input samples, which mitigates the impact of noisy features and enhances prediction accuracy. Extensive experiments validate the superiority of SGCTR, demonstrating that applying the generative paradigm symmetrically across both training and inference significantly unlocks its power in CTR prediction.
DGenCTR: Towards a Universal Generative Paradigm for Click-Through Rate Prediction via Discrete Diffusion
Aug 20, 2025
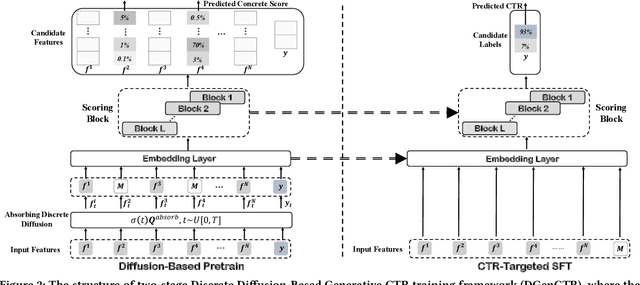
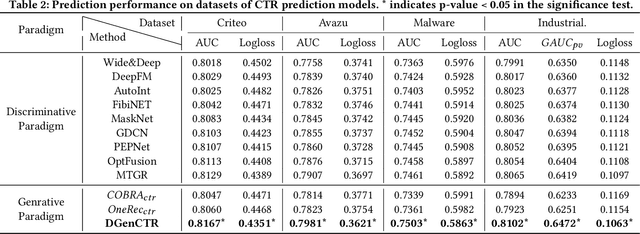
Recent advances in generative models have inspired the field of recommender systems to explore generative approaches, but most existing research focuses on sequence generation, a paradigm ill-suited for click-through rate (CTR) prediction. CTR models critically depend on a large number of cross-features between the target item and the user to estimate the probability of clicking on the item, and discarding these cross-features will significantly impair model performance. Therefore, to harness the ability of generative models to understand data distributions and thereby alleviate the constraints of traditional discriminative models in label-scarce space, diverging from the item-generation paradigm of sequence generation methods, we propose a novel sample-level generation paradigm specifically designed for the CTR task: a two-stage Discrete Diffusion-Based Generative CTR training framework (DGenCTR). This two-stage framework comprises a diffusion-based generative pre-training stage and a CTR-targeted supervised fine-tuning stage for CTR. Finally, extensive offline experiments and online A/B testing conclusively validate the effectiveness of our framework.
Unveiling Over-Memorization in Finetuning LLMs for Reasoning Tasks
Aug 06, 2025

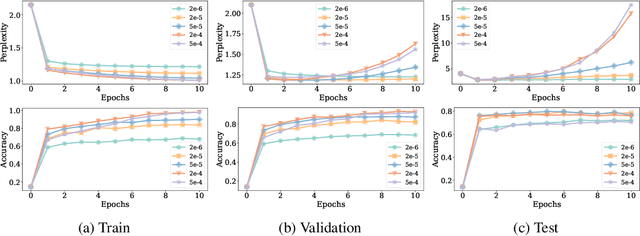

The pretrained large language models (LLMs) are finetuned with labeled data for better instruction following ability and alignment with human values. In this paper, we study the learning dynamics of LLM finetuning on reasoning tasks and reveal the uncovered over-memorization phenomenon during a specific stage of LLM finetuning. At this stage, the LLMs have excessively memorized training data and exhibit high test perplexity while maintaining good test accuracy. We investigate the conditions that lead to LLM over-memorization and find that training epochs and large learning rates contribute to this issue. Although models with over-memorization demonstrate comparable test accuracy to normal models, they suffer from reduced robustness, poor out-of-distribution generalization, and decreased generation diversity. Our experiments unveil the over-memorization to be broadly applicable across different tasks, models, and finetuning methods. Our research highlights that overparameterized, extensively finetuned LLMs exhibit unique learning dynamics distinct from traditional machine learning models. Based on our observations of over-memorization, we provide recommendations on checkpoint and learning rate selection during finetuning.
Towards Bridging the Reward-Generation Gap in Direct Alignment Algorithms
Jun 11, 2025Direct Alignment Algorithms (DAAs), such as Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO), have emerged as efficient alternatives to Reinforcement Learning from Human Feedback (RLHF) algorithms for aligning large language models (LLMs) with human preferences. However, DAAs suffer from a fundamental limitation we identify as the "reward-generation gap" -- a misalignment between optimization objectives during training and actual generation performance during inference. In this paper, we find a contributor to the reward-generation gap is the mismatch between the inherent importance of prefix tokens during the LLM generation process and how this importance is reflected in the implicit reward functions of DAAs. To bridge the gap, we introduce a simple yet effective approach called Prefix-Oriented Equal-length Training (POET), which truncates both preferred and dispreferred responses to match the shorter one's length. Training with POET, where both responses in each sample are truncated to equal length, resulting in diverse truncated lengths across samples, the optimization of DAAs objective is implicitly constrained to converge across all positions, thus paying more attention to prefix tokens than the standard DAAs. We conduct experiments with DPO and SimPO, two representative DAAs, demonstrating that POET improves over their standard implementations, achieving up to 15.6 points in AlpacaEval 2 and overall improvements across downstream tasks. Our results highlight the importance of addressing the misalignment between reward optimization and generation performance in DAAs.
Automatic Robustness Stress Testing of LLMs as Mathematical Problem Solvers
Jun 05, 2025Large language models (LLMs) have achieved distinguished performance on various reasoning-intensive tasks. However, LLMs might still face the challenges of robustness issues and fail unexpectedly in some simple reasoning tasks. Previous works evaluate the LLM robustness with hand-crafted templates or a limited set of perturbation rules, indicating potential data contamination in pre-training or fine-tuning datasets. In this work, inspired by stress testing in software engineering, we propose a novel framework, Automatic Robustness Checker (AR-Checker), to generate mathematical problem variants that maintain the semantic meanings of the original one but might fail the LLMs. The AR-Checker framework generates mathematical problem variants through multi-round parallel streams of LLM-based rewriting and verification. Our framework can generate benchmark variants dynamically for each LLM, thus minimizing the risk of data contamination. Experiments on GSM8K and MATH-500 demonstrate the strong performance of AR-Checker on mathematical tasks. We also evaluate AR-Checker on benchmarks beyond mathematics, including MMLU, MMLU-Pro, and CommonsenseQA, where it also achieves strong performance, further proving the effectiveness of AR-Checker.
AudioTurbo: Fast Text-to-Audio Generation with Rectified Diffusion
May 28, 2025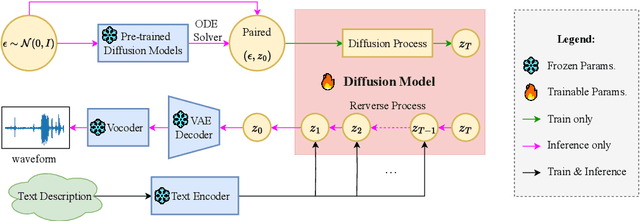
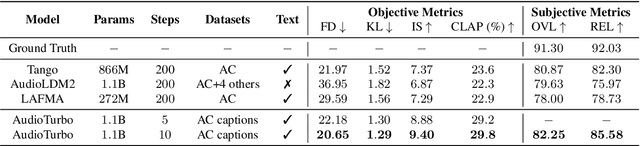
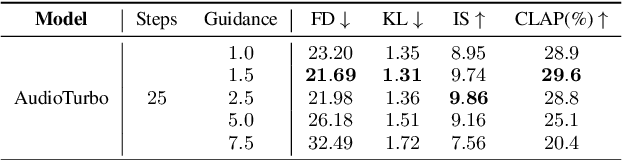
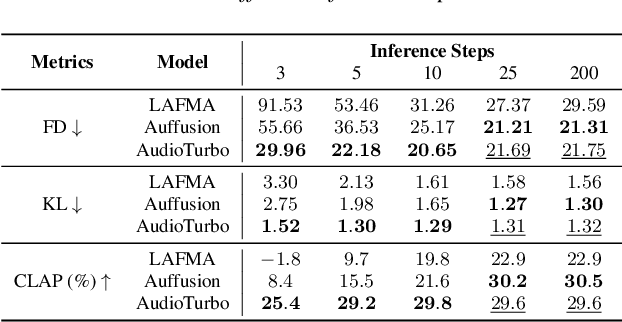
Diffusion models have significantly improved the quality and diversity of audio generation but are hindered by slow inference speed. Rectified flow enhances inference speed by learning straight-line ordinary differential equation (ODE) paths. However, this approach requires training a flow-matching model from scratch and tends to perform suboptimally, or even poorly, at low step counts. To address the limitations of rectified flow while leveraging the advantages of advanced pre-trained diffusion models, this study integrates pre-trained models with the rectified diffusion method to improve the efficiency of text-to-audio (TTA) generation. Specifically, we propose AudioTurbo, which learns first-order ODE paths from deterministic noise sample pairs generated by a pre-trained TTA model. Experiments on the AudioCaps dataset demonstrate that our model, with only 10 sampling steps, outperforms prior models and reduces inference to 3 steps compared to a flow-matching-based acceleration model.