 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA State-Transition Framework for Efficient LLM Reasoning
Feb 01, 2026While Long Chain-of-Thought (CoT) reasoning significantly improves Large Language Models (LLMs) performance on complex reasoning tasks, the substantial computational and memory costs of generating long CoT sequences limit their efficiency and practicality. Existing studies usually enhance the reasoning efficiency of LLMs by compressing CoT sequences. However, this approach conflicts with test-time scaling, limiting the reasoning capacity of LLMs. In this paper, we propose an efficient reasoning framework that models the reasoning process of LLMs as a state-transition process. Specifically, we first apply a linear attention mechanism to estimate the LLM's reasoning state, which records the historical reasoning information from previous reasoning steps. Then, based on the query prompt and the reasoning state, the LLM can efficiently perform the current reasoning step and update the state. With the linear attention, each token in the current reasoning step can directly retrieve relevant historical reasoning information from the reasoning state, without explicitly attending to tokens in previous reasoning steps. In this way, the computational complexity of attention is reduced from quadratic to linear, significantly improving the reasoning efficiency of LLMs. In addition, we propose a state-based reasoning strategy to mitigate the over-thinking issue caused by noisy reasoning steps. Extensive experiments across multiple datasets and model sizes demonstrate that our framework not only improves the reasoning efficiency of LLMs but also enhances their reasoning performance.
Finding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs
Jan 16, 2026Large Language Models (LLMs) frequently exhibit strong translation abilities, even without task-specific fine-tuning. However, the internal mechanisms governing this innate capability remain largely opaque. To demystify this process, we leverage Sparse Autoencoders (SAEs) and introduce a novel framework for identifying task-specific features. Our method first recalls features that are frequently co-activated on translation inputs and then filters them for functional coherence using a PCA-based consistency metric. This framework successfully isolates a small set of **translation initiation** features. Causal interventions demonstrate that amplifying these features steers the model towards correct translation, while ablating them induces hallucinations and off-task outputs, confirming they represent a core component of the model's innate translation competency. Moving from analysis to application, we leverage this mechanistic insight to propose a new data selection strategy for efficient fine-tuning. Specifically, we prioritize training on **mechanistically hard** samples-those that fail to naturally activate the translation initiation features. Experiments show this approach significantly improves data efficiency and suppresses hallucinations. Furthermore, we find these mechanisms are transferable to larger models of the same family. Our work not only decodes a core component of the translation mechanism in LLMs but also provides a blueprint for using internal model mechanism to create more robust and efficient models. The codes are available at https://github.com/flamewei123/AAAI26-translation-Initiation-Features.
Triplets Better Than Pairs: Towards Stable and Effective Self-Play Fine-Tuning for LLMs
Jan 13, 2026Recently, self-play fine-tuning (SPIN) has been proposed to adapt large language models to downstream applications with scarce expert-annotated data, by iteratively generating synthetic responses from the model itself. However, SPIN is designed to optimize the current reward advantages of annotated responses over synthetic responses at hand, which may gradually vanish during iterations, leading to unstable optimization. Moreover, the utilization of reference policy induces a misalignment issue between the reward formulation for training and the metric for generation. To address these limitations, we propose a novel Triplet-based Self-Play fIne-tuNing (T-SPIN) method that integrates two key designs. First, beyond current advantages, T-SPIN additionally incorporates historical advantages between iteratively generated responses and proto-synthetic responses produced by the initial policy. Even if the current advantages diminish, historical advantages remain effective, stabilizing the overall optimization. Second, T-SPIN introduces the entropy constraint into the self-play framework, which is theoretically justified to support reference-free fine-tuning, eliminating the training-generation discrepancy. Empirical results on various tasks demonstrate not only the superior performance of T-SPIN over SPIN, but also its stable evolution during iterations. Remarkably, compared to supervised fine-tuning, T-SPIN achieves comparable or even better performance with only 25% samples, highlighting its effectiveness when faced with scarce annotated data.
Deep But Reliable: Advancing Multi-turn Reasoning for Thinking with Images
Dec 19, 2025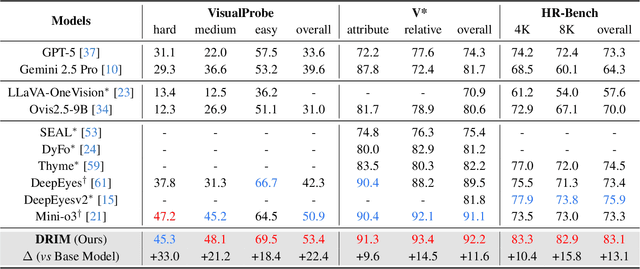
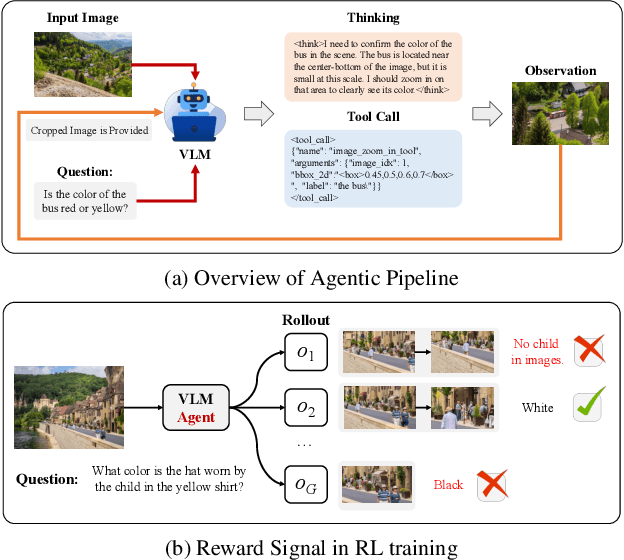
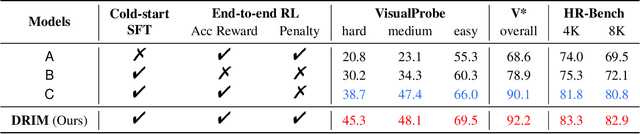
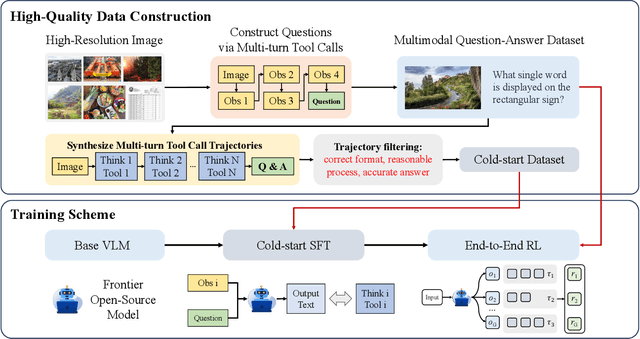
Recent advances in large Vision-Language Models (VLMs) have exhibited strong reasoning capabilities on complex visual tasks by thinking with images in their Chain-of-Thought (CoT), which is achieved by actively invoking tools to analyze visual inputs rather than merely perceiving them. However, existing models often struggle to reflect on and correct themselves when attempting incorrect reasoning trajectories. To address this limitation, we propose DRIM, a model that enables deep but reliable multi-turn reasoning when thinking with images in its multimodal CoT. Our pipeline comprises three stages: data construction, cold-start SFT and RL. Based on a high-resolution image dataset, we construct high-difficulty and verifiable visual question-answer pairs, where solving each task requires multi-turn tool calls to reach the correct answer. In the SFT stage, we collect tool trajectories as cold-start data, guiding a multi-turn reasoning pattern. In the RL stage, we introduce redundancy-penalized policy optimization, which incentivizes the model to develop a self-reflective reasoning pattern. The basic idea is to impose judgment on reasoning trajectories and penalize those that produce incorrect answers without sufficient multi-scale exploration. Extensive experiments demonstrate that DRIM achieves superior performance on visual understanding benchmarks.
Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images
Nov 10, 2025This paper presents Omni-View, which extends the unified multimodal understanding and generation to 3D scenes based on multiview images, exploring the principle that "generation facilitates understanding". Consisting of understanding model, texture module, and geometry module, Omni-View jointly models scene understanding, novel view synthesis, and geometry estimation, enabling synergistic interaction between 3D scene understanding and generation tasks. By design, it leverages the spatiotemporal modeling capabilities of its texture module responsible for appearance synthesis, alongside the explicit geometric constraints provided by its dedicated geometry module, thereby enriching the model's holistic understanding of 3D scenes. Trained with a two-stage strategy, Omni-View achieves a state-of-the-art score of 55.4 on the VSI-Bench benchmark, outperforming existing specialized 3D understanding models, while simultaneously delivering strong performance in both novel view synthesis and 3D scene generation.
REVISION:Reflective Intent Mining and Online Reasoning Auxiliary for E-commerce Visual Search System Optimization
Oct 26, 2025In Taobao e-commerce visual search, user behavior analysis reveals a large proportion of no-click requests, suggesting diverse and implicit user intents. These intents are expressed in various forms and are difficult to mine and discover, thereby leading to the limited adaptability and lag in platform strategies. This greatly restricts users' ability to express diverse intents and hinders the scalability of the visual search system. This mismatch between user implicit intent expression and system response defines the User-SearchSys Intent Discrepancy. To alleviate the issue, we propose a novel framework REVISION. This framework integrates offline reasoning mining with online decision-making and execution, enabling adaptive strategies to solve implicit user demands. In the offline stage, we construct a periodic pipeline to mine discrepancies from historical no-click requests. Leveraging large models, we analyze implicit intent factors and infer optimal suggestions by jointly reasoning over query and product metadata. These inferred suggestions serve as actionable insights for refining platform strategies. In the online stage, REVISION-R1-3B, trained on the curated offline data, performs holistic analysis over query images and associated historical products to generate optimization plans and adaptively schedule strategies across the search pipeline. Our framework offers a streamlined paradigm for integrating large models with traditional search systems, enabling end-to-end intelligent optimization across information aggregation and user interaction. Experimental results demonstrate that our approach improves the efficiency of implicit intent mining from large-scale search logs and significantly reduces the no-click rate.
Marco-Bench-MIF: On Multilingual Instruction-Following Capability of Large Language Models
Jul 16, 2025Instruction-following capability has become a major ability to be evaluated for Large Language Models (LLMs). However, existing datasets, such as IFEval, are either predominantly monolingual and centered on English or simply machine translated to other languages, limiting their applicability in multilingual contexts. In this paper, we present an carefully-curated extension of IFEval to a localized multilingual version named Marco-Bench-MIF, covering 30 languages with varying levels of localization. Our benchmark addresses linguistic constraints (e.g., modifying capitalization requirements for Chinese) and cultural references (e.g., substituting region-specific company names in prompts) via a hybrid pipeline combining translation with verification. Through comprehensive evaluation of 20+ LLMs on our Marco-Bench-MIF, we found that: (1) 25-35% accuracy gap between high/low-resource languages, (2) model scales largely impact performance by 45-60% yet persists script-specific challenges, and (3) machine-translated data underestimates accuracy by7-22% versus localized data. Our analysis identifies challenges in multilingual instruction following, including keyword consistency preservation and compositional constraint adherence across languages. Our Marco-Bench-MIF is available at https://github.com/AIDC-AI/Marco-Bench-MIF.
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Jun 13, 2025Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans -- a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
ComfyUI-R1: Exploring Reasoning Models for Workflow Generation
Jun 11, 2025AI-generated content has evolved from monolithic models to modular workflows, particularly on platforms like ComfyUI, enabling customization in creative pipelines. However, crafting effective workflows requires great expertise to orchestrate numerous specialized components, presenting a steep learning curve for users. To address this challenge, we introduce ComfyUI-R1, the first large reasoning model for automated workflow generation. Starting with our curated dataset of 4K workflows, we construct long chain-of-thought (CoT) reasoning data, including node selection, workflow planning, and code-level workflow representation. ComfyUI-R1 is trained through a two-stage framework: (1) CoT fine-tuning for cold start, adapting models to the ComfyUI domain; (2) reinforcement learning for incentivizing reasoning capability, guided by a fine-grained rule-metric hybrid reward, ensuring format validity, structural integrity, and node-level fidelity. Experiments show that our 7B-parameter model achieves a 97\% format validity rate, along with high pass rate, node-level and graph-level F1 scores, significantly surpassing prior state-of-the-art methods that employ leading closed-source models such as GPT-4o and Claude series. Further analysis highlights the critical role of the reasoning process and the advantage of transforming workflows into code. Qualitative comparison reveals our strength in synthesizing intricate workflows with diverse nodes, underscoring the potential of long CoT reasoning in AI art creation.
ComfyUI-Copilot: An Intelligent Assistant for Automated Workflow Development
Jun 05, 2025We introduce ComfyUI-Copilot, a large language model-powered plugin designed to enhance the usability and efficiency of ComfyUI, an open-source platform for AI-driven art creation. Despite its flexibility and user-friendly interface, ComfyUI can present challenges to newcomers, including limited documentation, model misconfigurations, and the complexity of workflow design. ComfyUI-Copilot addresses these challenges by offering intelligent node and model recommendations, along with automated one-click workflow construction. At its core, the system employs a hierarchical multi-agent framework comprising a central assistant agent for task delegation and specialized worker agents for different usages, supported by our curated ComfyUI knowledge bases to streamline debugging and deployment. We validate the effectiveness of ComfyUI-Copilot through both offline quantitative evaluations and online user feedback, showing that it accurately recommends nodes and accelerates workflow development. Additionally, use cases illustrate that ComfyUI-Copilot lowers entry barriers for beginners and enhances workflow efficiency for experienced users. The ComfyUI-Copilot installation package and a demo video are available at https://github.com/AIDC-AI/ComfyUI-Copilot.