 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSVBench: Towards Human-Level Evaluation of Multi-Shot Video Generation
Feb 27, 2026The evolution of video generation toward complex, multi-shot narratives has exposed a critical deficit in current evaluation methods. Existing benchmarks remain anchored to single-shot paradigms, lacking the comprehensive story assets and cross-shot metrics required to assess long-form coherence and appeal. To bridge this gap, we introduce MSVBench, the first comprehensive benchmark featuring hierarchical scripts and reference images tailored for Multi-Shot Video generation. We propose a hybrid evaluation framework that synergizes the high-level semantic reasoning of Large Multimodal Models (LMMs) with the fine-grained perceptual rigor of domain-specific expert models. Evaluating 20 video generation methods across diverse paradigms, we find that current models--despite strong visual fidelity--primarily behave as visual interpolators rather than true world models. We further validate the reliability of our benchmark by demonstrating a state-of-the-art Spearman's rank correlation of 94.4% with human judgments. Finally, MSVBench extends beyond evaluation by providing a scalable supervisory signal. Fine-tuning a lightweight model on its pipeline-refined reasoning traces yields human-aligned performance comparable to commercial models like Gemini-2.5-Flash.
Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
Nov 16, 2025We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee's Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.
ComfyUI-R1: Exploring Reasoning Models for Workflow Generation
Jun 11, 2025AI-generated content has evolved from monolithic models to modular workflows, particularly on platforms like ComfyUI, enabling customization in creative pipelines. However, crafting effective workflows requires great expertise to orchestrate numerous specialized components, presenting a steep learning curve for users. To address this challenge, we introduce ComfyUI-R1, the first large reasoning model for automated workflow generation. Starting with our curated dataset of 4K workflows, we construct long chain-of-thought (CoT) reasoning data, including node selection, workflow planning, and code-level workflow representation. ComfyUI-R1 is trained through a two-stage framework: (1) CoT fine-tuning for cold start, adapting models to the ComfyUI domain; (2) reinforcement learning for incentivizing reasoning capability, guided by a fine-grained rule-metric hybrid reward, ensuring format validity, structural integrity, and node-level fidelity. Experiments show that our 7B-parameter model achieves a 97\% format validity rate, along with high pass rate, node-level and graph-level F1 scores, significantly surpassing prior state-of-the-art methods that employ leading closed-source models such as GPT-4o and Claude series. Further analysis highlights the critical role of the reasoning process and the advantage of transforming workflows into code. Qualitative comparison reveals our strength in synthesizing intricate workflows with diverse nodes, underscoring the potential of long CoT reasoning in AI art creation.
ComfyUI-Copilot: An Intelligent Assistant for Automated Workflow Development
Jun 05, 2025We introduce ComfyUI-Copilot, a large language model-powered plugin designed to enhance the usability and efficiency of ComfyUI, an open-source platform for AI-driven art creation. Despite its flexibility and user-friendly interface, ComfyUI can present challenges to newcomers, including limited documentation, model misconfigurations, and the complexity of workflow design. ComfyUI-Copilot addresses these challenges by offering intelligent node and model recommendations, along with automated one-click workflow construction. At its core, the system employs a hierarchical multi-agent framework comprising a central assistant agent for task delegation and specialized worker agents for different usages, supported by our curated ComfyUI knowledge bases to streamline debugging and deployment. We validate the effectiveness of ComfyUI-Copilot through both offline quantitative evaluations and online user feedback, showing that it accurately recommends nodes and accelerates workflow development. Additionally, use cases illustrate that ComfyUI-Copilot lowers entry barriers for beginners and enhances workflow efficiency for experienced users. The ComfyUI-Copilot installation package and a demo video are available at https://github.com/AIDC-AI/ComfyUI-Copilot.
A SHAP-based explainable multi-level stacking ensemble learning method for predicting the length of stay in acute stroke
May 30, 2025Length of stay (LOS) prediction in acute stroke is critical for improving care planning. Existing machine learning models have shown suboptimal predictive performance, limited generalisability, and have overlooked system-level factors. We aimed to enhance model efficiency, performance, and interpretability by refining predictors and developing an interpretable multi-level stacking ensemble model. Data were accessed from the biennial Stroke Foundation Acute Audit (2015, 2017, 2019, 2021) in Australia. Models were developed for ischaemic and haemorrhagic stroke separately. The outcome was prolonged LOS (the LOS above the 75th percentile). Candidate predictors (ischaemic: n=89; haemorrhagic: n=83) were categorised into patient, clinical, and system domains. Feature selection with correlation-based approaches was used to refine key predictors. The evaluation of models included discrimination (AUC), calibration curves, and interpretability (SHAP plots). In ischaemic stroke (N=12,575), prolonged LOS was >=9 days, compared to >=11 days in haemorrhagic stroke (N=1,970). The ensemble model achieved superior performance [AUC: 0.824 (95% CI: 0.801-0.846)] and statistically outperformed logistic regression [AUC: 0.805 (95% CI: 0.782-0.829); P=0.0004] for ischaemic. However, the model [AUC: 0.843 (95% CI: 0.790-0.895)] did not statistically outperform logistic regression [AUC: 0.828 (95% CI: 0.774-0.882); P=0.136] for haemorrhagic. SHAP analysis identified shared predictors for both types of stroke: rehabilitation assessment, urinary incontinence, stroke unit care, inability to walk independently, physiotherapy, and stroke care coordinators involvement. An explainable ensemble model effectively predicted the prolonged LOS in ischaemic stroke. Further validation in larger cohorts is needed for haemorrhagic stroke.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025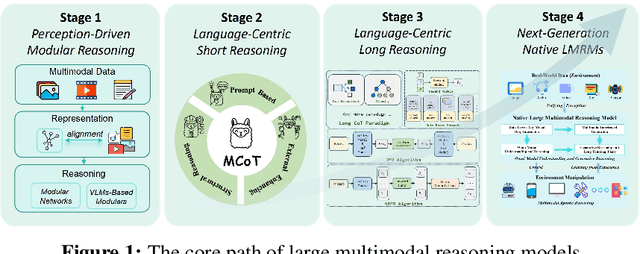
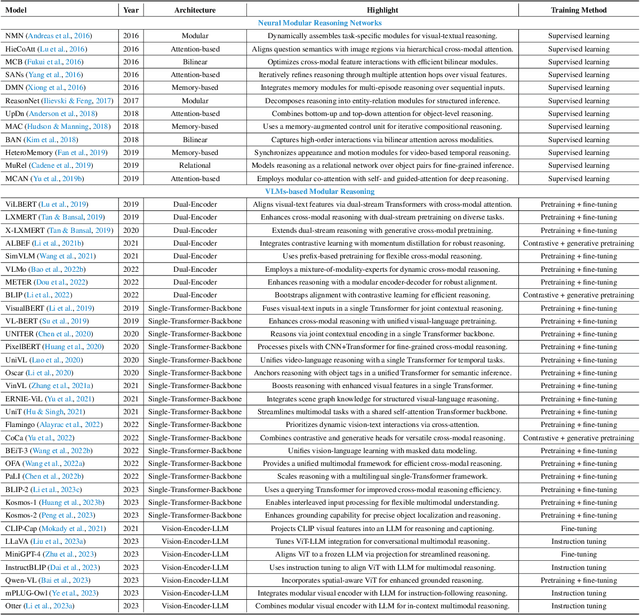
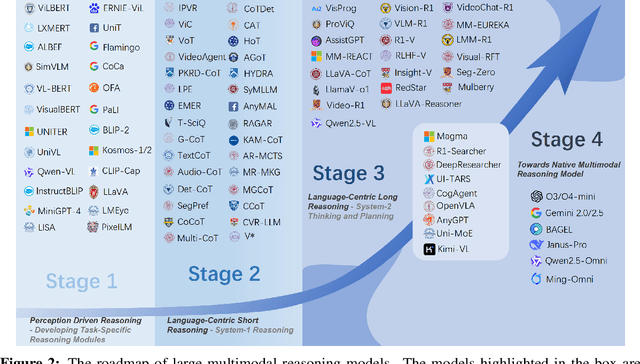
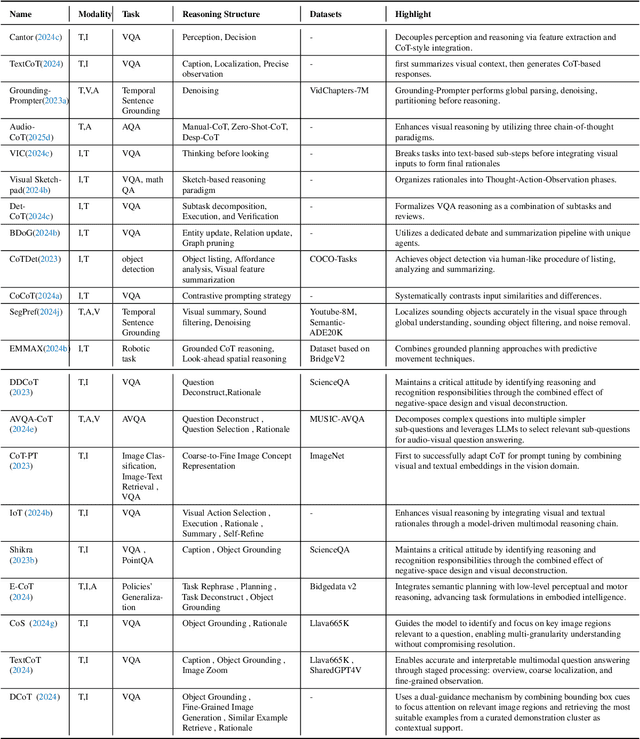
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
A Unified Agentic Framework for Evaluating Conditional Image Generation
Apr 09, 2025Conditional image generation has gained significant attention for its ability to personalize content. However, the field faces challenges in developing task-agnostic, reliable, and explainable evaluation metrics. This paper introduces CIGEval, a unified agentic framework for comprehensive evaluation of conditional image generation tasks. CIGEval utilizes large multimodal models (LMMs) as its core, integrating a multi-functional toolbox and establishing a fine-grained evaluation framework. Additionally, we synthesize evaluation trajectories for fine-tuning, empowering smaller LMMs to autonomously select appropriate tools and conduct nuanced analyses based on tool outputs. Experiments across seven prominent conditional image generation tasks demonstrate that CIGEval (GPT-4o version) achieves a high correlation of 0.4625 with human assessments, closely matching the inter-annotator correlation of 0.47. Moreover, when implemented with 7B open-source LMMs using only 2.3K training trajectories, CIGEval surpasses the previous GPT-4o-based state-of-the-art method. Case studies on GPT-4o image generation highlight CIGEval's capability in identifying subtle issues related to subject consistency and adherence to control guidance, indicating its great potential for automating evaluation of image generation tasks with human-level reliability.
Towards Reasoning in Large Language Models via Multi-Agent Peer Review Collaboration
Nov 14, 2023



Large Language Models (LLMs) have shown remarkable capabilities in general natural language processing tasks but often fall short in complex reasoning tasks. Recent studies have explored human-like problem-solving strategies, such as self-correct, to push further the boundary of single-model reasoning ability. In this work, we let a single model "step outside the box" by engaging multiple models to correct each other. We introduce a multi-agent collaboration strategy that emulates the academic peer review process. Each agent independently constructs its own solution, provides reviews on the solutions of others, and assigns confidence levels to its reviews. Upon receiving peer reviews, agents revise their initial solutions. Extensive experiments on three different types of reasoning tasks show that our collaboration approach delivers superior accuracy across all ten datasets compared to existing methods. Further study demonstrates the effectiveness of integrating confidence in the reviews for math reasoning, and suggests a promising direction for human-mimicking multi-agent collaboration process.
A Read-and-Select Framework for Zero-shot Entity Linking
Oct 29, 2023
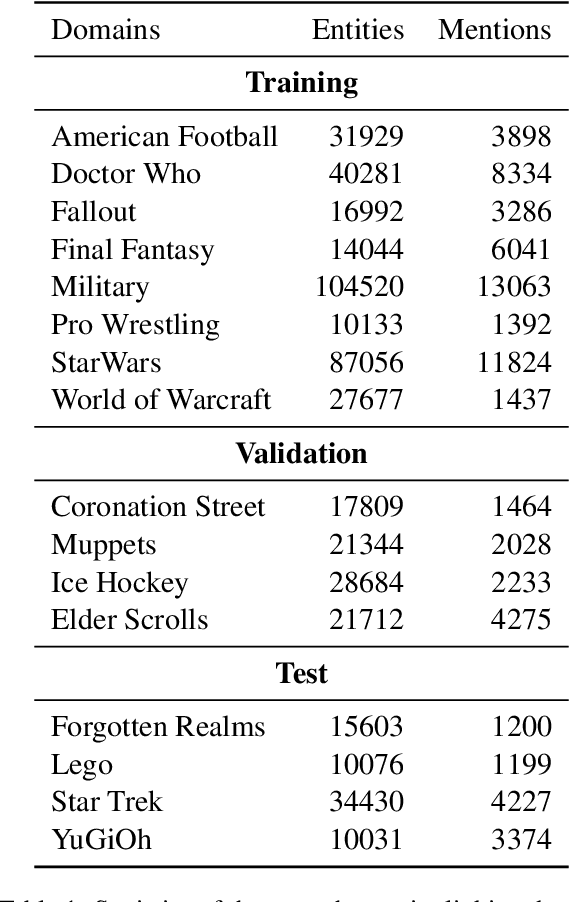

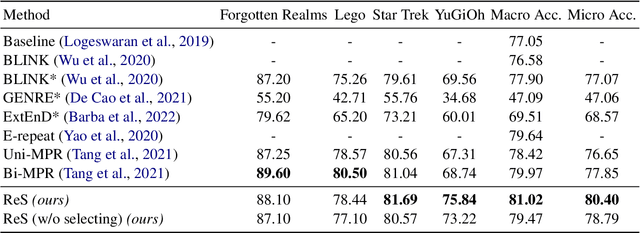
Zero-shot entity linking (EL) aims at aligning entity mentions to unseen entities to challenge the generalization ability. Previous methods largely focus on the candidate retrieval stage and ignore the essential candidate ranking stage, which disambiguates among entities and makes the final linking prediction. In this paper, we propose a read-and-select (ReS) framework by modeling the main components of entity disambiguation, i.e., mention-entity matching and cross-entity comparison. First, for each candidate, the reading module leverages mention context to output mention-aware entity representations, enabling mention-entity matching. Then, in the selecting module, we frame the choice of candidates as a sequence labeling problem, and all candidate representations are fused together to enable cross-entity comparison. Our method achieves the state-of-the-art performance on the established zero-shot EL dataset ZESHEL with a 2.55% micro-average accuracy gain, with no need for laborious multi-phase pre-training used in most of the previous work, showing the effectiveness of both mention-entity and cross-entity interaction.
Revisiting Sparse Retrieval for Few-shot Entity Linking
Oct 19, 2023Entity linking aims to link ambiguous mentions to their corresponding entities in a knowledge base. One of the key challenges comes from insufficient labeled data for specific domains. Although dense retrievers have achieved excellent performance on several benchmarks, their performance decreases significantly when only a limited amount of in-domain labeled data is available. In such few-shot setting, we revisit the sparse retrieval method, and propose an ELECTRA-based keyword extractor to denoise the mention context and construct a better query expression. For training the extractor, we propose a distant supervision method to automatically generate training data based on overlapping tokens between mention contexts and entity descriptions. Experimental results on the ZESHEL dataset demonstrate that the proposed method outperforms state-of-the-art models by a significant margin across all test domains, showing the effectiveness of keyword-enhanced sparse retrieval.