 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
Nov 16, 2025We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee's Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.
Johnson-Lindenstrauss Lemma Guided Network for Efficient 3D Medical Segmentation
Sep 26, 2025Lightweight 3D medical image segmentation remains constrained by a fundamental "efficiency / robustness conflict", particularly when processing complex anatomical structures and heterogeneous modalities. In this paper, we study how to redesign the framework based on the characteristics of high-dimensional 3D images, and explore data synergy to overcome the fragile representation of lightweight methods. Our approach, VeloxSeg, begins with a deployable and extensible dual-stream CNN-Transformer architecture composed of Paired Window Attention (PWA) and Johnson-Lindenstrauss lemma-guided convolution (JLC). For each 3D image, we invoke a "glance-and-focus" principle, where PWA rapidly retrieves multi-scale information, and JLC ensures robust local feature extraction with minimal parameters, significantly enhancing the model's ability to operate with low computational budget. Followed by an extension of the dual-stream architecture that incorporates modal interaction into the multi-scale image-retrieval process, VeloxSeg efficiently models heterogeneous modalities. Finally, Spatially Decoupled Knowledge Transfer (SDKT) via Gram matrices injects the texture prior extracted by a self-supervised network into the segmentation network, yielding stronger representations than baselines at no extra inference cost. Experimental results on multimodal benchmarks show that VeloxSeg achieves a 26% Dice improvement, alongside increasing GPU throughput by 11x and CPU by 48x. Codes are available at https://github.com/JinPLu/VeloxSeg.
AniMaker: Automated Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation
Jun 12, 2025Despite rapid advancements in video generation models, generating coherent storytelling videos that span multiple scenes and characters remains challenging. Current methods often rigidly convert pre-generated keyframes into fixed-length clips, resulting in disjointed narratives and pacing issues. Furthermore, the inherent instability of video generation models means that even a single low-quality clip can significantly degrade the entire output animation's logical coherence and visual continuity. To overcome these obstacles, we introduce AniMaker, a multi-agent framework enabling efficient multi-candidate clip generation and storytelling-aware clip selection, thus creating globally consistent and story-coherent animation solely from text input. The framework is structured around specialized agents, including the Director Agent for storyboard generation, the Photography Agent for video clip generation, the Reviewer Agent for evaluation, and the Post-Production Agent for editing and voiceover. Central to AniMaker's approach are two key technical components: MCTS-Gen in Photography Agent, an efficient Monte Carlo Tree Search (MCTS)-inspired strategy that intelligently navigates the candidate space to generate high-potential clips while optimizing resource usage; and AniEval in Reviewer Agent, the first framework specifically designed for multi-shot animation evaluation, which assesses critical aspects such as story-level consistency, action completion, and animation-specific features by considering each clip in the context of its preceding and succeeding clips. Experiments demonstrate that AniMaker achieves superior quality as measured by popular metrics including VBench and our proposed AniEval framework, while significantly improving the efficiency of multi-candidate generation, pushing AI-generated storytelling animation closer to production standards.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025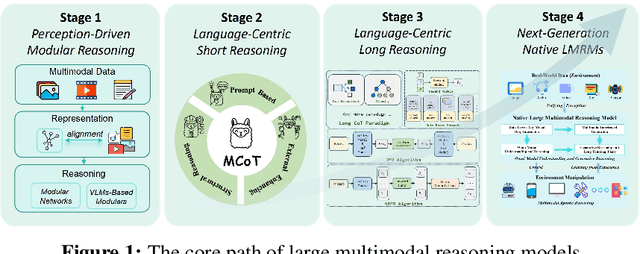
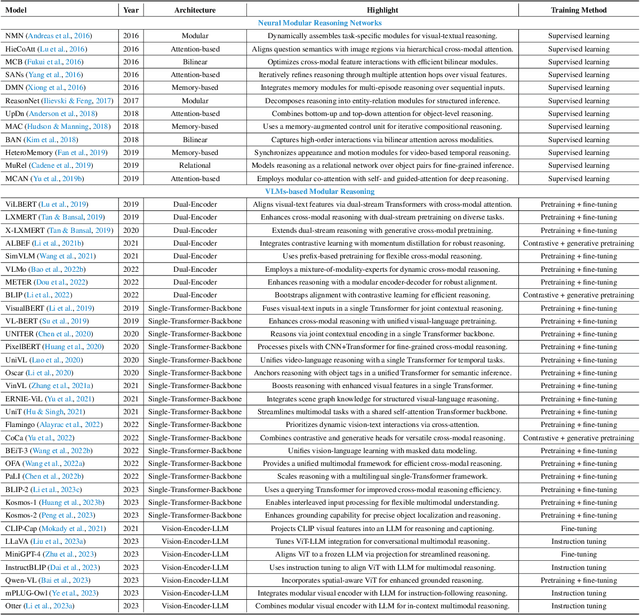
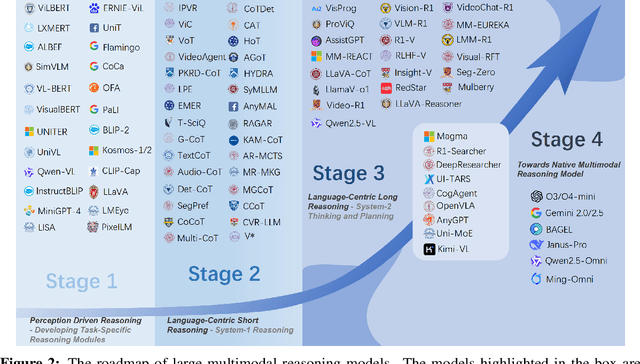
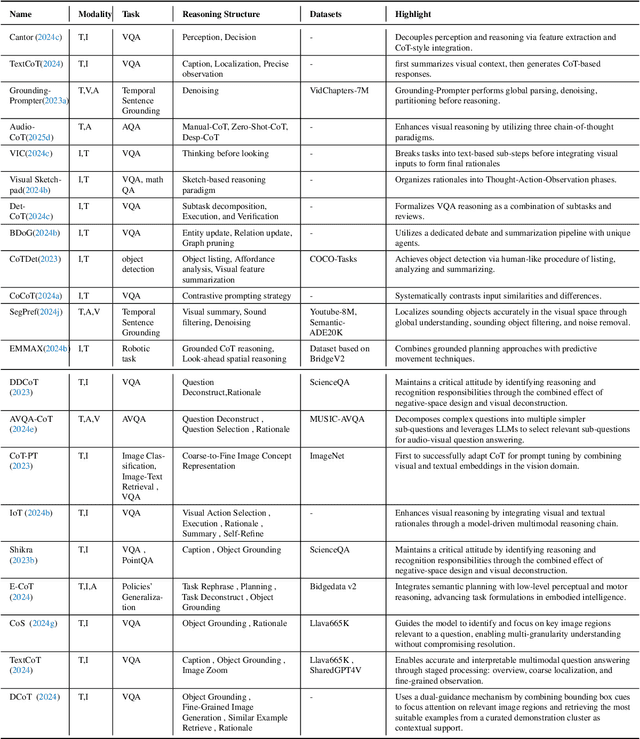
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
AI Awareness
Apr 25, 2025Recent breakthroughs in artificial intelligence (AI) have brought about increasingly capable systems that demonstrate remarkable abilities in reasoning, language understanding, and problem-solving. These advancements have prompted a renewed examination of AI awareness, not as a philosophical question of consciousness, but as a measurable, functional capacity. In this review, we explore the emerging landscape of AI awareness, which includes meta-cognition (the ability to represent and reason about its own state), self-awareness (recognizing its own identity, knowledge, limitations, inter alia), social awareness (modeling the knowledge, intentions, and behaviors of other agents), and situational awareness (assessing and responding to the context in which it operates). First, we draw on insights from cognitive science, psychology, and computational theory to trace the theoretical foundations of awareness and examine how the four distinct forms of AI awareness manifest in state-of-the-art AI. Next, we systematically analyze current evaluation methods and empirical findings to better understand these manifestations. Building on this, we explore how AI awareness is closely linked to AI capabilities, demonstrating that more aware AI agents tend to exhibit higher levels of intelligent behaviors. Finally, we discuss the risks associated with AI awareness, including key topics in AI safety, alignment, and broader ethical concerns. AI awareness is a double-edged sword: it improves general capabilities, i.e., reasoning, safety, while also raises concerns around misalignment and societal risks, demanding careful oversight as AI capabilities grow. On the whole, our interdisciplinary review provides a roadmap for future research and aims to clarify the role of AI awareness in the ongoing development of intelligent machines.
VideoVista-CulturalLingo: 360$^\circ$ Horizons-Bridging Cultures, Languages, and Domains in Video Comprehension
Apr 23, 2025Assessing the video comprehension capabilities of multimodal AI systems can effectively measure their understanding and reasoning abilities. Most video evaluation benchmarks are limited to a single language, typically English, and predominantly feature videos rooted in Western cultural contexts. In this paper, we present VideoVista-CulturalLingo, the first video evaluation benchmark designed to bridge cultural, linguistic, and domain divide in video comprehension. Our work differs from existing benchmarks in the following ways: 1) Cultural diversity, incorporating cultures from China, North America, and Europe; 2) Multi-linguistics, with questions presented in Chinese and English-two of the most widely spoken languages; and 3) Broad domain, featuring videos sourced from hundreds of human-created domains. VideoVista-CulturalLingo contains 1,389 videos and 3,134 QA pairs, and we have evaluated 24 recent open-source or proprietary video large models. From the experiment results, we observe that: 1) Existing models perform worse on Chinese-centric questions than Western-centric ones, particularly those related to Chinese history; 2) Current open-source models still exhibit limitations in temporal understanding, especially in the Event Localization task, achieving a maximum score of only 45.2%; 3) Mainstream models demonstrate strong performance in general scientific questions, while open-source models demonstrate weak performance in mathematics.
CSHNet: A Novel Information Asymmetric Image Translation Method
Jan 17, 2025



Despite advancements in cross-domain image translation, challenges persist in asymmetric tasks such as SAR-to-Optical and Sketch-to-Instance conversions, which involve transforming data from a less detailed domain into one with richer content. Traditional CNN-based methods are effective at capturing fine details but struggle with global structure, leading to unwanted merging of image regions. To address this, we propose the CNN-Swin Hybrid Network (CSHNet), which combines two key modules: Swin Embedded CNN (SEC) and CNN Embedded Swin (CES), forming the SEC-CES-Bottleneck (SCB). SEC leverages CNN's detailed feature extraction while integrating the Swin Transformer's structural bias. CES, in turn, preserves the Swin Transformer's global integrity, compensating for CNN's lack of focus on structure. Additionally, CSHNet includes two components designed to enhance cross-domain information retention: the Interactive Guided Connection (IGC), which enables dynamic information exchange between SEC and CES, and Adaptive Edge Perception Loss (AEPL), which maintains structural boundaries during translation. Experimental results show that CSHNet outperforms existing methods in both visual quality and performance metrics across scene-level and instance-level datasets. Our code is available at: https://github.com/XduShi/CSHNet.
Controllable Edge-Type-Specific Interpretation in Multi-Relational Graph Neural Networks for Drug Response Prediction
Sep 03, 2024
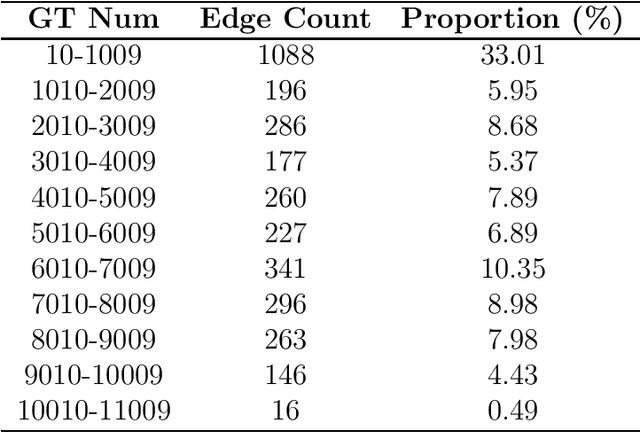
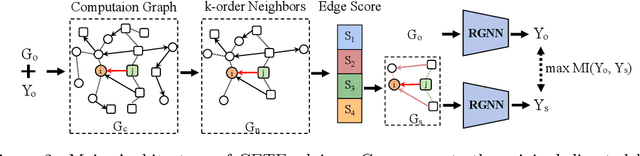
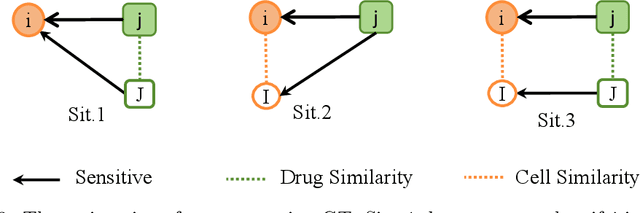
Graph Neural Networks have been widely applied in critical decision-making areas that demand interpretable predictions, leading to the flourishing development of interpretability algorithms. However, current graph interpretability algorithms tend to emphasize generality and often overlook biological significance, thereby limiting their applicability in predicting cancer drug responses. In this paper, we propose a novel post-hoc interpretability algorithm for cancer drug response prediction, CETExplainer, which incorporates a controllable edge-type-specific weighting mechanism. It considers the mutual information between subgraphs and predictions, proposing a structural scoring approach to provide fine-grained, biologically meaningful explanations for predictive models. We also introduce a method for constructing ground truth based on real-world datasets to quantitatively evaluate the proposed interpretability algorithm. Empirical analysis on the real-world dataset demonstrates that CETExplainer achieves superior stability and improves explanation quality compared to leading algorithms, thereby offering a robust and insightful tool for cancer drug prediction.
DRExplainer: Quantifiable Interpretability in Drug Response Prediction with Directed Graph Convolutional Network
Aug 22, 2024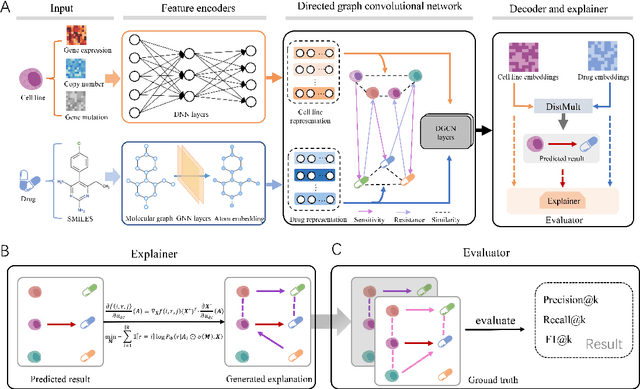
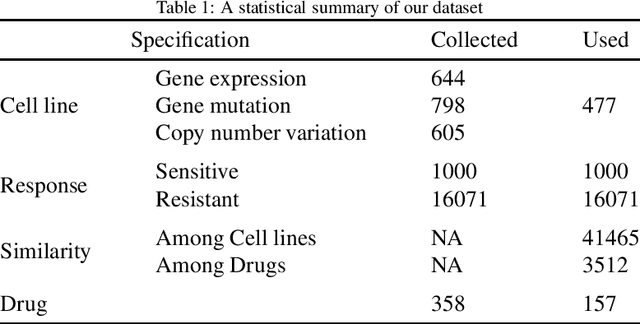
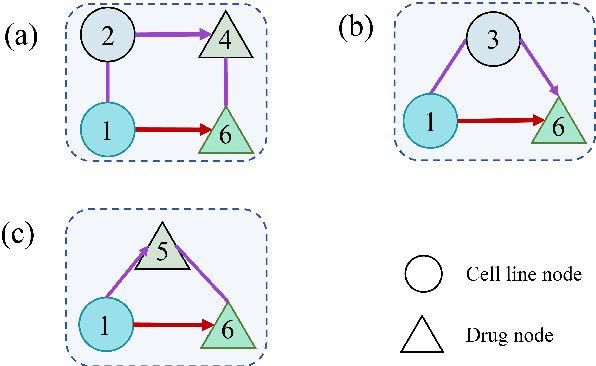

Predicting the response of a cancer cell line to a therapeutic drug is pivotal for personalized medicine. Despite numerous deep learning methods that have been developed for drug response prediction, integrating diverse information about biological entities and predicting the directional response remain major challenges. Here, we propose a novel interpretable predictive model, DRExplainer, which leverages a directed graph convolutional network to enhance the prediction in a directed bipartite network framework. DRExplainer constructs a directed bipartite network integrating multi-omics profiles of cell lines, the chemical structure of drugs and known drug response to achieve directed prediction. Then, DRExplainer identifies the most relevant subgraph to each prediction in this directed bipartite network by learning a mask, facilitating critical medical decision-making. Additionally, we introduce a quantifiable method for model interpretability that leverages a ground truth benchmark dataset curated from biological features. In computational experiments, DRExplainer outperforms state-of-the-art predictive methods and another graph-based explanation method under the same experimental setting. Finally, the case studies further validate the interpretability and the effectiveness of DRExplainer in predictive novel drug response. Our code is available at: https://github.com/vshy-dream/DRExplainer.
Anim-Director: A Large Multimodal Model Powered Agent for Controllable Animation Video Generation
Aug 19, 2024
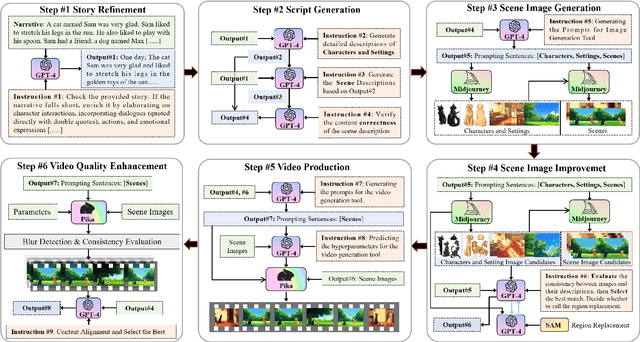

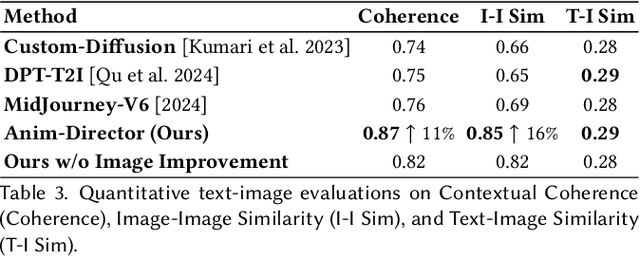
Traditional animation generation methods depend on training generative models with human-labelled data, entailing a sophisticated multi-stage pipeline that demands substantial human effort and incurs high training costs. Due to limited prompting plans, these methods typically produce brief, information-poor, and context-incoherent animations. To overcome these limitations and automate the animation process, we pioneer the introduction of large multimodal models (LMMs) as the core processor to build an autonomous animation-making agent, named Anim-Director. This agent mainly harnesses the advanced understanding and reasoning capabilities of LMMs and generative AI tools to create animated videos from concise narratives or simple instructions. Specifically, it operates in three main stages: Firstly, the Anim-Director generates a coherent storyline from user inputs, followed by a detailed director's script that encompasses settings of character profiles and interior/exterior descriptions, and context-coherent scene descriptions that include appearing characters, interiors or exteriors, and scene events. Secondly, we employ LMMs with the image generation tool to produce visual images of settings and scenes. These images are designed to maintain visual consistency across different scenes using a visual-language prompting method that combines scene descriptions and images of the appearing character and setting. Thirdly, scene images serve as the foundation for producing animated videos, with LMMs generating prompts to guide this process. The whole process is notably autonomous without manual intervention, as the LMMs interact seamlessly with generative tools to generate prompts, evaluate visual quality, and select the best one to optimize the final output.