 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Physical Transformer
Jan 05, 2026Digital AI systems spanning large language models, vision models, and generative architectures that operate primarily in symbolic, linguistic, or pixel domains. They have achieved striking progress, but almost all of this progress lives in virtual spaces. These systems transform embeddings and tokens, yet do not themselves touch the world and rarely admit a physical interpretation. In this work we propose a physical transformer that couples modern transformer style computation with geometric representation and physical dynamics. At the micro level, attention heads, and feed-forward blocks are modeled as interacting spins governed by effective Hamiltonians plus non-Hamiltonian bath terms. At the meso level, their aggregated state evolves on a learned Neural Differential Manifold (NDM) under Hamiltonian flows and Hamilton, Jacobi, Bellman (HJB) optimal control, discretized by symplectic layers that approximately preserve geometric and energetic invariants. At the macro level, the model maintains a generative semantic workspace and a two-dimensional information-phase portrait that tracks uncertainty and information gain over a reasoning trajectory. Within this hierarchy, reasoning tasks are formulated as controlled information flows on the manifold, with solutions corresponding to low cost trajectories that satisfy geometric, energetic, and workspace-consistency constraints. On simple toy problems involving numerical integration and dynamical systems, the physical transformer outperforms naive baselines in stability and long-horizon accuracy, highlighting the benefits of respecting underlying geometric and Hamiltonian structure. More broadly, the framework suggests a path toward physical AI that unify digital reasoning with physically grounded manifolds, opening a route to more interpretable and potentially unified models of reasoning, control, and interaction with the real world.
Generating Transferrable Adversarial Examples via Local Mixing and Logits Optimization for Remote Sensing Object Recognition
Sep 09, 2025Deep Neural Networks (DNNs) are vulnerable to adversarial attacks, posing significant security threats to their deployment in remote sensing applications. Research on adversarial attacks not only reveals model vulnerabilities but also provides critical insights for enhancing robustness. Although current mixing-based strategies have been proposed to increase the transferability of adversarial examples, they either perform global blending or directly exchange a region in the images, which may destroy global semantic features and mislead the optimization of adversarial examples. Furthermore, their reliance on cross-entropy loss for perturbation optimization leads to gradient diminishing during iterative updates, compromising adversarial example quality. To address these limitations, we focus on non-targeted attacks and propose a novel framework via local mixing and logits optimization. First, we present a local mixing strategy to generate diverse yet semantically consistent inputs. Different from MixUp, which globally blends two images, and MixCut, which stitches images together, our method merely blends local regions to preserve global semantic information. Second, we adapt the logit loss from targeted attacks to non-targeted scenarios, mitigating the gradient vanishing problem of cross-entropy loss. Third, a perturbation smoothing loss is applied to suppress high-frequency noise and enhance transferability. Extensive experiments on FGSCR-42 and MTARSI datasets demonstrate superior performance over 12 state-of-the-art methods across 6 surrogate models. Notably, with ResNet as the surrogate on MTARSI, our method achieves a 17.28% average improvement in black-box attack success rate.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
Adaptive Wavelet Filters as Practical Texture Feature Amplifiers for Parkinson's Disease Screening in OCT
Mar 25, 2025Parkinson's disease (PD) is a prevalent neurodegenerative disorder globally. The eye's retina is an extension of the brain and has great potential in PD screening. Recent studies have suggested that texture features extracted from retinal layers can be adopted as biomarkers for PD diagnosis under optical coherence tomography (OCT) images. Frequency domain learning techniques can enhance the feature representations of deep neural networks (DNNs) by decomposing frequency components involving rich texture features. Additionally, previous works have not exploited texture features for automated PD screening in OCT. Motivated by the above analysis, we propose a novel Adaptive Wavelet Filter (AWF) that serves as the Practical Texture Feature Amplifier to fully leverage the merits of texture features to boost the PD screening performance of DNNs with the aid of frequency domain learning. Specifically, AWF first enhances texture feature representation diversities via channel mixer, then emphasizes informative texture feature representations with the well-designed adaptive wavelet filtering token mixer. By combining the AWFs with the DNN stem, AWFNet is constructed for automated PD screening. Additionally, we introduce a novel Balanced Confidence (BC) Loss by mining the potential of sample-wise predicted probabilities of all classes and class frequency prior, to further boost the PD screening performance and trustworthiness of AWFNet. The extensive experiments manifest the superiority of our AWFNet and BC over state-of-the-art methods in terms of PD screening performance and trustworthiness.
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
Jan 16, 2025



Visual tokenization via auto-encoding empowers state-of-the-art image and video generative models by compressing pixels into a latent space. Although scaling Transformer-based generators has been central to recent advances, the tokenizer component itself is rarely scaled, leaving open questions about how auto-encoder design choices influence both its objective of reconstruction and downstream generative performance. Our work aims to conduct an exploration of scaling in auto-encoders to fill in this blank. To facilitate this exploration, we replace the typical convolutional backbone with an enhanced Vision Transformer architecture for Tokenization (ViTok). We train ViTok on large-scale image and video datasets far exceeding ImageNet-1K, removing data constraints on tokenizer scaling. We first study how scaling the auto-encoder bottleneck affects both reconstruction and generation -- and find that while it is highly correlated with reconstruction, its relationship with generation is more complex. We next explored the effect of separately scaling the auto-encoders' encoder and decoder on reconstruction and generation performance. Crucially, we find that scaling the encoder yields minimal gains for either reconstruction or generation, while scaling the decoder boosts reconstruction but the benefits for generation are mixed. Building on our exploration, we design ViTok as a lightweight auto-encoder that achieves competitive performance with state-of-the-art auto-encoders on ImageNet-1K and COCO reconstruction tasks (256p and 512p) while outperforming existing auto-encoders on 16-frame 128p video reconstruction for UCF-101, all with 2-5x fewer FLOPs. When integrated with Diffusion Transformers, ViTok demonstrates competitive performance on image generation for ImageNet-1K and sets new state-of-the-art benchmarks for class-conditional video generation on UCF-101.
LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity
Dec 13, 2024



Text-to-video generation enhances content creation but is highly computationally intensive: The computational cost of Diffusion Transformers (DiTs) scales quadratically in the number of pixels. This makes minute-length video generation extremely expensive, limiting most existing models to generating videos of only 10-20 seconds length. We propose a Linear-complexity text-to-video Generation (LinGen) framework whose cost scales linearly in the number of pixels. For the first time, LinGen enables high-resolution minute-length video generation on a single GPU without compromising quality. It replaces the computationally-dominant and quadratic-complexity block, self-attention, with a linear-complexity block called MATE, which consists of an MA-branch and a TE-branch. The MA-branch targets short-to-long-range correlations, combining a bidirectional Mamba2 block with our token rearrangement method, Rotary Major Scan, and our review tokens developed for long video generation. The TE-branch is a novel TEmporal Swin Attention block that focuses on temporal correlations between adjacent tokens and medium-range tokens. The MATE block addresses the adjacency preservation issue of Mamba and improves the consistency of generated videos significantly. Experimental results show that LinGen outperforms DiT (with a 75.6% win rate) in video quality with up to 15$\times$ (11.5$\times$) FLOPs (latency) reduction. Furthermore, both automatic metrics and human evaluation demonstrate our LinGen-4B yields comparable video quality to state-of-the-art models (with a 50.5%, 52.1%, 49.1% win rate with respect to Gen-3, LumaLabs, and Kling, respectively). This paves the way to hour-length movie generation and real-time interactive video generation. We provide 68s video generation results and more examples in our project website: https://lineargen.github.io/.
Reject Threshold Adaptation for Open-Set Model Attribution of Deepfake Audio
Dec 02, 2024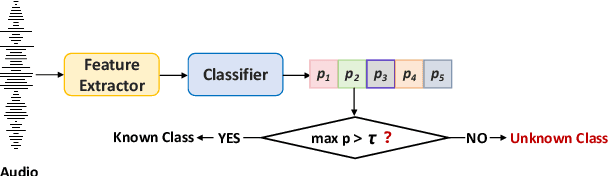

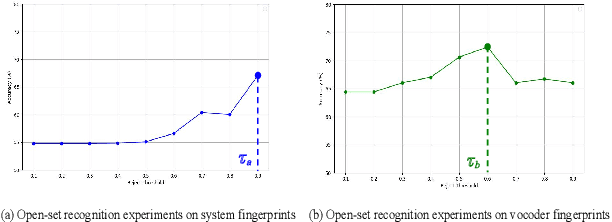

Open environment oriented open set model attribution of deepfake audio is an emerging research topic, aiming to identify the generation models of deepfake audio. Most previous work requires manually setting a rejection threshold for unknown classes to compare with predicted probabilities. However, models often overfit training instances and generate overly confident predictions. Moreover, thresholds that effectively distinguish unknown categories in the current dataset may not be suitable for identifying known and unknown categories in another data distribution. To address the issues, we propose a novel framework for open set model attribution of deepfake audio with rejection threshold adaptation (ReTA). Specifically, the reconstruction error learning module trains by combining the representation of system fingerprints with labels corresponding to either the target class or a randomly chosen other class label. This process generates matching and non-matching reconstructed samples, establishing the reconstruction error distributions for each class and laying the foundation for the reject threshold calculation module. The reject threshold calculation module utilizes gaussian probability estimation to fit the distributions of matching and non-matching reconstruction errors. It then computes adaptive reject thresholds for all classes through probability minimization criteria. The experimental results demonstrate the effectiveness of ReTA in improving the open set model attributes of deepfake audio.
Smart Predict-then-Optimize Method with Dependent Data: Risk Bounds and Calibration of Autoregression
Nov 19, 2024The predict-then-optimize (PTO) framework is indispensable for addressing practical stochastic decision-making tasks. It consists of two crucial steps: initially predicting unknown parameters of an optimization model and subsequently solving the problem based on these predictions. Elmachtoub and Grigas [1] introduced the Smart Predict-then-Optimize (SPO) loss for the framework, which gauges the decision error arising from predicted parameters, and a convex surrogate, the SPO+ loss, which incorporates the underlying structure of the optimization model. The consistency of these different loss functions is guaranteed under the assumption of i.i.d. training data. Nevertheless, various types of data are often dependent, such as power load fluctuations over time. This dependent nature can lead to diminished model performance in testing or real-world applications. Motivated to make intelligent predictions for time series data, we present an autoregressive SPO method directly targeting the optimization problem at the decision stage in this paper, where the conditions of consistency are no longer met. Therefore, we first analyze the generalization bounds of the SPO loss within our autoregressive model. Subsequently, the uniform calibration results in Liu and Grigas [2] are extended in the proposed model. Finally, we conduct experiments to empirically demonstrate the effectiveness of the SPO+ surrogate compared to the absolute loss and the least squares loss, especially when the cost vectors are determined by stationary dynamical systems and demonstrate the relationship between normalized regret and mixing coefficients.