 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Air to Wear: Personalized 3D Digital Fashion with AR/VR Immersive 3D Sketching
May 15, 2025In the era of immersive consumer electronics, such as AR/VR headsets and smart devices, people increasingly seek ways to express their identity through virtual fashion. However, existing 3D garment design tools remain inaccessible to everyday users due to steep technical barriers and limited data. In this work, we introduce a 3D sketch-driven 3D garment generation framework that empowers ordinary users - even those without design experience - to create high-quality digital clothing through simple 3D sketches in AR/VR environments. By combining a conditional diffusion model, a sketch encoder trained in a shared latent space, and an adaptive curriculum learning strategy, our system interprets imprecise, free-hand input and produces realistic, personalized garments. To address the scarcity of training data, we also introduce KO3DClothes, a new dataset of paired 3D garments and user-created sketches. Extensive experiments and user studies confirm that our method significantly outperforms existing baselines in both fidelity and usability, demonstrating its promise for democratized fashion design on next-generation consumer platforms.
Syllables to Scenes: Literary-Guided Free-Viewpoint 3D Scene Synthesis from Japanese Haiku
Feb 17, 2025In the era of the metaverse, where immersive technologies redefine human experiences, translating abstract literary concepts into navigable 3D environments presents a fundamental challenge in preserving semantic and emotional fidelity. This research introduces HaikuVerse, a novel framework for transforming poetic abstraction into spatial representation, with Japanese Haiku serving as an ideal test case due to its sophisticated encapsulation of profound emotions and imagery within minimal text. While existing text-to-3D methods struggle with nuanced interpretations, we present a literary-guided approach that synergizes traditional poetry analysis with advanced generative technologies. Our framework centers on two key innovations: (1) Hierarchical Literary-Criticism Theory Grounded Parsing (H-LCTGP), which captures both explicit imagery and implicit emotional resonance through structured semantic decomposition, and (2) Progressive Dimensional Synthesis (PDS), a multi-stage pipeline that systematically transforms poetic elements into coherent 3D scenes through sequential diffusion processes, geometric optimization, and real-time enhancement. Extensive experiments demonstrate that HaikuVerse significantly outperforms conventional text-to-3D approaches in both literary fidelity and visual quality, establishing a new paradigm for preserving cultural heritage in immersive digital spaces. Project website at: https://syllables-to-scenes.github.io/
Img2CAD: Conditioned 3D CAD Model Generation from Single Image with Structured Visual Geometry
Oct 04, 2024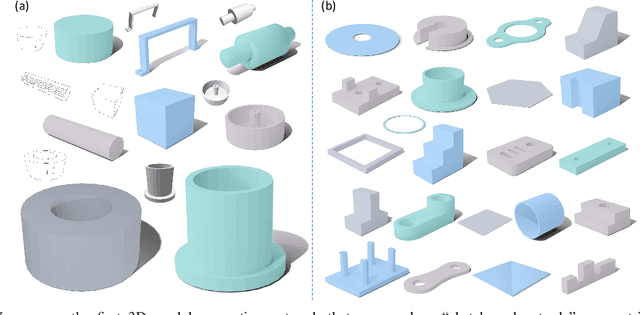
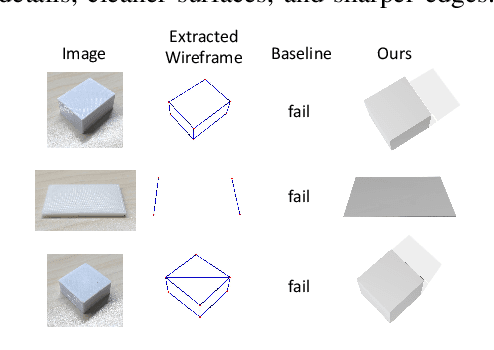


In this paper, we propose Img2CAD, the first approach to our knowledge that uses 2D image inputs to generate CAD models with editable parameters. Unlike existing AI methods for 3D model generation using text or image inputs often rely on mesh-based representations, which are incompatible with CAD tools and lack editability and fine control, Img2CAD enables seamless integration between AI-based 3D reconstruction and CAD software. We have identified an innovative intermediate representation called Structured Visual Geometry (SVG), characterized by vectorized wireframes extracted from objects. This representation significantly enhances the performance of generating conditioned CAD models. Additionally, we introduce two new datasets to further support research in this area: ABC-mono, the largest known dataset comprising over 200,000 3D CAD models with rendered images, and KOCAD, the first dataset featuring real-world captured objects alongside their ground truth CAD models, supporting further research in conditioned CAD model generation.
SAM2-Adapter: Evaluating & Adapting Segment Anything 2 in Downstream Tasks: Camouflage, Shadow, Medical Image Segmentation, and More
Aug 08, 2024The advent of large models, also known as foundation models, has significantly transformed the AI research landscape, with models like Segment Anything (SAM) achieving notable success in diverse image segmentation scenarios. Despite its advancements, SAM encountered limitations in handling some complex low-level segmentation tasks like camouflaged object and medical imaging. In response, in 2023, we introduced SAM-Adapter, which demonstrated improved performance on these challenging tasks. Now, with the release of Segment Anything 2 (SAM2), a successor with enhanced architecture and a larger training corpus, we reassess these challenges. This paper introduces SAM2-Adapter, the first adapter designed to overcome the persistent limitations observed in SAM2 and achieve new state-of-the-art (SOTA) results in specific downstream tasks including medical image segmentation, camouflaged (concealed) object detection, and shadow detection. SAM2-Adapter builds on the SAM-Adapter's strengths, offering enhanced generalizability and composability for diverse applications. We present extensive experimental results demonstrating SAM2-Adapter's effectiveness. We show the potential and encourage the research community to leverage the SAM2 model with our SAM2-Adapter for achieving superior segmentation outcomes. Code, pre-trained models, and data processing protocols are available at http://tianrun-chen.github.io/SAM-Adaptor/
Reasoning3D -- Grounding and Reasoning in 3D: Fine-Grained Zero-Shot Open-Vocabulary 3D Reasoning Part Segmentation via Large Vision-Language Models
May 29, 2024In this paper, we introduce a new task: Zero-Shot 3D Reasoning Segmentation for parts searching and localization for objects, which is a new paradigm to 3D segmentation that transcends limitations for previous category-specific 3D semantic segmentation, 3D instance segmentation, and open-vocabulary 3D segmentation. We design a simple baseline method, Reasoning3D, with the capability to understand and execute complex commands for (fine-grained) segmenting specific parts for 3D meshes with contextual awareness and reasoned answers for interactive segmentation. Specifically, Reasoning3D leverages an off-the-shelf pre-trained 2D segmentation network, powered by Large Language Models (LLMs), to interpret user input queries in a zero-shot manner. Previous research have shown that extensive pre-training endows foundation models with prior world knowledge, enabling them to comprehend complex commands, a capability we can harness to "segment anything" in 3D with limited 3D datasets (source efficient). Experimentation reveals that our approach is generalizable and can effectively localize and highlight parts of 3D objects (in 3D mesh) based on implicit textual queries, including these articulated 3d objects and real-world scanned data. Our method can also generate natural language explanations corresponding to these 3D models and the decomposition. Moreover, our training-free approach allows rapid deployment and serves as a viable universal baseline for future research of part-level 3d (semantic) object understanding in various fields including robotics, object manipulation, part assembly, autonomous driving applications, augment reality and virtual reality (AR/VR), and medical applications. The code, the model weight, the deployment guide, and the evaluation protocol are: http://tianrun-chen.github.io/Reason3D/