 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust 4D Visual Geometry Transformer with Uncertainty-Aware Priors
Apr 10, 2026Reconstructing dynamic 4D scenes is an important yet challenging task. While 3D foundation models like VGGT excel in static settings, they often struggle with dynamic sequences where motion causes significant geometric ambiguity. To address this, we present a framework designed to disentangle dynamic and static components by modeling uncertainty across different stages of the reconstruction process. Our approach introduces three synergistic mechanisms: (1) Entropy-Guided Subspace Projection, which leverages information-theoretic weighting to adaptively aggregate multi-head attention distributions, effectively isolating dynamic motion cues from semantic noise; (2) Local-Consistency Driven Geometry Purification, which enforces spatial continuity via radius-based neighborhood constraints to eliminate structural outliers; and (3) Uncertainty-Aware Cross-View Consistency, which formulates multi-view projection refinement as a heteroscedastic maximum likelihood estimation problem, utilizing depth confidence as a probabilistic weight. Experiments on dynamic benchmarks show that our approach outperforms current state-of-the-art methods, reducing Mean Accuracy error by 13.43\% and improving segmentation F-measure by 10.49\%. Our framework maintains the efficiency of feed-forward inference and requires no task-specific fine-tuning or per-scene optimization.
Seeing Eye to Eye: Enabling Cognitive Alignment Through Shared First-Person Perspective in Human-AI Collaboration
Mar 13, 2026Despite advances in multimodal AI, current vision-based assistants often remain inefficient in collaborative tasks. We identify two key gulfs: a communication gulf, where users must translate rich parallel intentions into verbal commands due to the channel mismatch , and an understanding gulf, where AI struggles to interpret subtle embodied cues. To address these, we propose Eye2Eye, a framework that leverages first-person perspective as a channel for human-AI cognitive alignment. It integrates three components: (1) joint attention coordination for fluid focus alignment, (2) revisable memory to maintain evolving common ground, and (3) reflective feedback allowing users to clarify and refine AI's understanding. We implement this framework in an AR prototype and evaluate it through a user study and a post-hoc pipeline evaluation. Results show that Eye2Eye significantly reduces task completion time and interaction load while increasing trust, demonstrating its components work in concert to improve collaboration.
Beyond Binary Preference: Aligning Diffusion Models to Fine-grained Criteria by Decoupling Attributes
Jan 07, 2026Post-training alignment of diffusion models relies on simplified signals, such as scalar rewards or binary preferences. This limits alignment with complex human expertise, which is hierarchical and fine-grained. To address this, we first construct a hierarchical, fine-grained evaluation criteria with domain experts, which decomposes image quality into multiple positive and negative attributes organized in a tree structure. Building on this, we propose a two-stage alignment framework. First, we inject domain knowledge to an auxiliary diffusion model via Supervised Fine-Tuning. Second, we introduce Complex Preference Optimization (CPO) that extends DPO to align the target diffusion to our non-binary, hierarchical criteria. Specifically, we reformulate the alignment problem to simultaneously maximize the probability of positive attributes while minimizing the probability of negative attributes with the auxiliary diffusion. We instantiate our approach in the domain of painting generation and conduct CPO training with an annotated dataset of painting with fine-grained attributes based on our criteria. Extensive experiments demonstrate that CPO significantly enhances generation quality and alignment with expertise, opening new avenues for fine-grained criteria alignment.
Learning to Hear by Seeing: It's Time for Vision Language Models to Understand Artistic Emotion from Sight and Sound
Nov 15, 2025Emotion understanding is critical for making Large Language Models (LLMs) more general, reliable, and aligned with humans. Art conveys emotion through the joint design of visual and auditory elements, yet most prior work is human-centered or single-modality, overlooking the emotion intentionally expressed by the artwork. Meanwhile, current Audio-Visual Language Models (AVLMs) typically require large-scale audio pretraining to endow Visual Language Models (VLMs) with hearing, which limits scalability. We present Vision Anchored Audio-Visual Emotion LLM (VAEmotionLLM), a two-stage framework that teaches a VLM to hear by seeing with limited audio pretraining and to understand emotion across modalities. In Stage 1, Vision-Guided Audio Alignment (VG-Align) distills the frozen visual pathway into a new audio pathway by aligning next-token distributions of the shared LLM on synchronized audio-video clips, enabling hearing without a large audio dataset. In Stage 2, a lightweight Cross-Modal Emotion Adapter (EmoAdapter), composed of the Emotion Enhancer and the Emotion Supervisor, injects emotion-sensitive residuals and applies emotion supervision to enhance cross-modal emotion understanding. We also construct ArtEmoBenchmark, an art-centric emotion benchmark that evaluates content and emotion understanding under audio-only, visual-only, and audio-visual inputs. VAEmotionLLM achieves state-of-the-art results on ArtEmoBenchmark, outperforming audio-only, visual-only, and audio-visual baselines. Ablations show that the proposed components are complementary.
Driver Assistant: Persuading Drivers to Adjust Secondary Tasks Using Large Language Models
Aug 07, 2025Level 3 automated driving systems allows drivers to engage in secondary tasks while diminishing their perception of risk. In the event of an emergency necessitating driver intervention, the system will alert the driver with a limited window for reaction and imposing a substantial cognitive burden. To address this challenge, this study employs a Large Language Model (LLM) to assist drivers in maintaining an appropriate attention on road conditions through a "humanized" persuasive advice. Our tool leverages the road conditions encountered by Level 3 systems as triggers, proactively steering driver behavior via both visual and auditory routes. Empirical study indicates that our tool is effective in sustaining driver attention with reduced cognitive load and coordinating secondary tasks with takeover behavior. Our work provides insights into the potential of using LLMs to support drivers during multi-task automated driving.
Controllable Video-to-Music Generation with Multiple Time-Varying Conditions
Jul 28, 2025Music enhances video narratives and emotions, driving demand for automatic video-to-music (V2M) generation. However, existing V2M methods relying solely on visual features or supplementary textual inputs generate music in a black-box manner, often failing to meet user expectations. To address this challenge, we propose a novel multi-condition guided V2M generation framework that incorporates multiple time-varying conditions for enhanced control over music generation. Our method uses a two-stage training strategy that enables learning of V2M fundamentals and audiovisual temporal synchronization while meeting users' needs for multi-condition control. In the first stage, we introduce a fine-grained feature selection module and a progressive temporal alignment attention mechanism to ensure flexible feature alignment. For the second stage, we develop a dynamic conditional fusion module and a control-guided decoder module to integrate multiple conditions and accurately guide the music composition process. Extensive experiments demonstrate that our method outperforms existing V2M pipelines in both subjective and objective evaluations, significantly enhancing control and alignment with user expectations.
Diffusion Distillation With Direct Preference Optimization For Efficient 3D LiDAR Scene Completion
Apr 16, 2025The application of diffusion models in 3D LiDAR scene completion is limited due to diffusion's slow sampling speed. Score distillation accelerates diffusion sampling but with performance degradation, while post-training with direct policy optimization (DPO) boosts performance using preference data. This paper proposes Distillation-DPO, a novel diffusion distillation framework for LiDAR scene completion with preference aligment. First, the student model generates paired completion scenes with different initial noises. Second, using LiDAR scene evaluation metrics as preference, we construct winning and losing sample pairs. Such construction is reasonable, since most LiDAR scene metrics are informative but non-differentiable to be optimized directly. Third, Distillation-DPO optimizes the student model by exploiting the difference in score functions between the teacher and student models on the paired completion scenes. Such procedure is repeated until convergence. Extensive experiments demonstrate that, compared to state-of-the-art LiDAR scene completion diffusion models, Distillation-DPO achieves higher-quality scene completion while accelerating the completion speed by more than 5-fold. Our method is the first to explore adopting preference learning in distillation to the best of our knowledge and provide insights into preference-aligned distillation. Our code is public available on https://github.com/happyw1nd/DistillationDPO.
Integrating Sequence and Image Modeling in Irregular Medical Time Series Through Self-Supervised Learning
Feb 10, 2025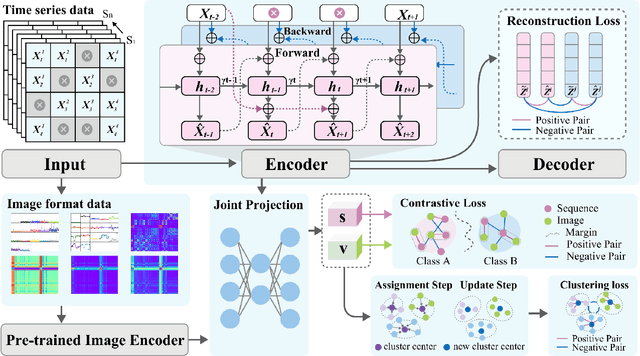
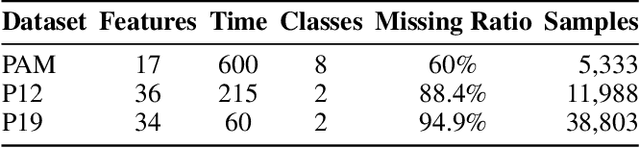
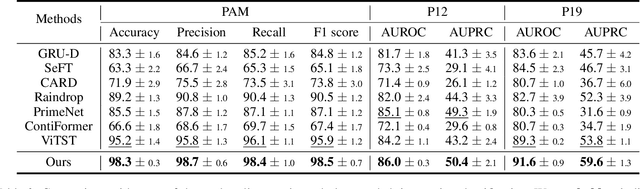
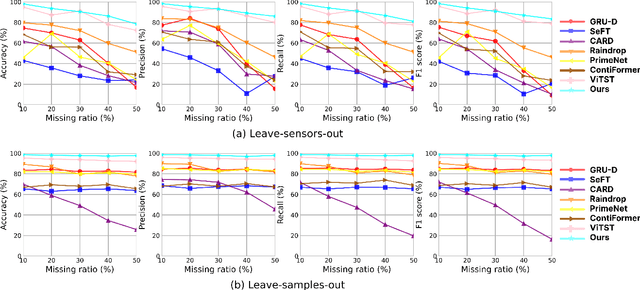
Medical time series are often irregular and face significant missingness, posing challenges for data analysis and clinical decision-making. Existing methods typically adopt a single modeling perspective, either treating series data as sequences or transforming them into image representations for further classification. In this paper, we propose a joint learning framework that incorporates both sequence and image representations. We also design three self-supervised learning strategies to facilitate the fusion of sequence and image representations, capturing a more generalizable joint representation. The results indicate that our approach outperforms seven other state-of-the-art models in three representative real-world clinical datasets. We further validate our approach by simulating two major types of real-world missingness through leave-sensors-out and leave-samples-out techniques. The results demonstrate that our approach is more robust and significantly surpasses other baselines in terms of classification performance.
GVMGen: A General Video-to-Music Generation Model with Hierarchical Attentions
Jan 17, 2025Composing music for video is essential yet challenging, leading to a growing interest in automating music generation for video applications. Existing approaches often struggle to achieve robust music-video correspondence and generative diversity, primarily due to inadequate feature alignment methods and insufficient datasets. In this study, we present General Video-to-Music Generation model (GVMGen), designed for generating high-related music to the video input. Our model employs hierarchical attentions to extract and align video features with music in both spatial and temporal dimensions, ensuring the preservation of pertinent features while minimizing redundancy. Remarkably, our method is versatile, capable of generating multi-style music from different video inputs, even in zero-shot scenarios. We also propose an evaluation model along with two novel objective metrics for assessing video-music alignment. Additionally, we have compiled a large-scale dataset comprising diverse types of video-music pairs. Experimental results demonstrate that GVMGen surpasses previous models in terms of music-video correspondence, generative diversity, and application universality.
Personalized Dynamic Music Emotion Recognition with Dual-Scale Attention-Based Meta-Learning
Dec 26, 2024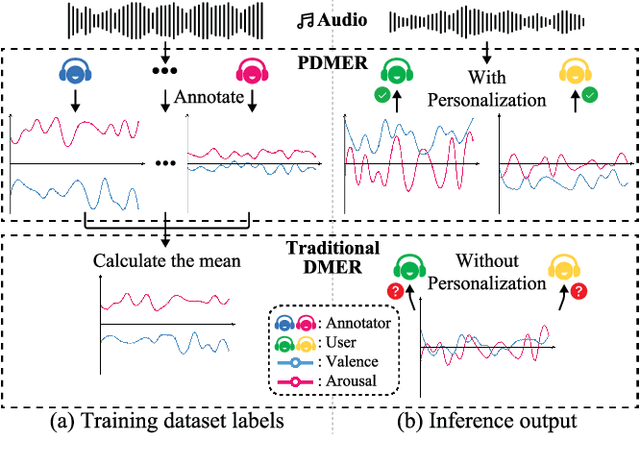
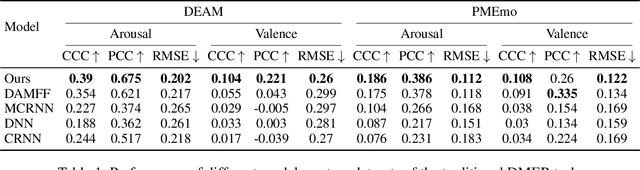
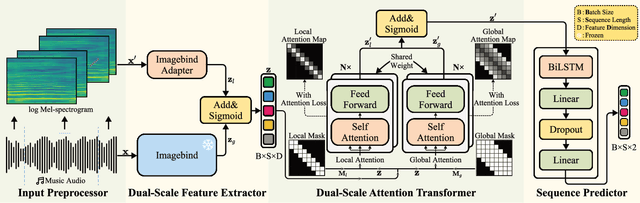
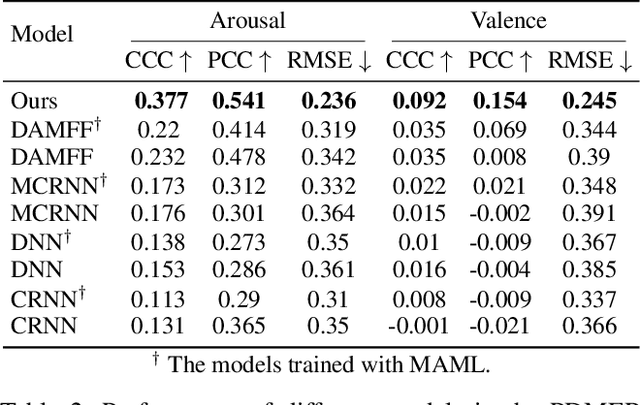
Dynamic Music Emotion Recognition (DMER) aims to predict the emotion of different moments in music, playing a crucial role in music information retrieval. The existing DMER methods struggle to capture long-term dependencies when dealing with sequence data, which limits their performance. Furthermore, these methods often overlook the influence of individual differences on emotion perception, even though everyone has their own personalized emotional perception in the real world. Motivated by these issues, we explore more effective sequence processing methods and introduce the Personalized DMER (PDMER) problem, which requires models to predict emotions that align with personalized perception. Specifically, we propose a Dual-Scale Attention-Based Meta-Learning (DSAML) method. This method fuses features from a dual-scale feature extractor and captures both short and long-term dependencies using a dual-scale attention transformer, improving the performance in traditional DMER. To achieve PDMER, we design a novel task construction strategy that divides tasks by annotators. Samples in a task are annotated by the same annotator, ensuring consistent perception. Leveraging this strategy alongside meta-learning, DSAML can predict personalized perception of emotions with just one personalized annotation sample. Our objective and subjective experiments demonstrate that our method can achieve state-of-the-art performance in both traditional DMER and PDMER.