 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE-Bench: Task-Aware and Diagnostic Evaluation of Tool-Integrated Reasoning
May 10, 2026Tool-integrated reasoning has emerged as a promising paradigm for enhancing large language models with external computation, retrieval, and execution capabilities. However, the field still lacks a high-quality and unified evaluation benchmark, and existing TIR evaluations remain limited in dataset quality, task diversity, diagnostic comprehensiveness, and evaluation efficiency. In this work, we introduce TIDE-Bench, a holistic and efficient benchmark for evaluating TIR methods, featuring three key advantages. First, it provides diverse task settings, combining widely used mathematical reasoning and knowledge-intensive QA tasks with two newly designed tasks, namely the tool-grounded experimental design task and the dynamic interactive task, to probe models' abilities in complex tool invocation and multi-tool coordination. Second, TIDE-Bench adopts a comprehensive yet task-aware evaluation protocol, jointly measuring final answer quality, process reliability, tool-use efficiency, and inference cost across heterogeneous task settings. Third, TIDE-Bench constructs high-quality and discriminative evaluation sets by filtering low-discrimination instances from existing datasets, substantially reducing evaluation cost while focusing on more challenging samples. Extensive experiments on multiple foundation models and TIR methods reveal persistent bottlenecks in tool grounding, offering insights for future TIR research.
Beyond Binary Preference: Aligning Diffusion Models to Fine-grained Criteria by Decoupling Attributes
Jan 07, 2026Post-training alignment of diffusion models relies on simplified signals, such as scalar rewards or binary preferences. This limits alignment with complex human expertise, which is hierarchical and fine-grained. To address this, we first construct a hierarchical, fine-grained evaluation criteria with domain experts, which decomposes image quality into multiple positive and negative attributes organized in a tree structure. Building on this, we propose a two-stage alignment framework. First, we inject domain knowledge to an auxiliary diffusion model via Supervised Fine-Tuning. Second, we introduce Complex Preference Optimization (CPO) that extends DPO to align the target diffusion to our non-binary, hierarchical criteria. Specifically, we reformulate the alignment problem to simultaneously maximize the probability of positive attributes while minimizing the probability of negative attributes with the auxiliary diffusion. We instantiate our approach in the domain of painting generation and conduct CPO training with an annotated dataset of painting with fine-grained attributes based on our criteria. Extensive experiments demonstrate that CPO significantly enhances generation quality and alignment with expertise, opening new avenues for fine-grained criteria alignment.
Token Reduction Should Go Beyond Efficiency in Generative Models -- From Vision, Language to Multimodality
May 23, 2025In Transformer architectures, tokens\textemdash discrete units derived from raw data\textemdash are formed by segmenting inputs into fixed-length chunks. Each token is then mapped to an embedding, enabling parallel attention computations while preserving the input's essential information. Due to the quadratic computational complexity of transformer self-attention mechanisms, token reduction has primarily been used as an efficiency strategy. This is especially true in single vision and language domains, where it helps balance computational costs, memory usage, and inference latency. Despite these advances, this paper argues that token reduction should transcend its traditional efficiency-oriented role in the era of large generative models. Instead, we position it as a fundamental principle in generative modeling, critically influencing both model architecture and broader applications. Specifically, we contend that across vision, language, and multimodal systems, token reduction can: (i) facilitate deeper multimodal integration and alignment, (ii) mitigate "overthinking" and hallucinations, (iii) maintain coherence over long inputs, and (iv) enhance training stability, etc. We reframe token reduction as more than an efficiency measure. By doing so, we outline promising future directions, including algorithm design, reinforcement learning-guided token reduction, token optimization for in-context learning, and broader ML and scientific domains. We highlight its potential to drive new model architectures and learning strategies that improve robustness, increase interpretability, and better align with the objectives of generative modeling.
HDCompression: Hybrid-Diffusion Image Compression for Ultra-Low Bitrates
Feb 11, 2025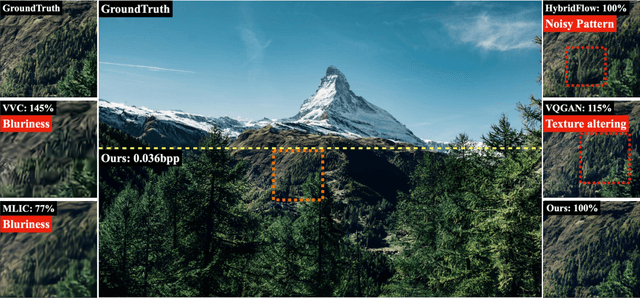
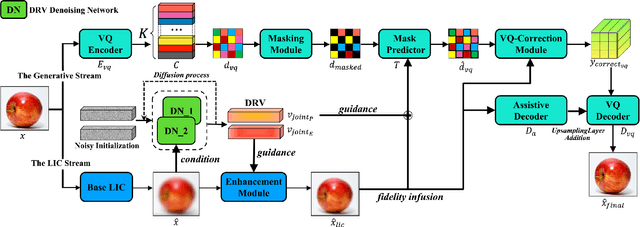
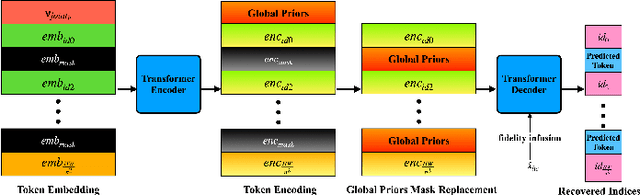
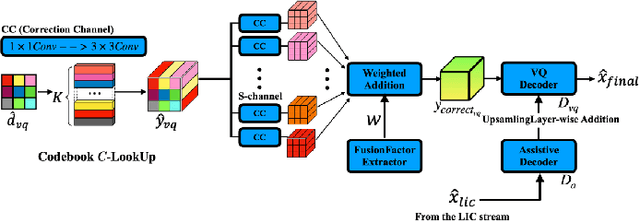
Image compression under ultra-low bitrates remains challenging for both conventional learned image compression (LIC) and generative vector-quantized (VQ) modeling. Conventional LIC suffers from severe artifacts due to heavy quantization, while generative VQ modeling gives poor fidelity due to the mismatch between learned generative priors and specific inputs. In this work, we propose Hybrid-Diffusion Image Compression (HDCompression), a dual-stream framework that utilizes both generative VQ-modeling and diffusion models, as well as conventional LIC, to achieve both high fidelity and high perceptual quality. Different from previous hybrid methods that directly use pre-trained LIC models to generate low-quality fidelity-preserving information from heavily quantized latent, we use diffusion models to extract high-quality complimentary fidelity information from the ground-truth input, which can enhance the system performance in several aspects: improving indices map prediction, enhancing the fidelity-preserving output of the LIC stream, and refining conditioned image reconstruction with VQ-latent correction. In addition, our diffusion model is based on a dense representative vector (DRV), which is lightweight with very simple sampling schedulers. Extensive experiments demonstrate that our HDCompression outperforms the previous conventional LIC, generative VQ-modeling, and hybrid frameworks in both quantitative metrics and qualitative visualization, providing balanced robust compression performance at ultra-low bitrates.
LAION-SG: An Enhanced Large-Scale Dataset for Training Complex Image-Text Models with Structural Annotations
Dec 11, 2024



Recent advances in text-to-image (T2I) generation have shown remarkable success in producing high-quality images from text. However, existing T2I models show decayed performance in compositional image generation involving multiple objects and intricate relationships. We attribute this problem to limitations in existing datasets of image-text pairs, which lack precise inter-object relationship annotations with prompts only. To address this problem, we construct LAION-SG, a large-scale dataset with high-quality structural annotations of scene graphs (SG), which precisely describe attributes and relationships of multiple objects, effectively representing the semantic structure in complex scenes. Based on LAION-SG, we train a new foundation model SDXL-SG to incorporate structural annotation information into the generation process. Extensive experiments show advanced models trained on our LAION-SG boast significant performance improvements in complex scene generation over models on existing datasets. We also introduce CompSG-Bench, a benchmark that evaluates models on compositional image generation, establishing a new standard for this domain.
Pruning then Reweighting: Towards Data-Efficient Training of Diffusion Models
Sep 27, 2024Despite the remarkable generation capabilities of Diffusion Models (DMs), conducting training and inference remains computationally expensive. Previous works have been devoted to accelerating diffusion sampling, but achieving data-efficient diffusion training has often been overlooked. In this work, we investigate efficient diffusion training from the perspective of dataset pruning. Inspired by the principles of data-efficient training for generative models such as generative adversarial networks (GANs), we first extend the data selection scheme used in GANs to DM training, where data features are encoded by a surrogate model, and a score criterion is then applied to select the coreset. To further improve the generation performance, we employ a class-wise reweighting approach, which derives class weights through distributionally robust optimization (DRO) over a pre-trained reference DM. For a pixel-wise DM (DDPM) on CIFAR-10, experiments demonstrate the superiority of our methodology over existing approaches and its effectiveness in image synthesis comparable to that of the original full-data model while achieving the speed-up between 2.34 times and 8.32 times. Additionally, our method could be generalized to latent DMs (LDMs), e.g., Masked Diffusion Transformer (MDT) and Stable Diffusion (SD), and achieves competitive generation capability on ImageNet.Code is available here (https://github.com/Yeez-lee/Data-Selection-and-Reweighting-for-Diffusion-Models).
Less is More: Data Pruning for Faster Adversarial Training
Feb 28, 2023Deep neural networks (DNNs) are sensitive to adversarial examples, resulting in fragile and unreliable performance in the real world. Although adversarial training (AT) is currently one of the most effective methodologies to robustify DNNs, it is computationally very expensive (e.g., 5-10X costlier than standard training). To address this challenge, existing approaches focus on single-step AT, referred to as Fast AT, reducing the overhead of adversarial example generation. Unfortunately, these approaches are known to fail against stronger adversaries. To make AT computationally efficient without compromising robustness, this paper takes a different view of the efficient AT problem. Specifically, we propose to minimize redundancies at the data level by leveraging data pruning. Extensive experiments demonstrate that the data pruning based AT can achieve similar or superior robust (and clean) accuracy as its unpruned counterparts while being significantly faster. For instance, proposed strategies accelerate CIFAR-10 training up to 3.44X and CIFAR-100 training to 2.02X. Additionally, the data pruning methods can readily be reconciled with existing adversarial acceleration tricks to obtain the striking speed-ups of 5.66X and 5.12X on CIFAR-10, 3.67X and 3.07X on CIFAR-100 with TRADES and MART, respectively.
Efficient Multi-Prize Lottery Tickets: Enhanced Accuracy, Training, and Inference Speed
Sep 26, 2022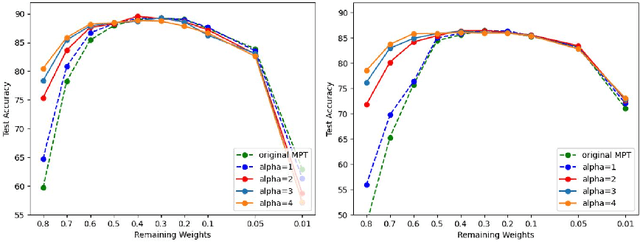
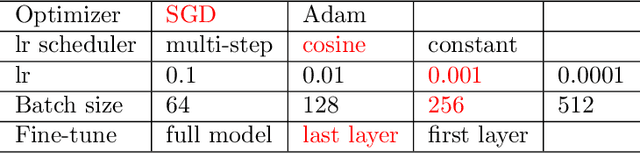


Recently, Diffenderfer and Kailkhura proposed a new paradigm for learning compact yet highly accurate binary neural networks simply by pruning and quantizing randomly weighted full precision neural networks. However, the accuracy of these multi-prize tickets (MPTs) is highly sensitive to the optimal prune ratio, which limits their applicability. Furthermore, the original implementation did not attain any training or inference speed benefits. In this report, we discuss several improvements to overcome these limitations. We show the benefit of the proposed techniques by performing experiments on CIFAR-10.
Reverse Engineering of Imperceptible Adversarial Image Perturbations
Apr 01, 2022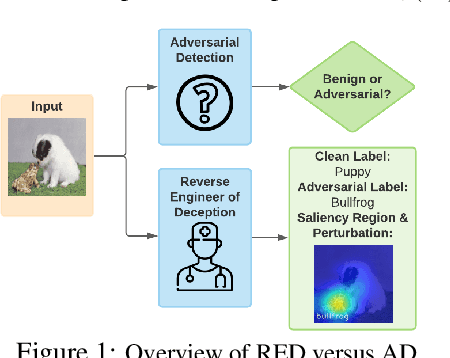
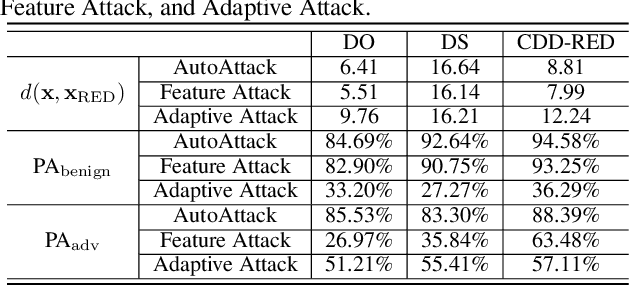
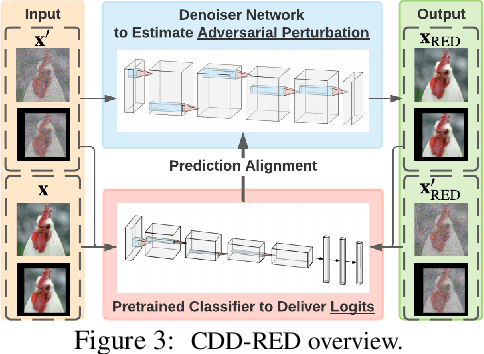
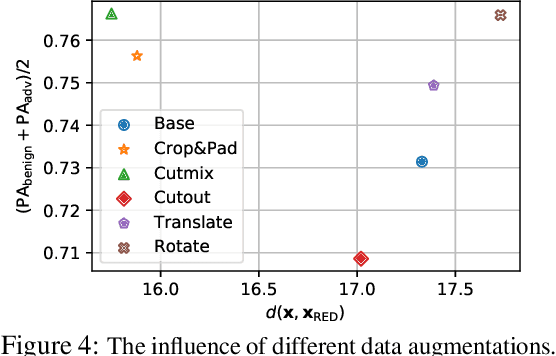
It has been well recognized that neural network based image classifiers are easily fooled by images with tiny perturbations crafted by an adversary. There has been a vast volume of research to generate and defend such adversarial attacks. However, the following problem is left unexplored: How to reverse-engineer adversarial perturbations from an adversarial image? This leads to a new adversarial learning paradigm--Reverse Engineering of Deceptions (RED). If successful, RED allows us to estimate adversarial perturbations and recover the original images. However, carefully crafted, tiny adversarial perturbations are difficult to recover by optimizing a unilateral RED objective. For example, the pure image denoising method may overfit to minimizing the reconstruction error but hardly preserve the classification properties of the true adversarial perturbations. To tackle this challenge, we formalize the RED problem and identify a set of principles crucial to the RED approach design. Particularly, we find that prediction alignment and proper data augmentation (in terms of spatial transformations) are two criteria to achieve a generalizable RED approach. By integrating these RED principles with image denoising, we propose a new Class-Discriminative Denoising based RED framework, termed CDD-RED. Extensive experiments demonstrate the effectiveness of CDD-RED under different evaluation metrics (ranging from the pixel-level, prediction-level to the attribution-level alignment) and a variety of attack generation methods (e.g., FGSM, PGD, CW, AutoAttack, and adaptive attacks).