 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Controllable Dynamic Top-p MoE for Large Foundation Model Pre-training
Dec 16, 2025Sparse Mixture-of-Experts (MoE) architectures effectively scale model capacity by activating only a subset of experts for each input token. However, the standard Top-k routing strategy imposes a uniform sparsity pattern that ignores the varying difficulty of tokens. While Top-p routing offers a flexible alternative, existing implementations typically rely on a fixed global probability threshold, which results in uncontrolled computational costs and sensitivity to hyperparameter selection. In this paper, we propose DTop-p MoE, a sparsity-controllable dynamic Top-p routing mechanism. To resolve the challenge of optimizing a non-differentiable threshold, we utilize a Proportional-Integral (PI) Controller that dynamically adjusts the probability threshold to align the running activated-expert sparsity with a specified target. Furthermore, we introduce a dynamic routing normalization mechanism that adapts layer-wise routing logits, allowing different layers to learn distinct expert-selection patterns while utilizing a global probability threshold. Extensive experiments on Large Language Models and Diffusion Transformers demonstrate that DTop-p consistently outperforms both Top-k and fixed-threshold Top-p baselines. Our analysis confirms that DTop-p maintains precise control over the number of activated experts while adaptively allocating resources across different tokens and layers. Furthermore, DTop-p exhibits strong scaling properties with respect to expert granularity, expert capacity, model size, and dataset size, offering a robust framework for large-scale MoE pre-training.
RECALL: REpresentation-aligned Catastrophic-forgetting ALLeviation via Hierarchical Model Merging
Oct 23, 2025We unveil that internal representations in large language models (LLMs) serve as reliable proxies of learned knowledge, and propose RECALL, a novel representation-aware model merging framework for continual learning without access to historical data. RECALL computes inter-model similarity from layer-wise hidden representations over clustered typical samples, and performs adaptive, hierarchical parameter fusion to align knowledge across models. This design enables the preservation of domain-general features in shallow layers while allowing task-specific adaptation in deeper layers. Unlike prior methods that require task labels or incur performance trade-offs, RECALL achieves seamless multi-domain integration and strong resistance to catastrophic forgetting. Extensive experiments across five NLP tasks and multiple continual learning scenarios show that RECALL outperforms baselines in both knowledge retention and generalization, providing a scalable and data-free solution for evolving LLMs.
Improving Practical Aspects of End-to-End Multi-Talker Speech Recognition for Online and Offline Scenarios
Jun 17, 2025We extend the frameworks of Serialized Output Training (SOT) to address practical needs of both streaming and offline automatic speech recognition (ASR) applications. Our approach focuses on balancing latency and accuracy, catering to real-time captioning and summarization requirements. We propose several key improvements: (1) Leveraging Continuous Speech Separation (CSS) single-channel front-end with end-to-end (E2E) systems for highly overlapping scenarios, challenging the conventional wisdom of E2E versus cascaded setups. The CSS framework improves the accuracy of the ASR system by separating overlapped speech from multiple speakers. (2) Implementing dual models -- Conformer Transducer for streaming and Sequence-to-Sequence for offline -- or alternatively, a two-pass model based on cascaded encoders. (3) Exploring segment-based SOT (segSOT) which is better suited for offline scenarios while also enhancing readability of multi-talker transcriptions.
Enabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Dec 17, 2024Diffusion Transformers have emerged as the preeminent models for a wide array of generative tasks, demonstrating superior performance and efficacy across various applications. The promising results come at the cost of slow inference, as each denoising step requires running the whole transformer model with a large amount of parameters. In this paper, we show that performing the full computation of the model at each diffusion step is unnecessary, as some computations can be skipped by lazily reusing the results of previous steps. Furthermore, we show that the lower bound of similarity between outputs at consecutive steps is notably high, and this similarity can be linearly approximated using the inputs. To verify our demonstrations, we propose the \textbf{LazyDiT}, a lazy learning framework that efficiently leverages cached results from earlier steps to skip redundant computations. Specifically, we incorporate lazy learning layers into the model, effectively trained to maximize laziness, enabling dynamic skipping of redundant computations. Experimental results show that LazyDiT outperforms the DDIM sampler across multiple diffusion transformer models at various resolutions. Furthermore, we implement our method on mobile devices, achieving better performance than DDIM with similar latency.
Fast and Memory-Efficient Video Diffusion Using Streamlined Inference
Nov 02, 2024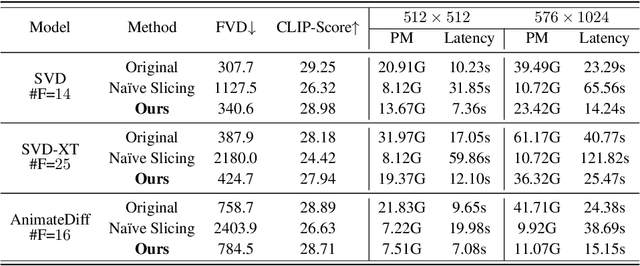
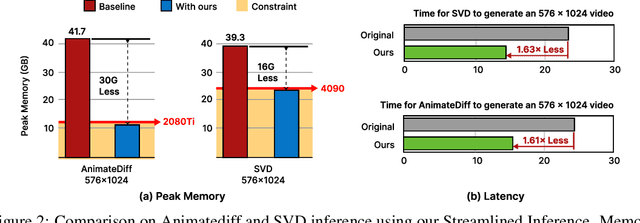

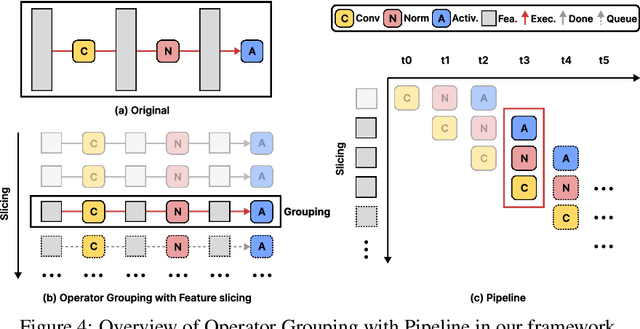
The rapid progress in artificial intelligence-generated content (AIGC), especially with diffusion models, has significantly advanced development of high-quality video generation. However, current video diffusion models exhibit demanding computational requirements and high peak memory usage, especially for generating longer and higher-resolution videos. These limitations greatly hinder the practical application of video diffusion models on standard hardware platforms. To tackle this issue, we present a novel, training-free framework named Streamlined Inference, which leverages the temporal and spatial properties of video diffusion models. Our approach integrates three core components: Feature Slicer, Operator Grouping, and Step Rehash. Specifically, Feature Slicer effectively partitions input features into sub-features and Operator Grouping processes each sub-feature with a group of consecutive operators, resulting in significant memory reduction without sacrificing the quality or speed. Step Rehash further exploits the similarity between adjacent steps in diffusion, and accelerates inference through skipping unnecessary steps. Extensive experiments demonstrate that our approach significantly reduces peak memory and computational overhead, making it feasible to generate high-quality videos on a single consumer GPU (e.g., reducing peak memory of AnimateDiff from 42GB to 11GB, featuring faster inference on 2080Ti).
Rethinking Token Reduction for State Space Models
Oct 16, 2024



Recent advancements in State Space Models (SSMs) have attracted significant interest, particularly in models optimized for parallel training and handling long-range dependencies. Architectures like Mamba have scaled to billions of parameters with selective SSM. To facilitate broader applications using Mamba, exploring its efficiency is crucial. While token reduction techniques offer a straightforward post-training strategy, we find that applying existing methods directly to SSMs leads to substantial performance drops. Through insightful analysis, we identify the reasons for this failure and the limitations of current techniques. In response, we propose a tailored, unified post-training token reduction method for SSMs. Our approach integrates token importance and similarity, thus taking advantage of both pruning and merging, to devise a fine-grained intra-layer token reduction strategy. Extensive experiments show that our method improves the average accuracy by 5.7% to 13.1% on six benchmarks with Mamba-2 compared to existing methods, while significantly reducing computational demands and memory requirements.
Exploring Token Pruning in Vision State Space Models
Sep 27, 2024



State Space Models (SSMs) have the advantage of keeping linear computational complexity compared to attention modules in transformers, and have been applied to vision tasks as a new type of powerful vision foundation model. Inspired by the observations that the final prediction in vision transformers (ViTs) is only based on a subset of most informative tokens, we take the novel step of enhancing the efficiency of SSM-based vision models through token-based pruning. However, direct applications of existing token pruning techniques designed for ViTs fail to deliver good performance, even with extensive fine-tuning. To address this issue, we revisit the unique computational characteristics of SSMs and discover that naive application disrupts the sequential token positions. This insight motivates us to design a novel and general token pruning method specifically for SSM-based vision models. We first introduce a pruning-aware hidden state alignment method to stabilize the neighborhood of remaining tokens for performance enhancement. Besides, based on our detailed analysis, we propose a token importance evaluation method adapted for SSM models, to guide the token pruning. With efficient implementation and practical acceleration methods, our method brings actual speedup. Extensive experiments demonstrate that our approach can achieve significant computation reduction with minimal impact on performance across different tasks. Notably, we achieve 81.7\% accuracy on ImageNet with a 41.6\% reduction in the FLOPs for pruned PlainMamba-L3. Furthermore, our work provides deeper insights into understanding the behavior of SSM-based vision models for future research.
Search for Efficient Large Language Models
Sep 25, 2024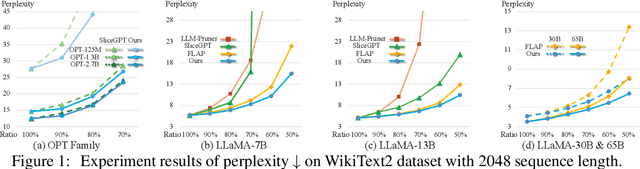
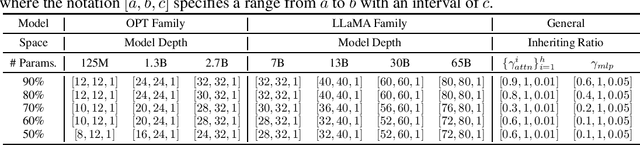
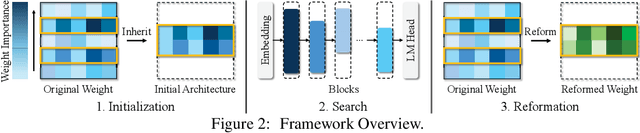
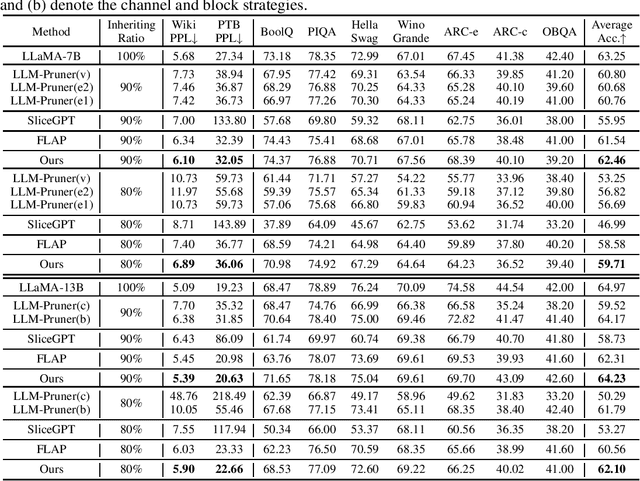
Large Language Models (LLMs) have long held sway in the realms of artificial intelligence research. Numerous efficient techniques, including weight pruning, quantization, and distillation, have been embraced to compress LLMs, targeting memory reduction and inference acceleration, which underscore the redundancy in LLMs. However, most model compression techniques concentrate on weight optimization, overlooking the exploration of optimal architectures. Besides, traditional architecture search methods, limited by the elevated complexity with extensive parameters, struggle to demonstrate their effectiveness on LLMs. In this paper, we propose a training-free architecture search framework to identify optimal subnets that preserve the fundamental strengths of the original LLMs while achieving inference acceleration. Furthermore, after generating subnets that inherit specific weights from the original LLMs, we introduce a reformation algorithm that utilizes the omitted weights to rectify the inherited weights with a small amount of calibration data. Compared with SOTA training-free structured pruning works that can generate smaller networks, our method demonstrates superior performance across standard benchmarks. Furthermore, our generated subnets can directly reduce the usage of GPU memory and achieve inference acceleration.
Efficient Training with Denoised Neural Weights
Jul 16, 2024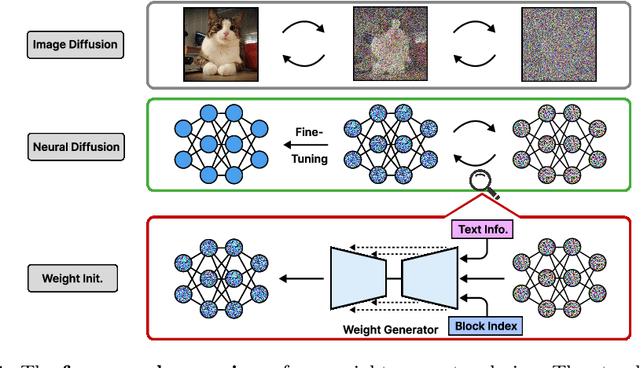
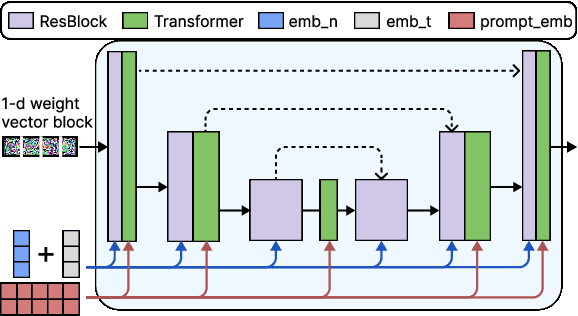
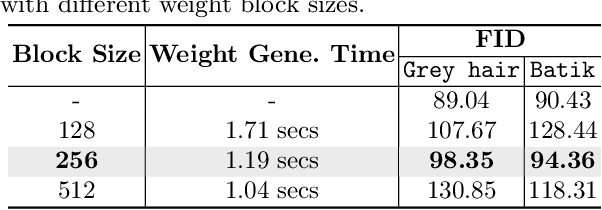
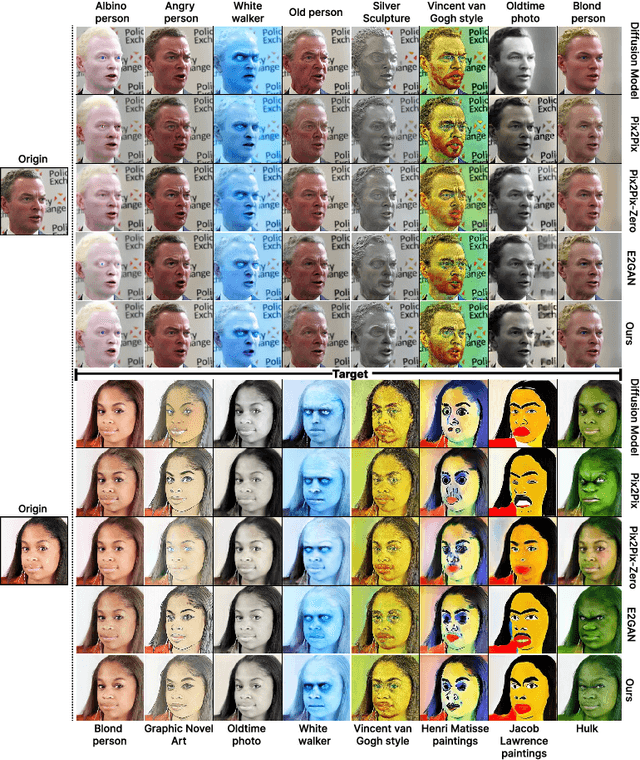
Good weight initialization serves as an effective measure to reduce the training cost of a deep neural network (DNN) model. The choice of how to initialize parameters is challenging and may require manual tuning, which can be time-consuming and prone to human error. To overcome such limitations, this work takes a novel step towards building a weight generator to synthesize the neural weights for initialization. We use the image-to-image translation task with generative adversarial networks (GANs) as an example due to the ease of collecting model weights spanning a wide range. Specifically, we first collect a dataset with various image editing concepts and their corresponding trained weights, which are later used for the training of the weight generator. To address the different characteristics among layers and the substantial number of weights to be predicted, we divide the weights into equal-sized blocks and assign each block an index. Subsequently, a diffusion model is trained with such a dataset using both text conditions of the concept and the block indexes. By initializing the image translation model with the denoised weights predicted by our diffusion model, the training requires only 43.3 seconds. Compared to training from scratch (i.e., Pix2pix), we achieve a 15x training time acceleration for a new concept while obtaining even better image generation quality.