 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
Paper and Code
Sep 14, 2023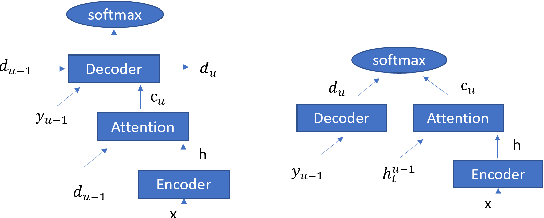
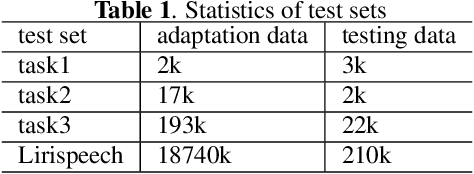
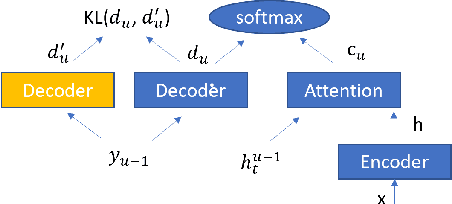
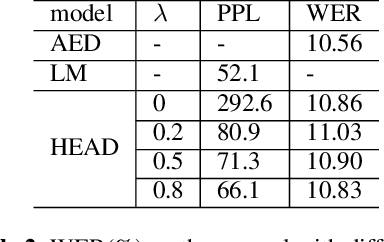
Attention-based encoder-decoder (AED) speech recognition model has been widely successful in recent years. However, the joint optimization of acoustic model and language model in end-to-end manner has created challenges for text adaptation. In particular, effectively, quickly and inexpensively adapting text has become a primary concern for deploying AED systems in industry. To address this issue, we propose a novel model, the hybrid attention-based encoder-decoder (HAED) speech recognition model that preserves the modularity of conventional hybrid automatic speech recognition systems. Our HAED model separates the acoustic and language models, allowing for the use of conventional text-based language model adaptation techniques. We demonstrate that the proposed HAED model yields 21\% Word Error Rate (WER) improvements in relative when out-of-domain text data is used for language model adaptation, and with only a minor degradation in WER on a general test set compared with conventional AED model.