 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Form Speech Recognition for General Speech In-Context Learning
Sep 29, 2024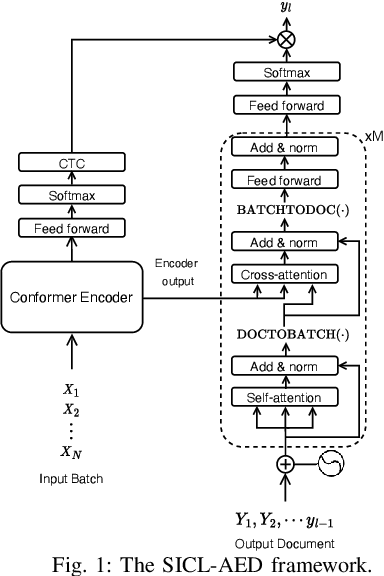
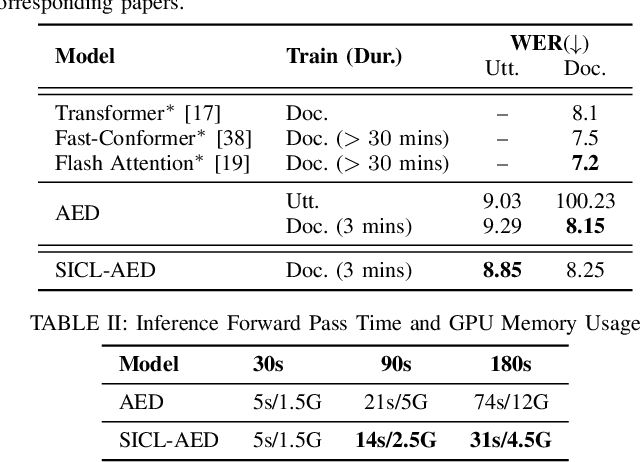
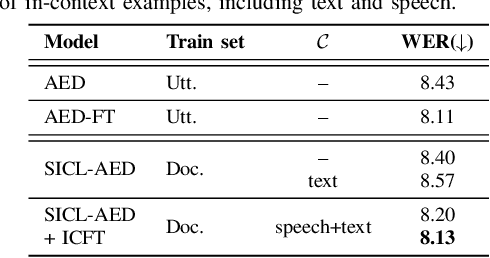
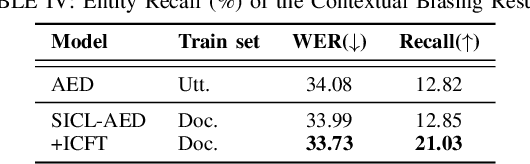
We propose a novel approach to end-to-end automatic speech recognition (ASR) to achieve efficient speech in-context learning (SICL) for (i) long-form speech decoding, (ii) test-time speaker adaptation, and (iii) test-time contextual biasing. Specifically, we introduce an attention-based encoder-decoder (AED) model with SICL capability (referred to as SICL-AED), where the decoder utilizes an utterance-level cross-attention to integrate information from the encoder's output efficiently, and a document-level self-attention to learn contextual information. Evaluated on the benchmark TEDLIUM3 dataset, SICL-AED achieves an 8.64% relative word error rate (WER) reduction compared to a baseline utterance-level AED model by leveraging previously decoded outputs as in-context examples. It also demonstrates comparable performance to conventional long-form AED systems with significantly reduced runtime and memory complexity. Additionally, we introduce an in-context fine-tuning (ICFT) technique that further enhances SICL effectiveness during inference. Experiments on speaker adaptation and contextual biasing highlight the general speech in-context learning capabilities of our system, achieving effective results with provided contexts. Without specific fine-tuning, SICL-AED matches the performance of supervised AED baselines for speaker adaptation and improves entity recall by 64% for contextual biasing task.
Hybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
Sep 14, 2023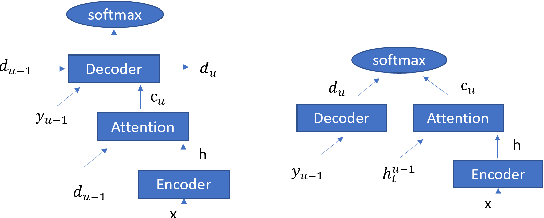
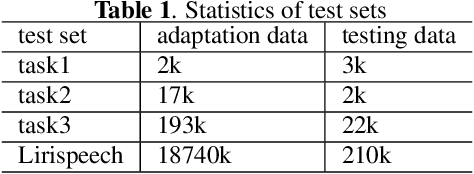
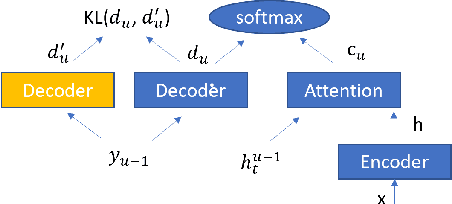
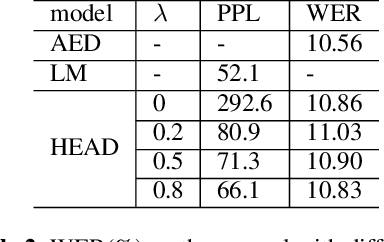
Attention-based encoder-decoder (AED) speech recognition model has been widely successful in recent years. However, the joint optimization of acoustic model and language model in end-to-end manner has created challenges for text adaptation. In particular, effectively, quickly and inexpensively adapting text has become a primary concern for deploying AED systems in industry. To address this issue, we propose a novel model, the hybrid attention-based encoder-decoder (HAED) speech recognition model that preserves the modularity of conventional hybrid automatic speech recognition systems. Our HAED model separates the acoustic and language models, allowing for the use of conventional text-based language model adaptation techniques. We demonstrate that the proposed HAED model yields 21\% Word Error Rate (WER) improvements in relative when out-of-domain text data is used for language model adaptation, and with only a minor degradation in WER on a general test set compared with conventional AED model.
Adapting Large Language Model with Speech for Fully Formatted End-to-End Speech Recognition
Aug 03, 2023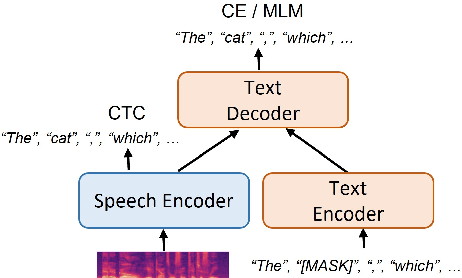
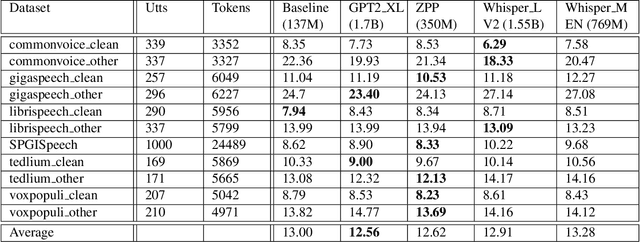
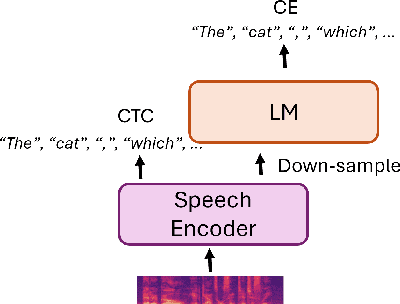
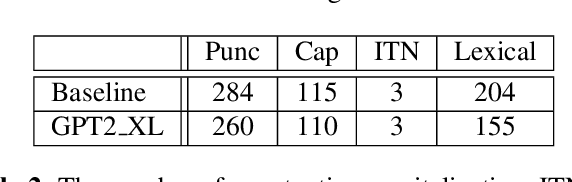
Most end-to-end (E2E) speech recognition models are composed of encoder and decoder blocks that perform acoustic and language modeling functions. Pretrained large language models (LLMs) have the potential to improve the performance of E2E ASR. However, integrating a pretrained language model into an E2E speech recognition model has shown limited benefits due to the mismatches between text-based LLMs and those used in E2E ASR. In this paper, we explore an alternative approach by adapting a pretrained LLMs to speech. Our experiments on fully-formatted E2E ASR transcription tasks across various domains demonstrate that our approach can effectively leverage the strengths of pretrained LLMs to produce more readable ASR transcriptions. Our model, which is based on the pretrained large language models with either an encoder-decoder or decoder-only structure, surpasses strong ASR models such as Whisper, in terms of recognition error rate, considering formats like punctuation and capitalization as well.
Improving Pseudo-label Training For End-to-end Speech Recognition Using Gradient Mask
Oct 08, 2021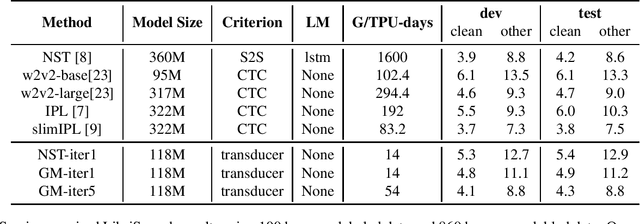
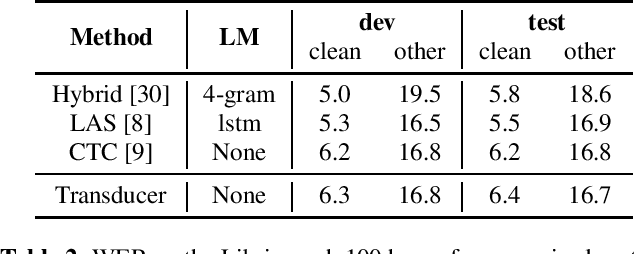
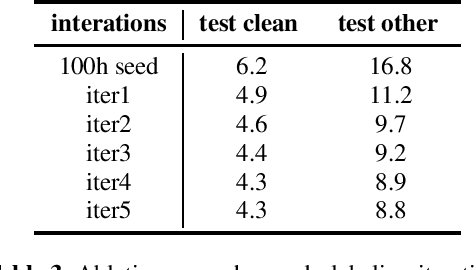
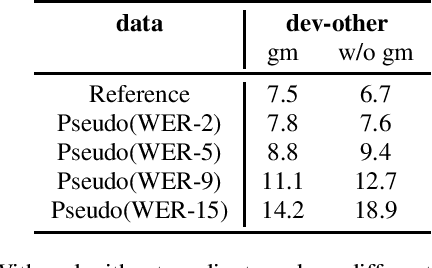
In the recent trend of semi-supervised speech recognition, both self-supervised representation learning and pseudo-labeling have shown promising results. In this paper, we propose a novel approach to combine their ideas for end-to-end speech recognition model. Without any extra loss function, we utilize the Gradient Mask to optimize the model when training on pseudo-label. This method forces the speech recognition model to predict from the masked input to learn strong acoustic representation and make training robust to label noise. In our semi-supervised experiments, the method can improve the model performance when training on pseudo-label and our method achieved competitive results comparing with other semi-supervised approaches on the Librispeech 100 hours experiments.
DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization
Dec 11, 2020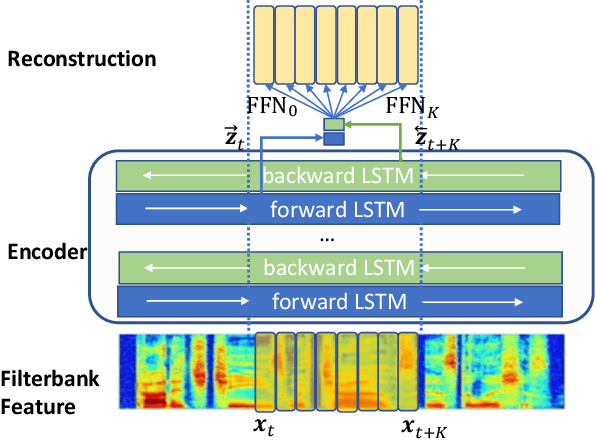

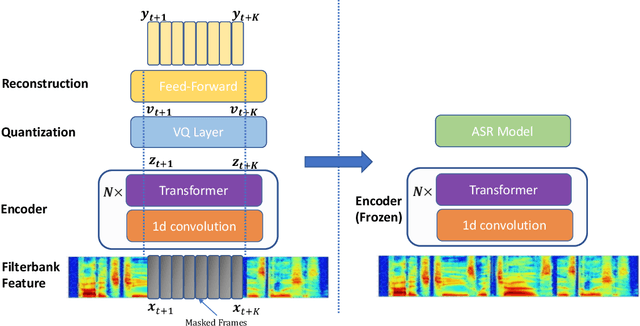
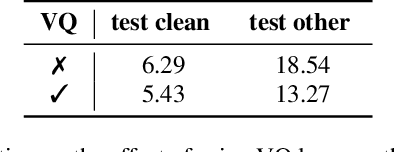
Recent success in speech representation learning enables a new way to leverage unlabeled data to train speech recognition model. In speech representation learning, a large amount of unlabeled data is used in a self-supervised manner to learn a feature representation. Then a smaller amount of labeled data is used to train a downstream ASR system using the new feature representations. Based on our previous work DeCoAR and inspirations from other speech representation learning, we propose DeCoAR 2.0, a Deep Contextualized Acoustic Representation with vector quantization. We introduce several modifications over the DeCoAR: first, we use Transformers in encoding module instead of LSTMs; second, we introduce a vector quantization layer between encoder and reconstruction modules; third, we propose an objective that combines the reconstructive loss with vector quantization diversity loss to train speech representations. Our experiments show consistent improvements over other speech representations in different data-sparse scenarios. Without fine-tuning, a light-weight ASR model trained on 10 hours of LibriSpeech labeled data with DeCoAR 2.0 features outperforms the model trained on the full 960-hour dataset with filterbank features.
Deep Contextualized Acoustic Representations For Semi-Supervised Speech Recognition
Dec 03, 2019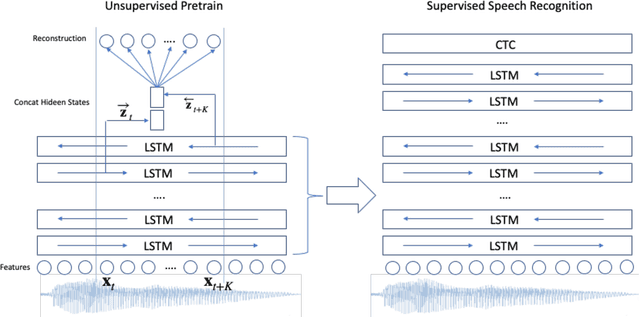

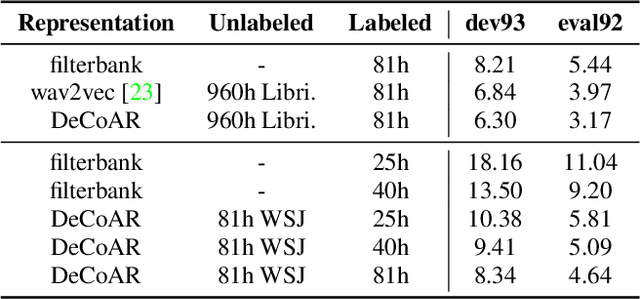

We propose a novel approach to semi-supervised automatic speech recognition (ASR). We first exploit a large amount of unlabeled audio data via representation learning, where we reconstruct a temporal slice of filterbank features from past and future context frames. The resulting deep contextualized acoustic representations (DeCoAR) are then used to train a CTC-based end-to-end ASR system using a smaller amount of labeled audio data. In our experiments, we show that systems trained on DeCoAR consistently outperform ones trained on conventional filterbank features, giving 42% and 19% relative improvement over the baseline on WSJ eval92 and LibriSpeech test-clean, respectively. Our approach can drastically reduce the amount of labeled data required; unsupervised training on LibriSpeech then supervision with 100 hours of labeled data achieves performance on par with training on all 960 hours directly.
Contextual Phonetic Pretraining for End-to-end Utterance-level Language and Speaker Recognition
Jun 30, 2019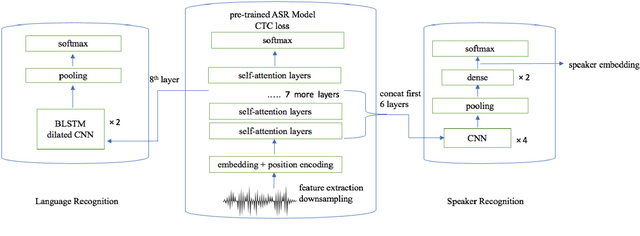
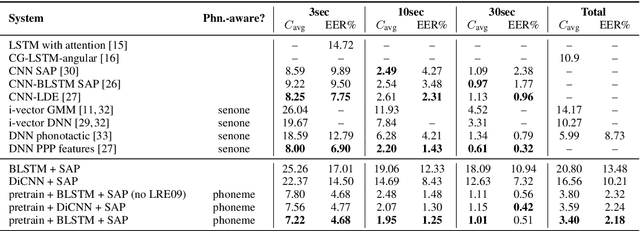
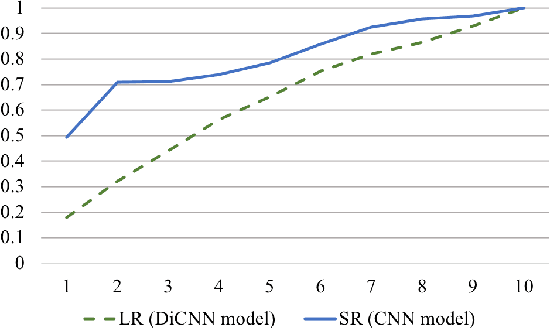
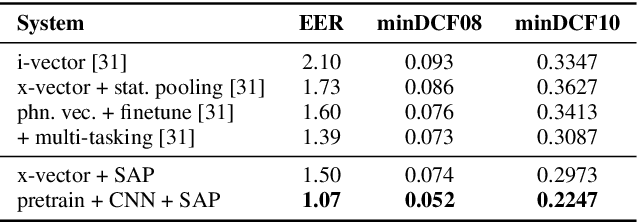
Pretrained contextual word representations in NLP have greatly improved performance on various downstream tasks. For speech, we propose contextual frame representations that capture phonetic information at the acoustic frame level and can be used for utterance-level language, speaker, and speech recognition. These representations come from the frame-wise intermediate representations of an end-to-end, self-attentive ASR model (SAN-CTC) on spoken utterances. We first train the model on the Fisher English corpus with context-independent phoneme labels, then use its representations at inference time as features for task-specific models on the NIST LRE07 closed-set language recognition task and a Fisher speaker recognition task, giving significant improvements over the state-of-the-art on both (e.g., language EER of 4.68% on 3sec utterances, 23% relative reduction in speaker EER). Results remain competitive when using a novel dilated convolutional model for language recognition, or when ASR pretraining is done with character labels only.