 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Form Speech Recognition for General Speech In-Context Learning
Paper and Code
Sep 29, 2024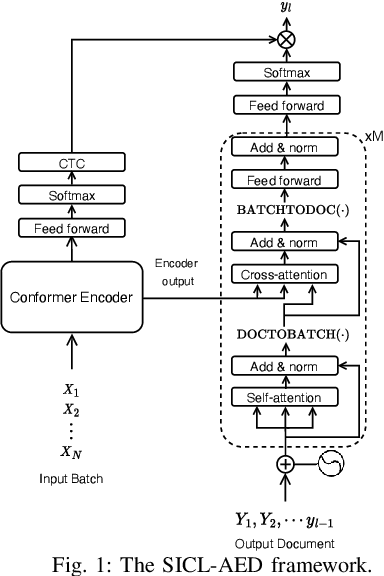
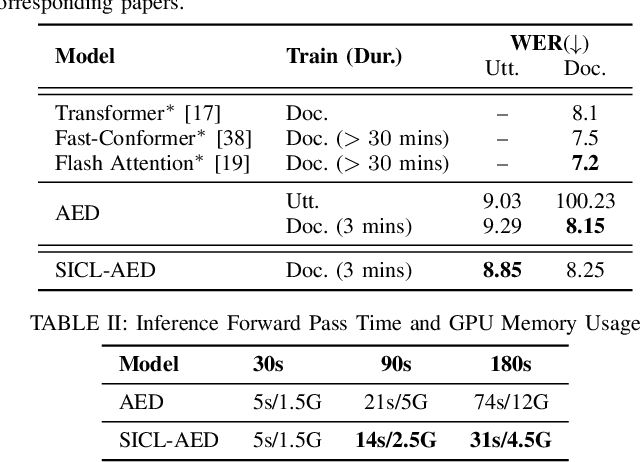
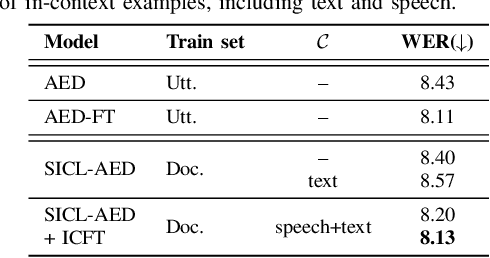
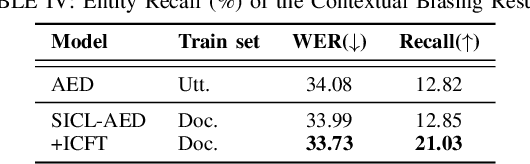
We propose a novel approach to end-to-end automatic speech recognition (ASR) to achieve efficient speech in-context learning (SICL) for (i) long-form speech decoding, (ii) test-time speaker adaptation, and (iii) test-time contextual biasing. Specifically, we introduce an attention-based encoder-decoder (AED) model with SICL capability (referred to as SICL-AED), where the decoder utilizes an utterance-level cross-attention to integrate information from the encoder's output efficiently, and a document-level self-attention to learn contextual information. Evaluated on the benchmark TEDLIUM3 dataset, SICL-AED achieves an 8.64% relative word error rate (WER) reduction compared to a baseline utterance-level AED model by leveraging previously decoded outputs as in-context examples. It also demonstrates comparable performance to conventional long-form AED systems with significantly reduced runtime and memory complexity. Additionally, we introduce an in-context fine-tuning (ICFT) technique that further enhances SICL effectiveness during inference. Experiments on speaker adaptation and contextual biasing highlight the general speech in-context learning capabilities of our system, achieving effective results with provided contexts. Without specific fine-tuning, SICL-AED matches the performance of supervised AED baselines for speaker adaptation and improves entity recall by 64% for contextual biasing task.