 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDM-ASR: Bridging Accuracy and Efficiency in ASR with Diffusion-Based Non-Autoregressive Decoding
Feb 24, 2026In sequence-to-sequence Transformer ASR, autoregressive (AR) models achieve strong accuracy but suffer from slow decoding, while non-autoregressive (NAR) models enable parallel decoding at the cost of degraded performance. We propose a principled NAR ASR framework based on Masked Diffusion Models to reduce this gap. A pre-trained speech encoder is coupled with a Transformer diffusion decoder conditioned on acoustic features and partially masked transcripts for parallel token prediction. To mitigate the training-inference mismatch, we introduce Iterative Self-Correction Training that exposes the model to its own intermediate predictions. We also design a Position-Biased Entropy-Bounded Confidence-based sampler with positional bias to further boost results. Experiments across multiple benchmarks demonstrate consistent gains over prior NAR models and competitive performance with strong AR baselines, while retaining parallel decoding efficiency.
A Bottom-up Framework with Language-universal Speech Attribute Modeling for Syllable-based ASR
Sep 09, 2025We propose a bottom-up framework for automatic speech recognition (ASR) in syllable-based languages by unifying language-universal articulatory attribute modeling with syllable-level prediction. The system first recognizes sequences or lattices of articulatory attributes that serve as a language-universal, interpretable representation of pronunciation, and then transforms them into syllables through a structured knowledge integration process. We introduce two evaluation metrics, namely Pronunciation Error Rate (PrER) and Syllable Homonym Error Rate (SHER), to evaluate the model's ability to capture pronunciation and handle syllable ambiguities. Experimental results on the AISHELL-1 Mandarin corpus demonstrate that the proposed bottom-up framework achieves competitive performance and exhibits better robustness under low-resource conditions compared to the direct syllable prediction model. Furthermore, we investigate the zero-shot cross-lingual transferability on Japanese and demonstrate significant improvements over character- and phoneme-based baselines by 40% error rate reduction.
An Investigation on Combining Geometry and Consistency Constraints into Phase Estimation for Speech Enhancement
Jul 02, 2025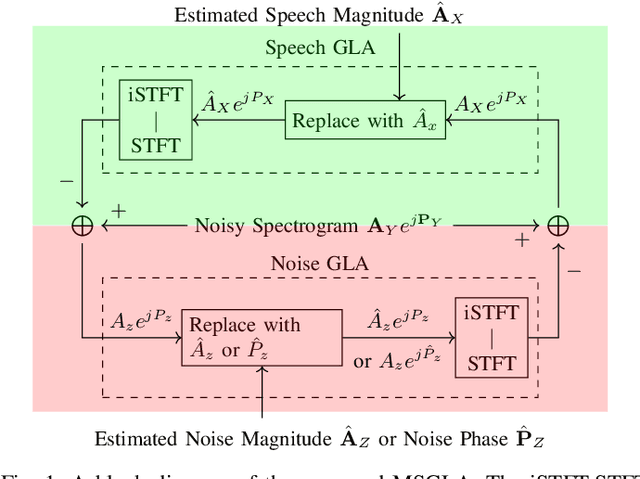
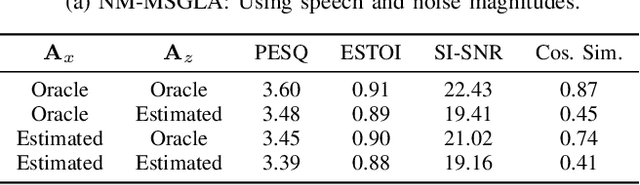
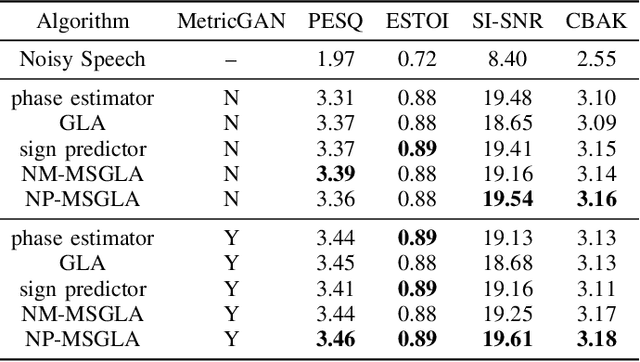
We propose a novel iterative phase estimation framework, termed multi-source Griffin-Lim algorithm (MSGLA), for speech enhancement (SE) under additive noise conditions. The core idea is to leverage the ad-hoc consistency constraint of complex-valued short-time Fourier transform (STFT) spectrograms to address the sign ambiguity challenge commonly encountered in geometry-based phase estimation. Furthermore, we introduce a variant of the geometric constraint framework based on the law of sines and cosines, formulating a new phase reconstruction algorithm using noise phase estimates. We first validate the proposed technique through a series of oracle experiments, demonstrating its effectiveness under ideal conditions. We then evaluate its performance on the VB-DMD and WSJ0-CHiME3 data sets, and show that the proposed MSGLA variants match well or slightly outperform existing algorithms, including direct phase estimation and DNN-based sign prediction, especially in terms of background noise suppression.
Efficient Long-Form Speech Recognition for General Speech In-Context Learning
Sep 29, 2024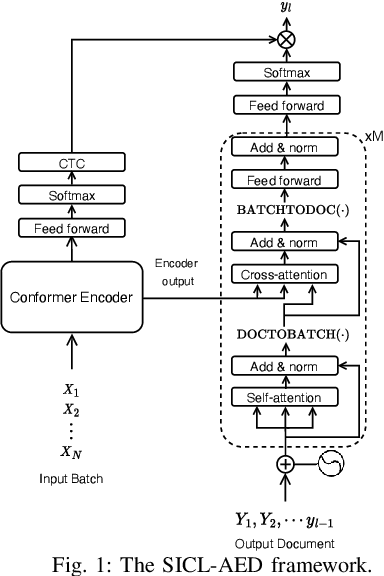
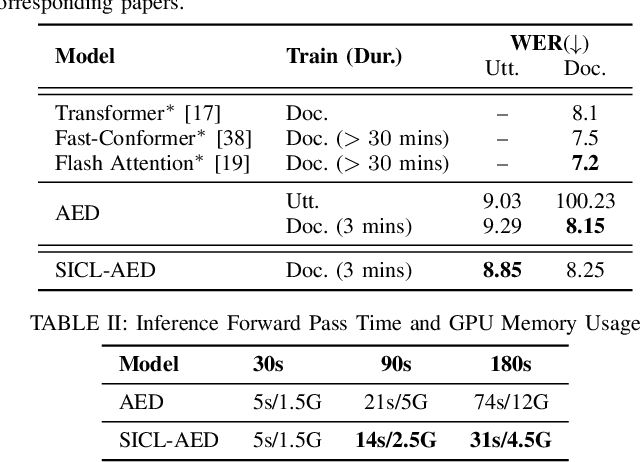
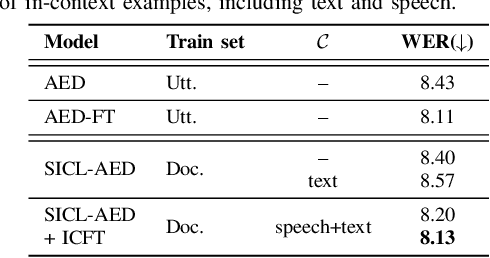
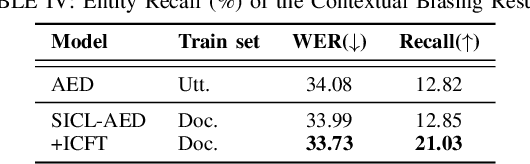
We propose a novel approach to end-to-end automatic speech recognition (ASR) to achieve efficient speech in-context learning (SICL) for (i) long-form speech decoding, (ii) test-time speaker adaptation, and (iii) test-time contextual biasing. Specifically, we introduce an attention-based encoder-decoder (AED) model with SICL capability (referred to as SICL-AED), where the decoder utilizes an utterance-level cross-attention to integrate information from the encoder's output efficiently, and a document-level self-attention to learn contextual information. Evaluated on the benchmark TEDLIUM3 dataset, SICL-AED achieves an 8.64% relative word error rate (WER) reduction compared to a baseline utterance-level AED model by leveraging previously decoded outputs as in-context examples. It also demonstrates comparable performance to conventional long-form AED systems with significantly reduced runtime and memory complexity. Additionally, we introduce an in-context fine-tuning (ICFT) technique that further enhances SICL effectiveness during inference. Experiments on speaker adaptation and contextual biasing highlight the general speech in-context learning capabilities of our system, achieving effective results with provided contexts. Without specific fine-tuning, SICL-AED matches the performance of supervised AED baselines for speaker adaptation and improves entity recall by 64% for contextual biasing task.
An Explicit Consistency-Preserving Loss Function for Phase Reconstruction and Speech Enhancement
Sep 24, 2024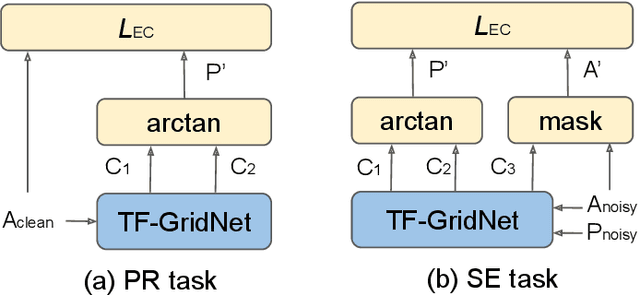
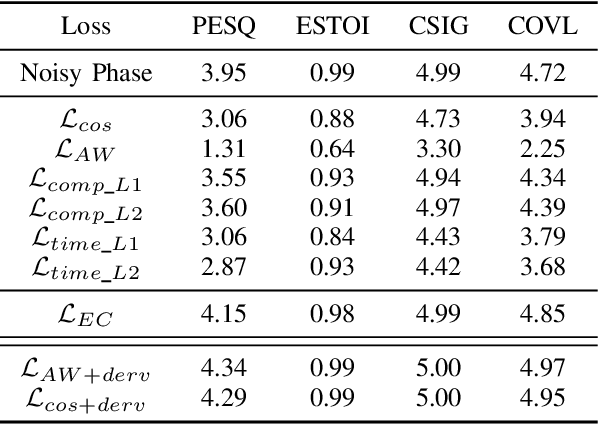

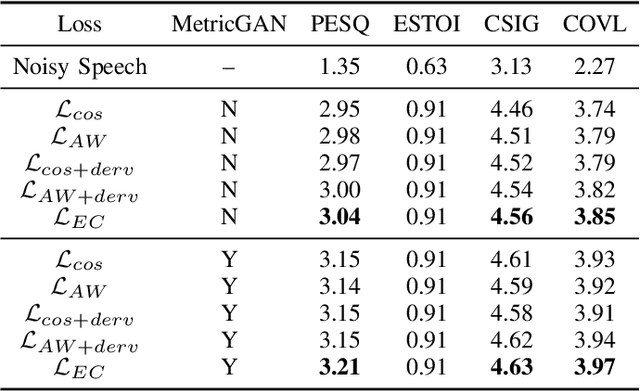
In this work, we propose a novel consistency-preserving loss function for recovering the phase information in the context of phase reconstruction (PR) and speech enhancement (SE). Different from conventional techniques that directly estimate the phase using a deep model, our idea is to exploit ad-hoc constraints to directly generate a consistent pair of magnitude and phase. Specifically, the proposed loss forces a set of complex numbers to be a consistent short-time Fourier transform (STFT) representation, i.e., to be the spectrogram of a real signal. Our approach thus avoids the difficulty of estimating the original phase, which is highly unstructured and sensitive to time shift. The influence of our proposed loss is first assessed on a PR task, experimentally demonstrating that our approach is viable. Next, we show its effectiveness on an SE task, using both the VB-DMD and WSJ0-CHiME3 data sets. On VB-DMD, our approach is competitive with conventional solutions. On the challenging WSJ0-CHiME3 set, the proposed framework compares favourably over those techniques that explicitly estimate the phase.
Language-Universal Speech Attributes Modeling for Zero-Shot Multilingual Spoken Keyword Recognition
Jun 04, 2024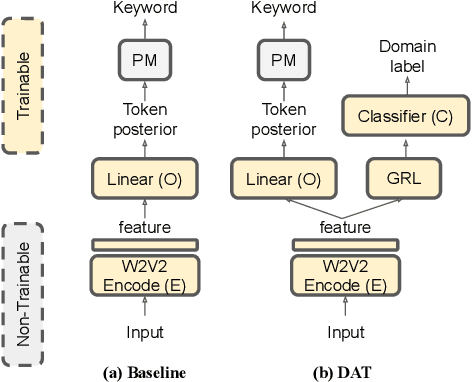

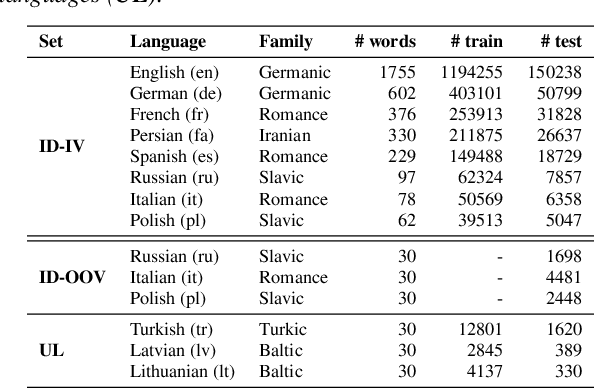

We propose a novel language-universal approach to end-to-end automatic spoken keyword recognition (SKR) leveraging upon (i) a self-supervised pre-trained model, and (ii) a set of universal speech attributes (manner and place of articulation). Specifically, Wav2Vec2.0 is used to generate robust speech representations, followed by a linear output layer to produce attribute sequences. A non-trainable pronunciation model then maps sequences of attributes into spoken keywords in a multilingual setting. Experiments on the Multilingual Spoken Words Corpus show comparable performances to character- and phoneme-based SKR in seen languages. The inclusion of domain adversarial training (DAT) improves the proposed framework, outperforming both character- and phoneme-based SKR approaches with 13.73% and 17.22% relative word error rate (WER) reduction in seen languages, and achieves 32.14% and 19.92% WER reduction for unseen languages in zero-shot settings.
Boosting End-to-End Multilingual Phoneme Recognition through Exploiting Universal Speech Attributes Constraints
Sep 16, 2023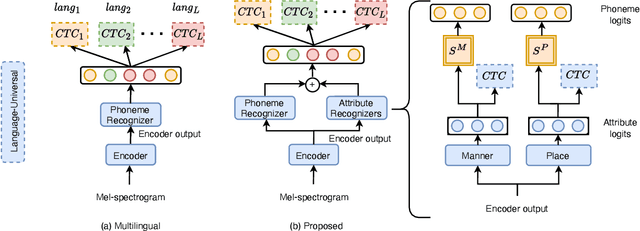
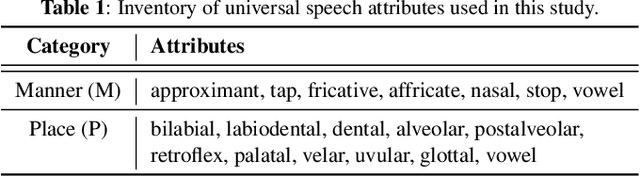
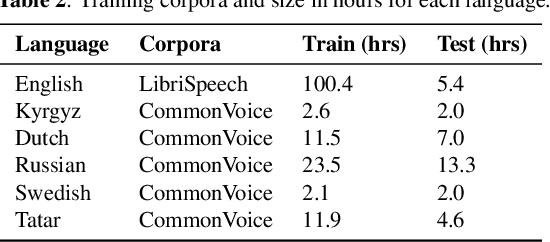
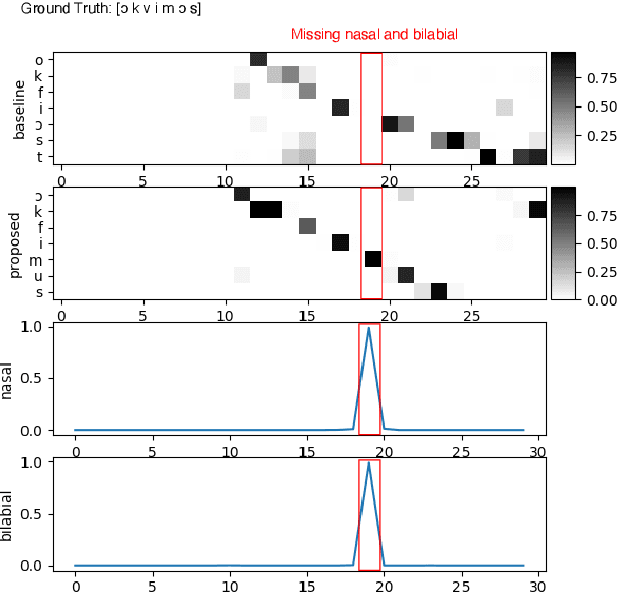
We propose a first step toward multilingual end-to-end automatic speech recognition (ASR) by integrating knowledge about speech articulators. The key idea is to leverage a rich set of fundamental units that can be defined "universally" across all spoken languages, referred to as speech attributes, namely manner and place of articulation. Specifically, several deterministic attribute-to-phoneme mapping matrices are constructed based on the predefined set of universal attribute inventory, which projects the knowledge-rich articulatory attribute logits, into output phoneme logits. The mapping puts knowledge-based constraints to limit inconsistency with acoustic-phonetic evidence in the integrated prediction. Combined with phoneme recognition, our phone recognizer is able to infer from both attribute and phoneme information. The proposed joint multilingual model is evaluated through phoneme recognition. In multilingual experiments over 6 languages on benchmark datasets LibriSpeech and CommonVoice, we find that our proposed solution outperforms conventional multilingual approaches with a relative improvement of 6.85% on average, and it also demonstrates a much better performance compared to monolingual model. Further analysis conclusively demonstrates that the proposed solution eliminates phoneme predictions that are inconsistent with attributes.
Cold Diffusion for Speech Enhancement
Nov 04, 2022Diffusion models have recently shown promising results for difficult enhancement tasks such as the conditional and unconditional restoration of natural images and audio signals. In this work, we explore the possibility of leveraging a recently proposed advanced iterative diffusion model, namely cold diffusion, to recover clean speech signals from noisy signals. The unique mathematical properties of the sampling process from cold diffusion could be utilized to restore high-quality samples from arbitrary degradations. Based on these properties, we propose an improved training algorithm and objective to help the model generalize better during the sampling process. We verify our proposed framework by investigating two model architectures. Experimental results on benchmark speech enhancement dataset VoiceBank-DEMAND demonstrate the strong performance of the proposed approach compared to representative discriminative models and diffusion-based enhancement models.
Improvements to Embedding-Matching Acoustic-to-Word ASR Using Multiple-Hypothesis Pronunciation-Based Embeddings
Oct 30, 2022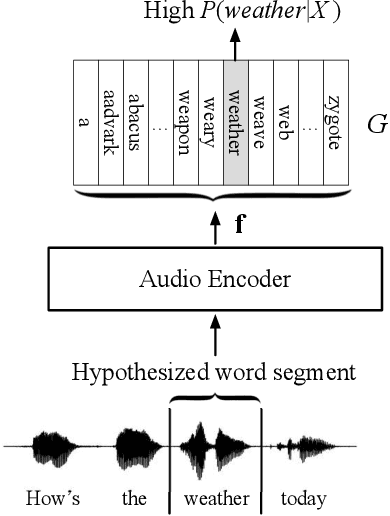
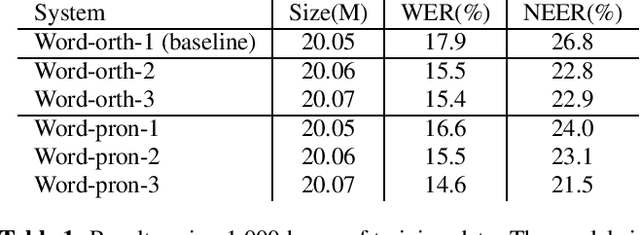
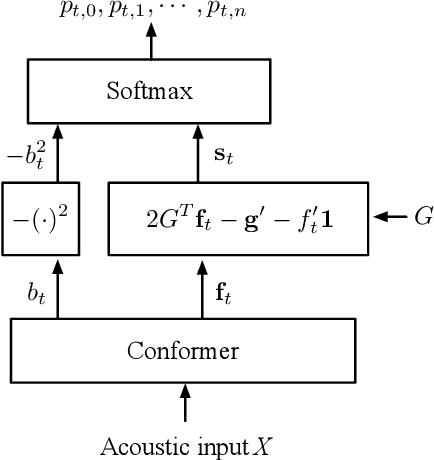

In embedding-matching acoustic-to-word (A2W) ASR, every word in the vocabulary is represented by a fixed-dimension embedding vector that can be added or removed independently of the rest of the system. The approach is potentially an elegant solution for the dynamic out-of-vocabulary (OOV) words problem, where speaker- and context-dependent named entities like contact names must be incorporated into the ASR on-the-fly for every speech utterance at testing time. Challenges still remain, however, in improving the overall accuracy of embedding-matching A2W. In this paper, we contribute two methods that improve the accuracy of embedding-matching A2W. First, we propose internally producing multiple embeddings, instead of a single embedding, at each instance in time, which allows the A2W model to propose a richer set of hypotheses over multiple time segments in the audio. Second, we propose using word pronunciation embeddings rather than word orthography embeddings to reduce ambiguities introduced by words that have more than one sound. We show that the above ideas give significant accuracy improvement, with the same training data and nearly identical model size, in scenarios where dynamic OOV words play a crucial role. On a dataset of various queries to a speech-based digital assistant that include many user-dependent contact names, we observe up to 18% decrease in word error rate using the proposed improvements.
A Study of Low-Resource Speech Commands Recognition based on Adversarial Reprogramming
Oct 08, 2021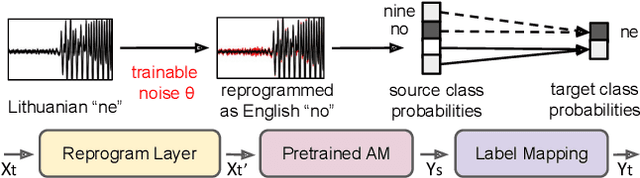
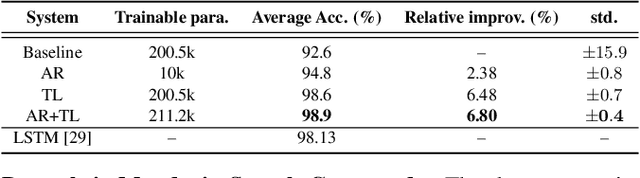
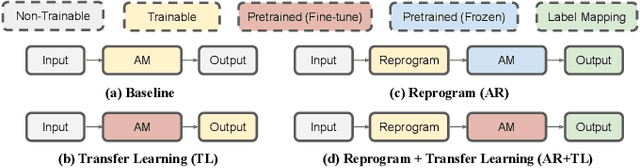
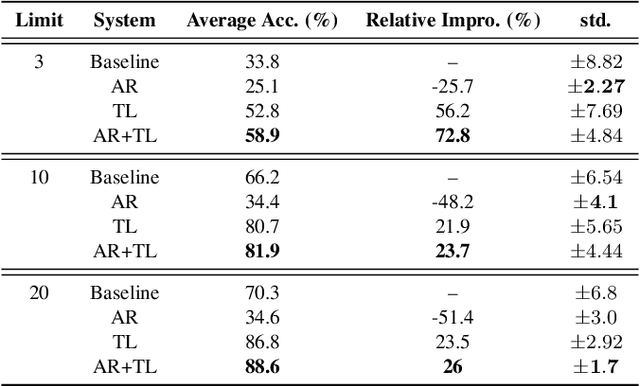
In this study, we propose a novel adversarial reprogramming (AR) approach for low-resource spoken command recognition (SCR), and build an AR-SCR system. The AR procedure aims to modify the acoustic signals (from the target domain) to repurpose a pretrained SCR model (from the source domain). To solve the label mismatches between source and target domains, and further improve the stability of AR, we propose a novel similarity-based label mapping technique to align classes. In addition, the transfer learning (TL) technique is combined with the original AR process to improve the model adaptation capability. We evaluate the proposed AR-SCR system on three low-resource SCR datasets, including Arabic, Lithuanian, and dysarthric Mandarin speech. Experimental results show that with a pretrained AM trained on a large-scale English dataset, the proposed AR-SCR system outperforms the current state-of-the-art results on Arabic and Lithuanian speech commands datasets, with only a limited amount of training data.