 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Knowledge-Driven Approach to Music Segmentation, Music Source Separation and Cinematic Audio Source Separation
Feb 25, 2026We propose a knowledge-driven, model-based approach to segmenting audio into single-category and mixed-category chunks with applications to source separation. "Knowledge" here denotes information associated with the data, such as music scores. "Model" here refers to tool that can be used for audio segmentation and recognition, such as hidden Markov models. In contrast to conventional learning that often relies on annotated data with given segment categories and their corresponding boundaries to guide the learning process, the proposed framework does not depend on any pre-segmented training data and learns directly from the input audio and its related knowledge sources to build all necessary models autonomously. Evaluation on simulation data shows that score-guided learning achieves very good music segmentation and separation results. Tested on movie track data for cinematic audio source separation also shows that utilizing sound category knowledge achieves better separation results than those obtained with data-driven techniques without using such information.
A Bottom-up Framework with Language-universal Speech Attribute Modeling for Syllable-based ASR
Sep 09, 2025We propose a bottom-up framework for automatic speech recognition (ASR) in syllable-based languages by unifying language-universal articulatory attribute modeling with syllable-level prediction. The system first recognizes sequences or lattices of articulatory attributes that serve as a language-universal, interpretable representation of pronunciation, and then transforms them into syllables through a structured knowledge integration process. We introduce two evaluation metrics, namely Pronunciation Error Rate (PrER) and Syllable Homonym Error Rate (SHER), to evaluate the model's ability to capture pronunciation and handle syllable ambiguities. Experimental results on the AISHELL-1 Mandarin corpus demonstrate that the proposed bottom-up framework achieves competitive performance and exhibits better robustness under low-resource conditions compared to the direct syllable prediction model. Furthermore, we investigate the zero-shot cross-lingual transferability on Japanese and demonstrate significant improvements over character- and phoneme-based baselines by 40% error rate reduction.
An Investigation on Combining Geometry and Consistency Constraints into Phase Estimation for Speech Enhancement
Jul 02, 2025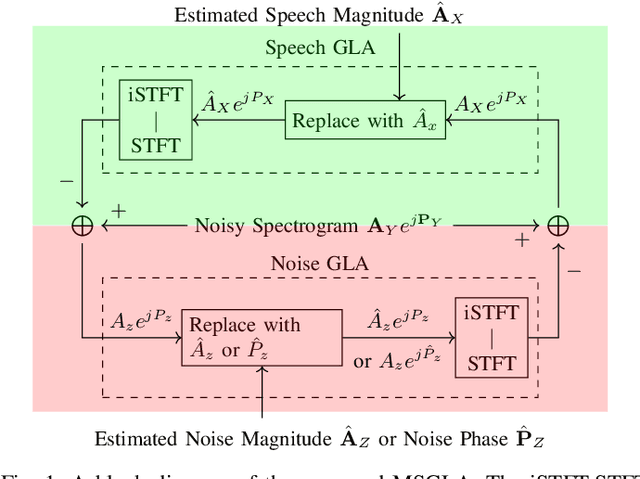
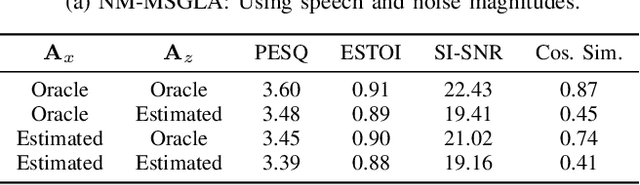
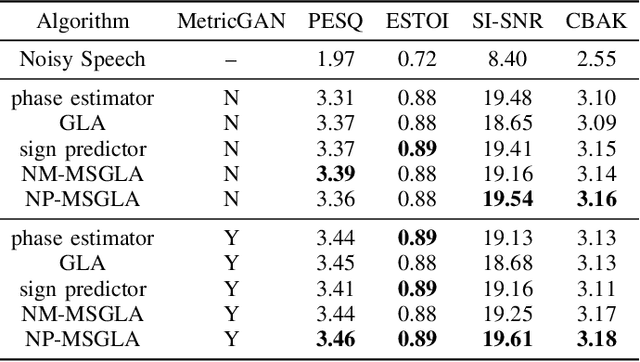
We propose a novel iterative phase estimation framework, termed multi-source Griffin-Lim algorithm (MSGLA), for speech enhancement (SE) under additive noise conditions. The core idea is to leverage the ad-hoc consistency constraint of complex-valued short-time Fourier transform (STFT) spectrograms to address the sign ambiguity challenge commonly encountered in geometry-based phase estimation. Furthermore, we introduce a variant of the geometric constraint framework based on the law of sines and cosines, formulating a new phase reconstruction algorithm using noise phase estimates. We first validate the proposed technique through a series of oracle experiments, demonstrating its effectiveness under ideal conditions. We then evaluate its performance on the VB-DMD and WSJ0-CHiME3 data sets, and show that the proposed MSGLA variants match well or slightly outperform existing algorithms, including direct phase estimation and DNN-based sign prediction, especially in terms of background noise suppression.
Variational Bayesian Adaptive Learning of Deep Latent Variables for Acoustic Knowledge Transfer
Jan 26, 2025



In this work, we propose a novel variational Bayesian adaptive learning approach for cross-domain knowledge transfer to address acoustic mismatches between training and testing conditions, such as recording devices and environmental noise. Different from the traditional Bayesian approaches that impose uncertainties on model parameters risking the curse of dimensionality due to the huge number of parameters, we focus on estimating a manageable number of latent variables in deep neural models. Knowledge learned from a source domain is thus encoded in prior distributions of deep latent variables and optimally combined, in a Bayesian sense, with a small set of adaptation data from a target domain to approximate the corresponding posterior distributions. Two different strategies are proposed and investigated to estimate the posterior distributions: Gaussian mean-field variational inference, and empirical Bayes. These strategies address the presence or absence of parallel data in the source and target domains. Furthermore, structural relationship modeling is investigated to enhance the approximation. We evaluated our proposed approaches on two acoustic adaptation tasks: 1) device adaptation for acoustic scene classification, and 2) noise adaptation for spoken command recognition. Experimental results show that the proposed variational Bayesian adaptive learning approach can obtain good improvements on target domain data, and consistently outperforms state-of-the-art knowledge transfer methods.
An Explicit Consistency-Preserving Loss Function for Phase Reconstruction and Speech Enhancement
Sep 24, 2024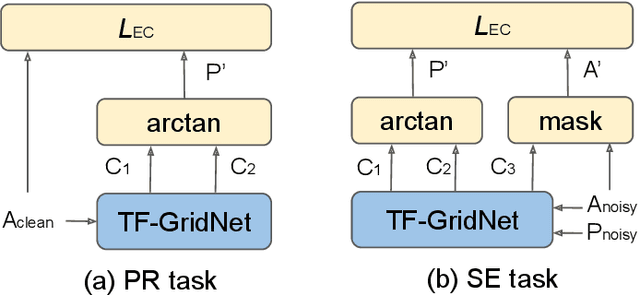
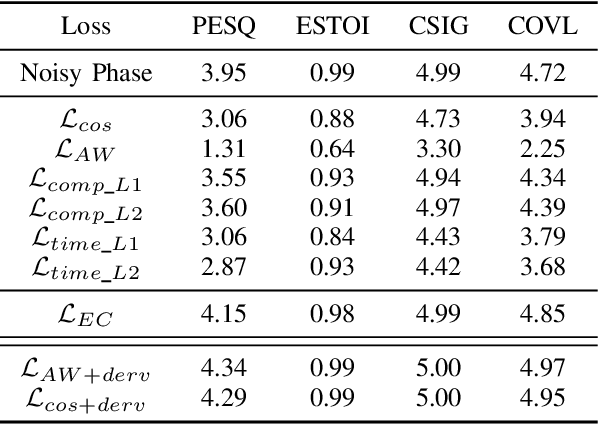

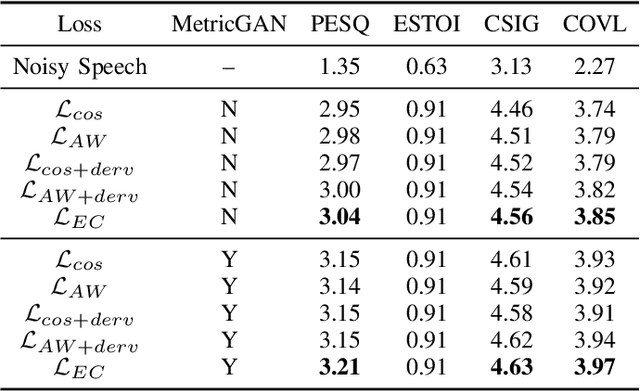
In this work, we propose a novel consistency-preserving loss function for recovering the phase information in the context of phase reconstruction (PR) and speech enhancement (SE). Different from conventional techniques that directly estimate the phase using a deep model, our idea is to exploit ad-hoc constraints to directly generate a consistent pair of magnitude and phase. Specifically, the proposed loss forces a set of complex numbers to be a consistent short-time Fourier transform (STFT) representation, i.e., to be the spectrogram of a real signal. Our approach thus avoids the difficulty of estimating the original phase, which is highly unstructured and sensitive to time shift. The influence of our proposed loss is first assessed on a PR task, experimentally demonstrating that our approach is viable. Next, we show its effectiveness on an SE task, using both the VB-DMD and WSJ0-CHiME3 data sets. On VB-DMD, our approach is competitive with conventional solutions. On the challenging WSJ0-CHiME3 set, the proposed framework compares favourably over those techniques that explicitly estimate the phase.
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Jun 21, 2024This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Enhancing Voice Wake-Up for Dysarthria: Mandarin Dysarthria Speech Corpus Release and Customized System Design
Jun 14, 2024



Smart home technology has gained widespread adoption, facilitating effortless control of devices through voice commands. However, individuals with dysarthria, a motor speech disorder, face challenges due to the variability of their speech. This paper addresses the wake-up word spotting (WWS) task for dysarthric individuals, aiming to integrate them into real-world applications. To support this, we release the open-source Mandarin Dysarthria Speech Corpus (MDSC), a dataset designed for dysarthric individuals in home environments. MDSC encompasses information on age, gender, disease types, and intelligibility evaluations. Furthermore, we perform comprehensive experimental analysis on MDSC, highlighting the challenges encountered. We also develop a customized dysarthria WWS system that showcases robustness in handling intelligibility and achieving exceptional performance. MDSC will be released on https://www.aishelltech.com/AISHELL_6B.
Language-Universal Speech Attributes Modeling for Zero-Shot Multilingual Spoken Keyword Recognition
Jun 04, 2024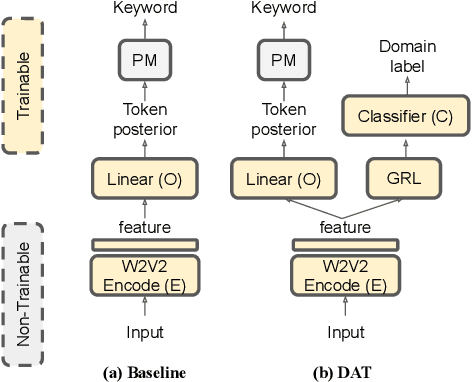

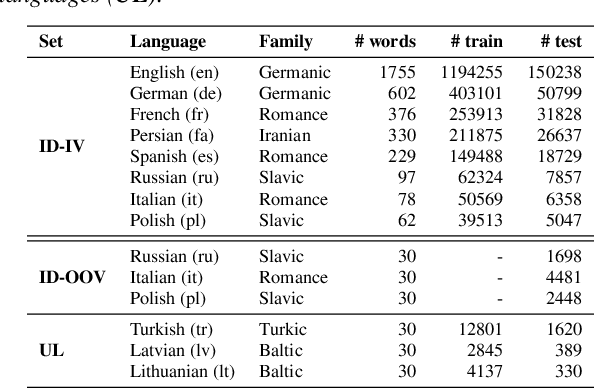

We propose a novel language-universal approach to end-to-end automatic spoken keyword recognition (SKR) leveraging upon (i) a self-supervised pre-trained model, and (ii) a set of universal speech attributes (manner and place of articulation). Specifically, Wav2Vec2.0 is used to generate robust speech representations, followed by a linear output layer to produce attribute sequences. A non-trainable pronunciation model then maps sequences of attributes into spoken keywords in a multilingual setting. Experiments on the Multilingual Spoken Words Corpus show comparable performances to character- and phoneme-based SKR in seen languages. The inclusion of domain adversarial training (DAT) improves the proposed framework, outperforming both character- and phoneme-based SKR approaches with 13.73% and 17.22% relative word error rate (WER) reduction in seen languages, and achieves 32.14% and 19.92% WER reduction for unseen languages in zero-shot settings.
A Study of Dropout-Induced Modality Bias on Robustness to Missing Video Frames for Audio-Visual Speech Recognition
Mar 07, 2024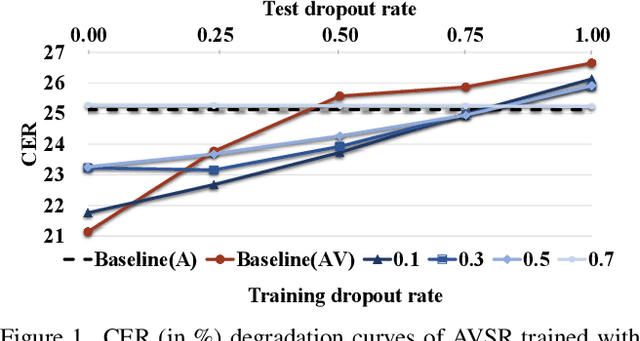

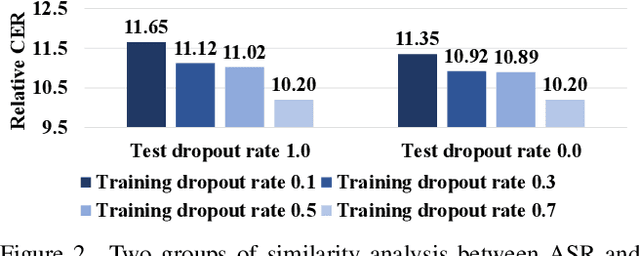
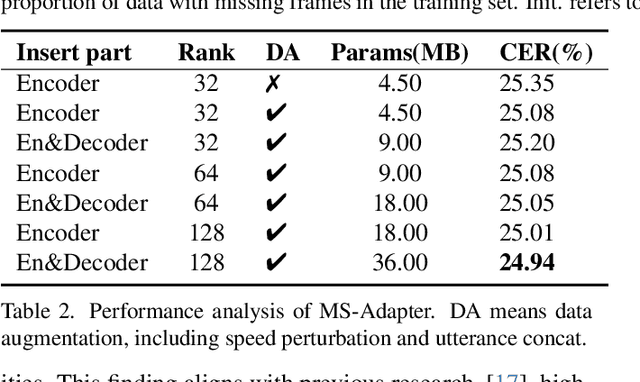
Advanced Audio-Visual Speech Recognition (AVSR) systems have been observed to be sensitive to missing video frames, performing even worse than single-modality models. While applying the dropout technique to the video modality enhances robustness to missing frames, it simultaneously results in a performance loss when dealing with complete data input. In this paper, we investigate this contrasting phenomenon from the perspective of modality bias and reveal that an excessive modality bias on the audio caused by dropout is the underlying reason. Moreover, we present the Modality Bias Hypothesis (MBH) to systematically describe the relationship between modality bias and robustness against missing modality in multimodal systems. Building on these findings, we propose a novel Multimodal Distribution Approximation with Knowledge Distillation (MDA-KD) framework to reduce over-reliance on the audio modality and to maintain performance and robustness simultaneously. Finally, to address an entirely missing modality, we adopt adapters to dynamically switch decision strategies. The effectiveness of our proposed approach is evaluated and validated through a series of comprehensive experiments using the MISP2021 and MISP2022 datasets. Our code is available at https://github.com/dalision/ModalBiasAVSR
Bayesian adaptive learning to latent variables via Variational Bayes and Maximum a Posteriori
Jan 24, 2024In this work, we aim to establish a Bayesian adaptive learning framework by focusing on estimating latent variables in deep neural network (DNN) models. Latent variables indeed encode both transferable distributional information and structural relationships. Thus the distributions of the source latent variables (prior) can be combined with the knowledge learned from the target data (likelihood) to yield the distributions of the target latent variables (posterior) with the goal of addressing acoustic mismatches between training and testing conditions. The prior knowledge transfer is accomplished through Variational Bayes (VB). In addition, we also investigate Maximum a Posteriori (MAP) based Bayesian adaptation. Experimental results on device adaptation in acoustic scene classification show that our proposed approaches can obtain good improvements on target devices, and consistently outperforms other cut-edging algorithms.