 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting End-to-End Multilingual Phoneme Recognition through Exploiting Universal Speech Attributes Constraints
Paper and Code
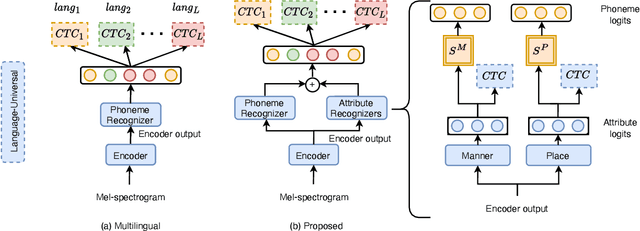
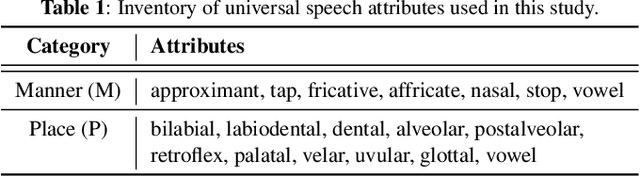
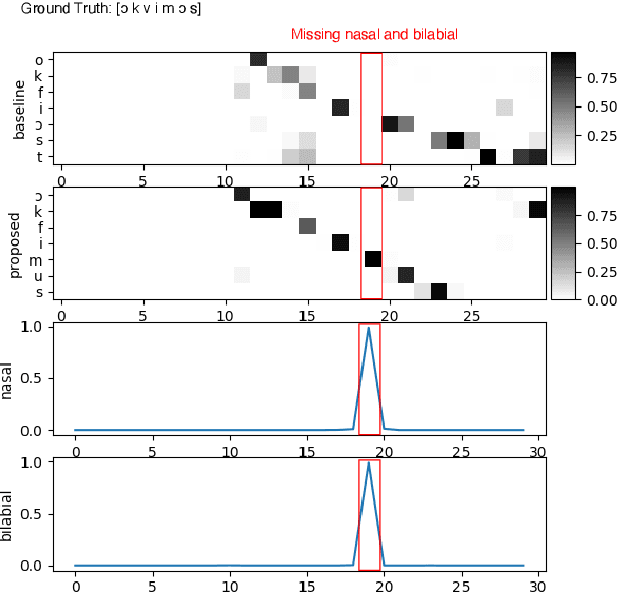
We propose a first step toward multilingual end-to-end automatic speech recognition (ASR) by integrating knowledge about speech articulators. The key idea is to leverage a rich set of fundamental units that can be defined "universally" across all spoken languages, referred to as speech attributes, namely manner and place of articulation. Specifically, several deterministic attribute-to-phoneme mapping matrices are constructed based on the predefined set of universal attribute inventory, which projects the knowledge-rich articulatory attribute logits, into output phoneme logits. The mapping puts knowledge-based constraints to limit inconsistency with acoustic-phonetic evidence in the integrated prediction. Combined with phoneme recognition, our phone recognizer is able to infer from both attribute and phoneme information. The proposed joint multilingual model is evaluated through phoneme recognition. In multilingual experiments over 6 languages on benchmark datasets LibriSpeech and CommonVoice, we find that our proposed solution outperforms conventional multilingual approaches with a relative improvement of 6.85% on average, and it also demonstrates a much better performance compared to monolingual model. Further analysis conclusively demonstrates that the proposed solution eliminates phoneme predictions that are inconsistent with attributes.