 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe USTC-NERCSLIP Systems for The ICMC-ASR Challenge
Jul 02, 2024


This report describes the submitted system to the In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) challenge, which considers the ASR task with multi-speaker overlapping and Mandarin accent dynamics in the ICMC case. We implement the front-end speaker diarization using the self-supervised learning representation based multi-speaker embedding and beamforming using the speaker position, respectively. For ASR, we employ an iterative pseudo-label generation method based on fusion model to obtain text labels of unsupervised data. To mitigate the impact of accent, an Accent-ASR framework is proposed, which captures pronunciation-related accent features at a fine-grained level and linguistic information at a coarse-grained level. On the ICMC-ASR eval set, the proposed system achieves a CER of 13.16% on track 1 and a cpCER of 21.48% on track 2, which significantly outperforms the official baseline system and obtains the first rank on both tracks.
Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding with Sequence-to-Sequence Architecture
Sep 17, 2023



We propose a novel neural speaker diarization system using memory-aware multi-speaker embedding with sequence-to-sequence architecture (NSD-MS2S), which integrates the strengths of memory-aware multi-speaker embedding (MA-MSE) and sequence-to-sequence (Seq2Seq) architecture, leading to improvement in both efficiency and performance. Next, we further decrease the memory occupation of decoding by incorporating input features fusion and then employ a multi-head attention mechanism to capture features at different levels. NSD-MS2S achieved a macro diarization error rate (DER) of 15.9% on the CHiME-7 EVAL set, which signifies a relative improvement of 49% over the official baseline system, and is the key technique for us to achieve the best performance for the main track of CHiME-7 DASR Challenge. Additionally, we introduce a deep interactive module (DIM) in MA-MSE module to better retrieve a cleaner and more discriminative multi-speaker embedding, enabling the current model to outperform the system we used in the CHiME-7 DASR Challenge. Our code will be available at https://github.com/liyunlongaaa/NSD-MS2S.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023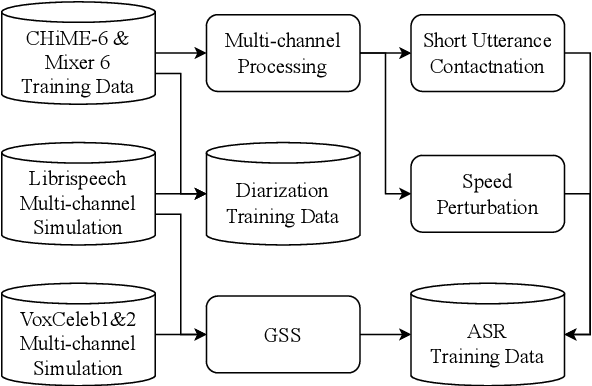
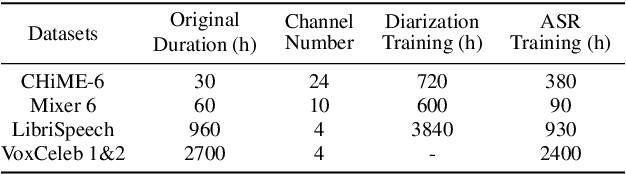
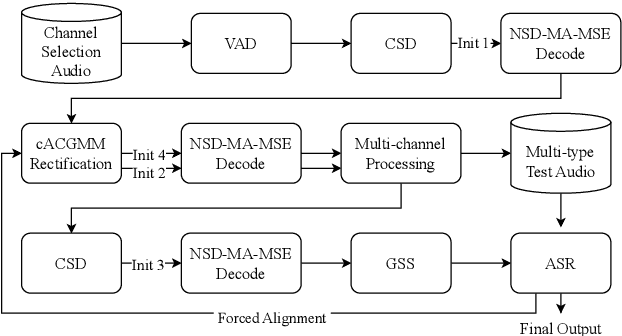
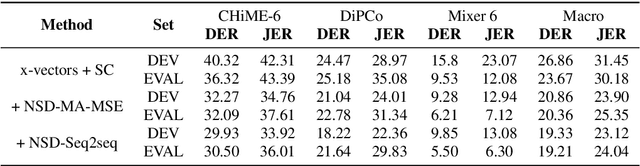
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.