 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind-Omni: A Unified Multi-Task Framework for Brain-Vision-Language Modeling via Discrete Diffusion
May 28, 2026Modeling the interplay between external stimuli and internal neural representations is a pivotal research area for Brain-Computer Interfaces (BCIs). A major limitation of prior work is the prevailing paradigm of specialized, single-task models, which curtails versatility and neglects inter-task synergies. To address this, we propose Mind-Omni, the first versatile framework that unifies seven distinct encoding and decoding tasks through a discrete diffusion paradigm. At its core is a novel Brain Tokenizer that transforms heterogeneous, continuous brain signals into standardized, discrete tokens. This enables direct, token-level interactions for mutual understanding and generation between any two or more modalities within a shared semantic space. To unlock advanced reasoning capabilities, we further curate a specialized Brain Question Answering (BQA) instruction-tuning dataset. Our model not only establishes a new state-of-the-art among multi-task unified frameworks but also provides strong evidence for multi-task synergy. By demonstrating performance competitive with, and at times superior to, larger specialized models, our work offers a powerful new paradigm for neural modeling and paves the way for foundation models of neural activity. The code is publicly available at https://github.com/ReedOnePeck/Mind-Omni.
Navigating by Old Maps: The Pitfalls of Static Mechanistic Localization in LLM Post-Training
May 07, 2026The "Locate-then-Update" paradigm has become a predominant approach in the post-training of large language models (LLMs), identifying critical components via mechanistic interpretability for targeted parameter updates. However, this paradigm rests on a fundamental yet unverified assumption: can mechanisms derived from current static parameters reliably guide future dynamic parameter updates? To investigate this, we systematically track the structural evolution of Transformer circuits throughout the supervised fine-tuning (SFT) process, revealing the underlying dynamics of task mechanisms. We introduce three novel metrics-Circuit Distance, Circuit Stability, and Circuit Conflict-to analyze circuit evolution across three dimensions: neural migration, semantic stability, and cross-task interference. Our empirical results reveal that circuits inherently exhibit "Free Evolution" during parameter updates. Consequently, static mechanisms extracted from current states inevitably suffer from temporal latency, making them fundamentally inadequate for guiding future states. Moreover, by deconstructing the "illusion of effectiveness" in existing methods, this work underscores the necessity of "foresight" in mechanistic localization and proposes a predictive framework for future research.
Disentangling to Re-couple: Resolving the Similarity-Controllability Paradox in Subject-Driven Text-to-Image Generation
Apr 01, 2026Subject-Driven Text-to-Image (T2I) Generation aims to preserve a subject's identity while editing its context based on a text prompt. A core challenge in this task is the "similarity-controllability paradox", where enhancing textual control often degrades the subject's fidelity, and vice-versa. We argue this paradox stems from the ambiguous role of text prompts, which are often tasked with describing both the subject and the desired modifications, leading to conflicting signals for the model. To resolve this, we propose DisCo, a novel framework that first Disntangles and then re-Couples visual and textual information. First, our textual-visual decoupling module isolates the sources of information: subject identity is extracted exclusively from the reference image with the entity word of the subject, while the text prompt is simplified to contain only the modification command, where the subject refers to general pronouns, eliminating descriptive ambiguity. However, this strict separation can lead to unnatural compositions between the subject and its contexts. We address this by designing a dedicated reward signal and using reinforcement learning to seamlessly recouple the visually-defined subject and the textually-generated context. Our approach effectively resolves the paradox, enabling simultaneous high-fidelity subject preservation and precise textual control. Extensive experiments demonstrate that our method achieves state-of-the-art performance, producing highly realistic and coherent images.
DSH-Bench: A Difficulty- and Scenario-Aware Benchmark with Hierarchical Subject Taxonomy for Subject-Driven Text-to-Image Generation
Mar 09, 2026Significant progress has been achieved in subject-driven text-to-image (T2I) generation, which aims to synthesize new images depicting target subjects according to user instructions. However, evaluating these models remains a significant challenge. Existing benchmarks exhibit critical limitations: 1) insufficient diversity and comprehensiveness in subject images, 2) inadequate granularity in assessing model performance across different subject difficulty levels and prompt scenarios, and 3) a profound lack of actionable insights and diagnostic guidance for subsequent model refinement. To address these limitations, we propose DSH-Bench, a comprehensive benchmark that enables systematic multi-perspective analysis of subject-driven T2I models through four principal innovations: 1) a hierarchical taxonomy sampling mechanism ensuring comprehensive subject representation across 58 fine-grained categories, 2) an innovative classification scheme categorizing both subject difficulty level and prompt scenario for granular capability assessment, 3) a novel Subject Identity Consistency Score (SICS) metric demonstrating a 9.4\% higher correlation with human evaluation compared to existing measures in quantifying subject preservation, and 4) a comprehensive set of diagnostic insights derived from the benchmark, offering critical guidance for optimizing future model training paradigms and data construction strategies. Through an extensive empirical evaluation of 19 leading models, DSH-Bench uncovers previously obscured limitations in current approaches, establishing concrete directions for future research and development.
The USTC-NERCSLIP Systems for the CHiME-9 MCoRec Challenge
Mar 02, 2026This report details our submission to the CHiME-9 MCoRec Challenge on recognizing and clustering multiple concurrent natural conversations within indoor social settings. Unlike conventional meetings centered on a single shared topic, this scenario contains multiple parallel dialogues--up to eight speakers across up to four simultaneous conversations--with a speech overlap rate exceeding 90%. To tackle this, we propose a multimodal cascaded system that leverages per-speaker visual streams extracted from synchronized 360 degree video together with single-channel audio. Our system improves three components of the pipeline by leveraging enhanced audio-visual pretrained models: Active Speaker Detection (ASD), Audio-Visual Target Speech Extraction (AVTSE), and Audio-Visual Speech Recognition (AVSR). The AVSR module further incorporates Whisper and LLM techniques to boost transcription accuracy. Our best single cascaded system achieves a Speaker Word Error Rate (WER) of 32.44% on the development set. By further applying ROVER to fuse outputs from diverse front-end and back-end variants, we reduce Speaker WER to 31.40%. Notably, our LLM-based zero-shot conversational clustering achieves a speaker clustering F1 score of 1.0, yielding a final Joint ASR-Clustering Error Rate (JACER) of 15.70%.
Towards Efficient 3D Object Detection for Vehicle-Infrastructure Collaboration via Risk-Intent Selection
Jan 06, 2026Vehicle-Infrastructure Collaborative Perception (VICP) is pivotal for resolving occlusion in autonomous driving, yet the trade-off between communication bandwidth and feature redundancy remains a critical bottleneck. While intermediate fusion mitigates data volume compared to raw sharing, existing frameworks typically rely on spatial compression or static confidence maps, which inefficiently transmit spatially redundant features from non-critical background regions. To address this, we propose Risk-intent Selective detection (RiSe), an interaction-aware framework that shifts the paradigm from identifying visible regions to prioritizing risk-critical ones. Specifically, we introduce a Potential Field-Trajectory Correlation Model (PTCM) grounded in potential field theory to quantitatively assess kinematic risks. Complementing this, an Intention-Driven Area Prediction Module (IDAPM) leverages ego-motion priors to proactively predict and filter key Bird's-Eye-View (BEV) areas essential for decision-making. By integrating these components, RiSe implements a semantic-selective fusion scheme that transmits high-fidelity features only from high-interaction regions, effectively acting as a feature denoiser. Extensive experiments on the DeepAccident dataset demonstrate that our method reduces communication volume to 0.71\% of full feature sharing while maintaining state-of-the-art detection accuracy, establishing a competitive Pareto frontier between bandwidth efficiency and perception performance.
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
UrbanV2X: A Multisensory Vehicle-Infrastructure Dataset for Cooperative Navigation in Urban Areas
Dec 23, 2025
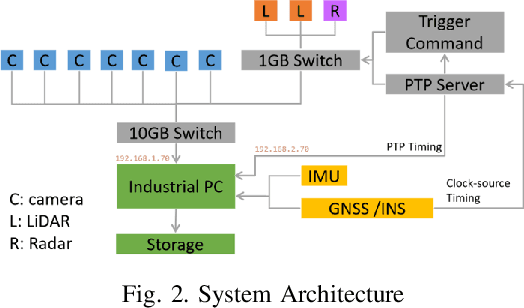

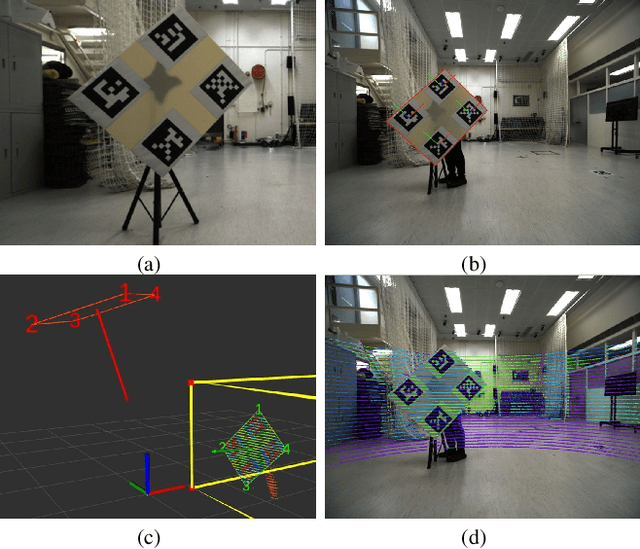
Due to the limitations of a single autonomous vehicle, Cellular Vehicle-to-Everything (C-V2X) technology opens a new window for achieving fully autonomous driving through sensor information sharing. However, real-world datasets supporting vehicle-infrastructure cooperative navigation in complex urban environments remain rare. To address this gap, we present UrbanV2X, a comprehensive multisensory dataset collected from vehicles and roadside infrastructure in the Hong Kong C-V2X testbed, designed to support research on smart mobility applications in dense urban areas. Our onboard platform provides synchronized data from multiple industrial cameras, LiDARs, 4D radar, ultra-wideband (UWB), IMU, and high-precision GNSS-RTK/INS navigation systems. Meanwhile, our roadside infrastructure provides LiDAR, GNSS, and UWB measurements. The entire vehicle-infrastructure platform is synchronized using the Precision Time Protocol (PTP), with sensor calibration data provided. We also benchmark various navigation algorithms to evaluate the collected cooperative data. The dataset is publicly available at https://polyu-taslab.github.io/UrbanV2X/.
Deep Pathomic Learning Defines Prognostic Subtypes and Molecular Drivers in Colorectal Cancer
Nov 19, 2025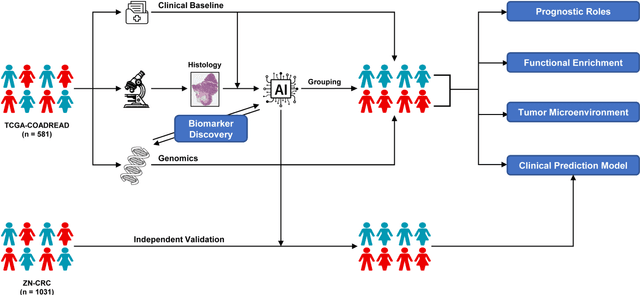
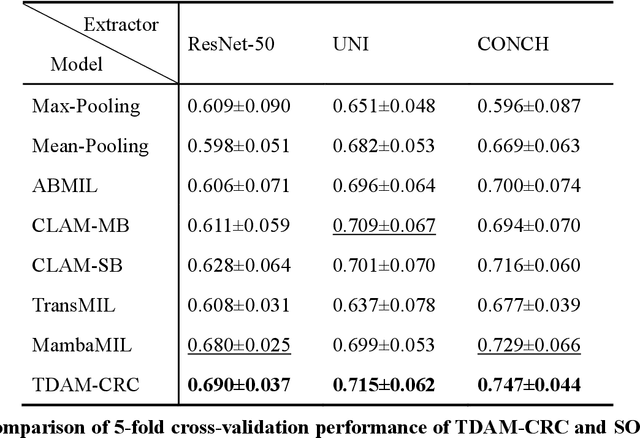
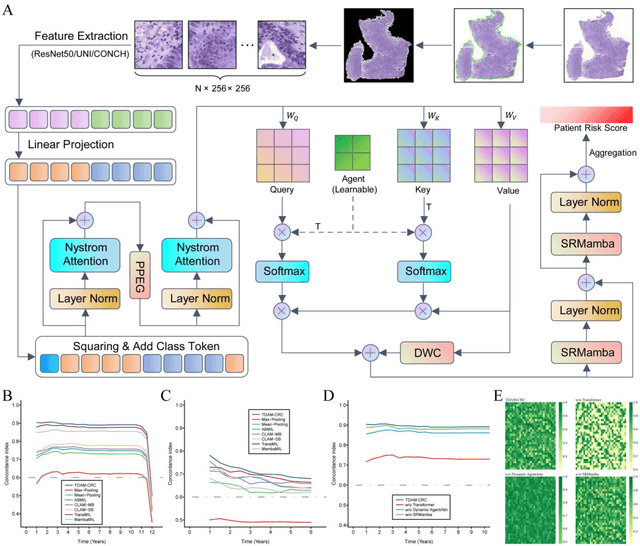
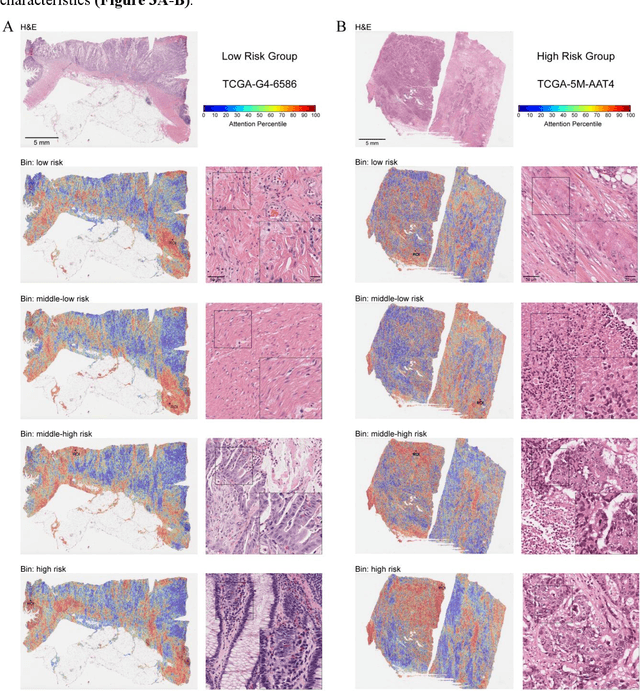
Precise prognostic stratification of colorectal cancer (CRC) remains a major clinical challenge due to its high heterogeneity. The conventional TNM staging system is inadequate for personalized medicine. We aimed to develop and validate a novel multiple instance learning model TDAM-CRC using histopathological whole-slide images for accurate prognostic prediction and to uncover its underlying molecular mechanisms. We trained the model on the TCGA discovery cohort (n=581), validated it in an independent external cohort (n=1031), and further we integrated multi-omics data to improve model interpretability and identify novel prognostic biomarkers. The results demonstrated that the TDAM-CRC achieved robust risk stratification in both cohorts. Its predictive performance significantly outperformed the conventional clinical staging system and multiple state-of-the-art models. The TDAM-CRC risk score was confirmed as an independent prognostic factor in multivariable analysis. Multi-omics analysis revealed that the high-risk subtype is closely associated with metabolic reprogramming and an immunosuppressive tumor microenvironment. Through interaction network analysis, we identified and validated Mitochondrial Ribosomal Protein L37 (MRPL37) as a key hub gene linking deep pathomic features to clinical prognosis. We found that high expression of MRPL37, driven by promoter hypomethylation, serves as an independent biomarker of favorable prognosis. Finally, we constructed a nomogram incorporating the TDAM-CRC risk score and clinical factors to provide a precise and interpretable clinical decision-making tool for CRC patients. Our AI-driven pathological model TDAM-CRC provides a robust tool for improved CRC risk stratification, reveals new molecular targets, and facilitates personalized clinical decision-making.
FGNet: Leveraging Feature-Guided Attention to Refine SAM2 for 3D EM Neuron Segmentation
Nov 17, 2025Accurate segmentation of neural structures in Electron Microscopy (EM) images is paramount for neuroscience. However, this task is challenged by intricate morphologies, low signal-to-noise ratios, and scarce annotations, limiting the accuracy and generalization of existing methods. To address these challenges, we seek to leverage the priors learned by visual foundation models on a vast amount of natural images to better tackle this task. Specifically, we propose a novel framework that can effectively transfer knowledge from Segment Anything 2 (SAM2), which is pre-trained on natural images, to the EM domain. We first use SAM2 to extract powerful, general-purpose features. To bridge the domain gap, we introduce a Feature-Guided Attention module that leverages semantic cues from SAM2 to guide a lightweight encoder, the Fine-Grained Encoder (FGE), in focusing on these challenging regions. Finally, a dual-affinity decoder generates both coarse and refined affinity maps. Experimental results demonstrate that our method achieves performance comparable to state-of-the-art (SOTA) approaches with the SAM2 weights frozen. Upon further fine-tuning on EM data, our method significantly outperforms existing SOTA methods. This study validates that transferring representations pre-trained on natural images, when combined with targeted domain-adaptive guidance, can effectively address the specific challenges in neuron segmentation.