 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Speech Recognition with Decoder-Only Large Language Models and Latency Optimization
Jan 30, 2026Recent advances have demonstrated the potential of decoderonly large language models (LLMs) for automatic speech recognition (ASR). However, enabling streaming recognition within this framework remains a challenge. In this work, we propose a novel streaming ASR approach that integrates a read/write policy network with monotonic chunkwise attention (MoChA) to dynamically segment speech embeddings. These segments are interleaved with label sequences during training, enabling seamless integration with the LLM. During inference, the audio stream is buffered until the MoChA module triggers a read signal, at which point the buffered segment together with the previous token is fed into the LLM for the next token prediction. We also introduce a minimal-latency training objective to guide the policy network toward accurate segmentation boundaries. Furthermore, we adopt a joint training strategy in which a non-streaming LLM-ASR model and our streaming model share parameters. Experiments on the AISHELL-1 and AISHELL-2 Mandarin benchmarks demonstrate that our method consistently outperforms recent streaming ASR baselines, achieving character error rates of 5.1% and 5.5%, respectively. The latency optimization results in a 62.5% reduction in average token generation delay with negligible impact on recognition accuracy
Deep CLAS: Deep Contextual Listen, Attend and Spell
Sep 26, 2024



Contextual-LAS (CLAS) has been shown effective in improving Automatic Speech Recognition (ASR) of rare words. It relies on phrase-level contextual modeling and attention-based relevance scoring without explicit contextual constraint which lead to insufficient use of contextual information. In this work, we propose deep CLAS to use contextual information better. We introduce bias loss forcing model to focus on contextual information. The query of bias attention is also enriched to improve the accuracy of the bias attention score. To get fine-grained contextual information, we replace phrase-level encoding with character-level encoding and encode contextual information with conformer rather than LSTM. Moreover, we directly use the bias attention score to correct the output probability distribution of the model. Experiments using the public AISHELL-1 and AISHELL-NER. On AISHELL-1, compared to CLAS baselines, deep CLAS obtains a 65.78% relative recall and a 53.49% relative F1-score increase in the named entity recognition scene.
A Study of Designing Compact Audio-Visual Wake Word Spotting System Based on Iterative Fine-Tuning in Neural Network Pruning
Feb 17, 2022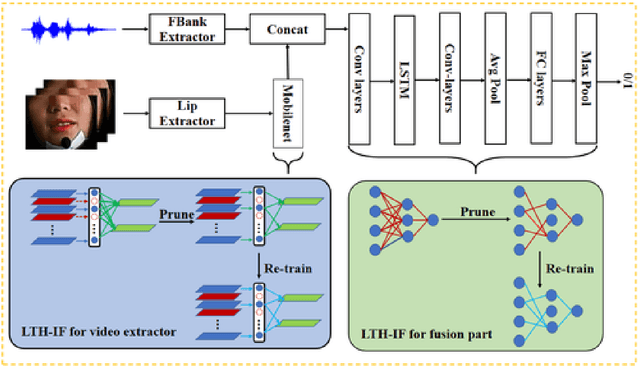
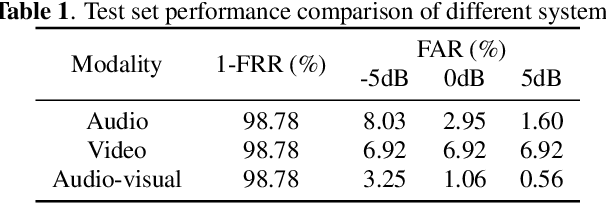
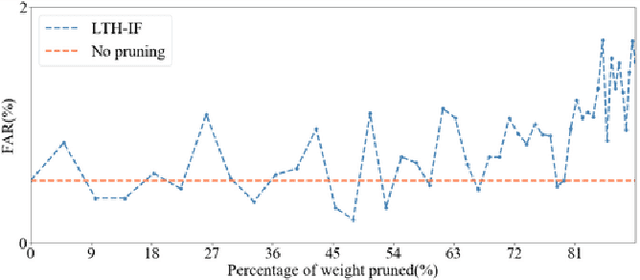
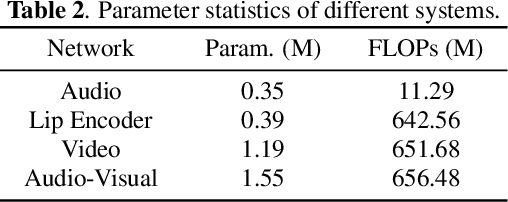
Audio-only-based wake word spotting (WWS) is challenging under noisy conditions due to environmental interference in signal transmission. In this paper, we investigate on designing a compact audio-visual WWS system by utilizing visual information to alleviate the degradation. Specifically, in order to use visual information, we first encode the detected lips to fixed-size vectors with MobileNet and concatenate them with acoustic features followed by the fusion network for WWS. However, the audio-visual model based on neural networks requires a large footprint and a high computational complexity. To meet the application requirements, we introduce a neural network pruning strategy via the lottery ticket hypothesis in an iterative fine-tuning manner (LTH-IF), to the single-modal and multi-modal models, respectively. Tested on our in-house corpus for audio-visual WWS in a home TV scene, the proposed audio-visual system achieves significant performance improvements over the single-modality (audio-only or video-only) system under different noisy conditions. Moreover, LTH-IF pruning can largely reduce the network parameters and computations with no degradation of WWS performance, leading to a potential product solution for the TV wake-up scenario.
The USTC-NEL Speech Translation system at IWSLT 2018
Dec 06, 2018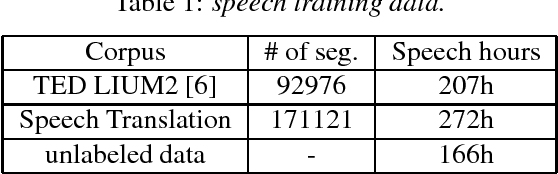

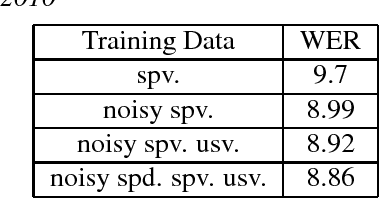

This paper describes the USTC-NEL system to the speech translation task of the IWSLT Evaluation 2018. The system is a conventional pipeline system which contains 3 modules: speech recognition, post-processing and machine translation. We train a group of hybrid-HMM models for our speech recognition, and for machine translation we train transformer based neural machine translation models with speech recognition output style text as input. Experiments conducted on the IWSLT 2018 task indicate that, compared to baseline system from KIT, our system achieved 14.9 BLEU improvement.