 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of the Removability of Speaker-Adversarial Perturbations
Oct 10, 2025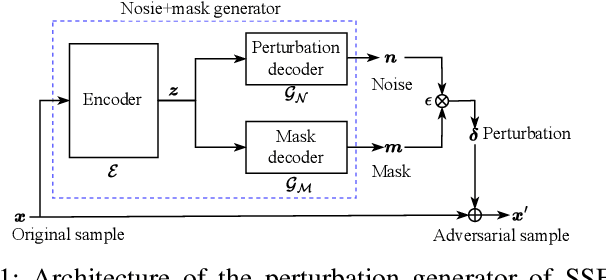

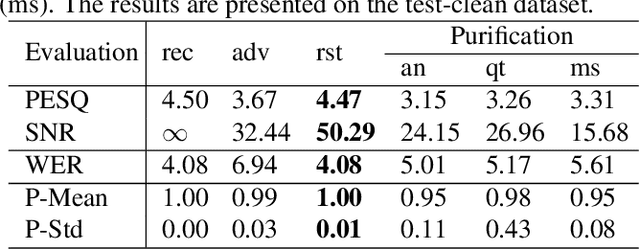
Recent advancements in adversarial attacks have demonstrated their effectiveness in misleading speaker recognition models, making wrong predictions about speaker identities. On the other hand, defense techniques against speaker-adversarial attacks focus on reducing the effects of speaker-adversarial perturbations on speaker attribute extraction. These techniques do not seek to fully remove the perturbations and restore the original speech. To this end, this paper studies the removability of speaker-adversarial perturbations. Specifically, the investigation is conducted assuming various degrees of awareness of the perturbation generator across three scenarios: ignorant, semi-informed, and well-informed. Besides, we consider both the optimization-based and feedforward perturbation generation methods. Experiments conducted on the LibriSpeech dataset demonstrated that: 1) in the ignorant scenario, speaker-adversarial perturbations cannot be eliminated, although their impact on speaker attribute extraction is reduced, 2) in the semi-informed scenario, the speaker-adversarial perturbations cannot be fully removed, while those generated by the feedforward model can be considerably reduced, and 3) in the well-informed scenario, speaker-adversarial perturbations are nearly eliminated, allowing for the restoration of the original speech. Audio samples can be found in https://voiceprivacy.github.io/Perturbation-Generation-Removal/.
On the Generation and Removal of Speaker Adversarial Perturbation for Voice-Privacy Protection
Dec 12, 2024


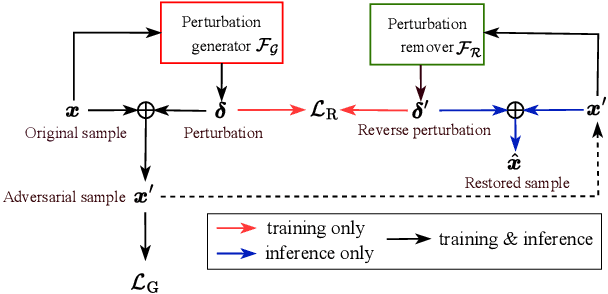
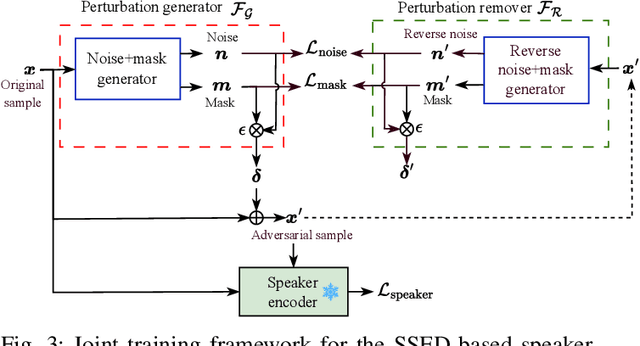
Neural networks are commonly known to be vulnerable to adversarial attacks mounted through subtle perturbation on the input data. Recent development in voice-privacy protection has shown the positive use cases of the same technique to conceal speaker's voice attribute with additive perturbation signal generated by an adversarial network. This paper examines the reversibility property where an entity generating the adversarial perturbations is authorized to remove them and restore original speech (e.g., the speaker him/herself). A similar technique could also be used by an investigator to deanonymize a voice-protected speech to restore criminals' identities in security and forensic analysis. In this setting, the perturbation generative module is assumed to be known in the removal process. To this end, a joint training of perturbation generation and removal modules is proposed. Experimental results on the LibriSpeech dataset demonstrated that the subtle perturbations added to the original speech can be predicted from the anonymized speech while achieving the goal of privacy protection. By removing these perturbations from the anonymized sample, the original speech can be restored. Audio samples can be found in \url{https://voiceprivacy.github.io/Perturbation-Generation-Removal/}.
* 6 pages, 3 figures, published to IEEE SLT Workshop 2024
USTC-KXDIGIT System Description for ASVspoof5 Challenge
Sep 03, 2024
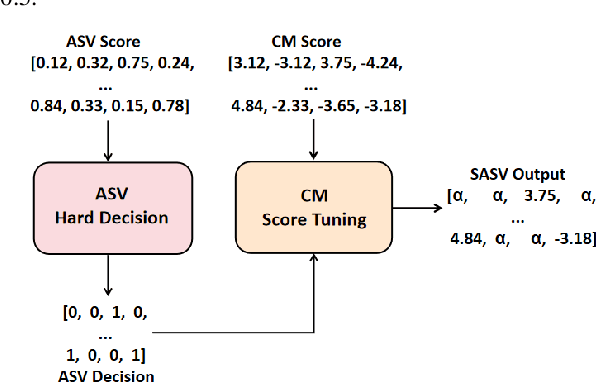
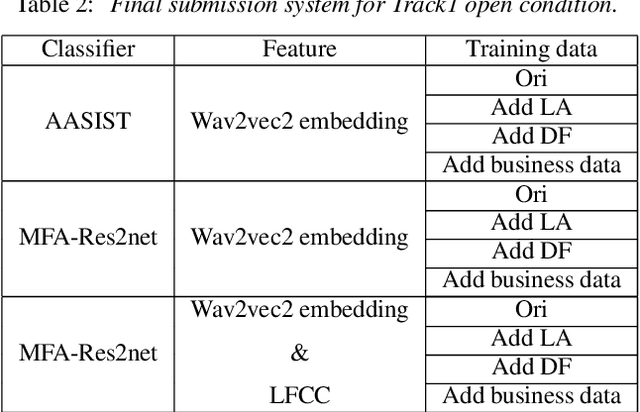
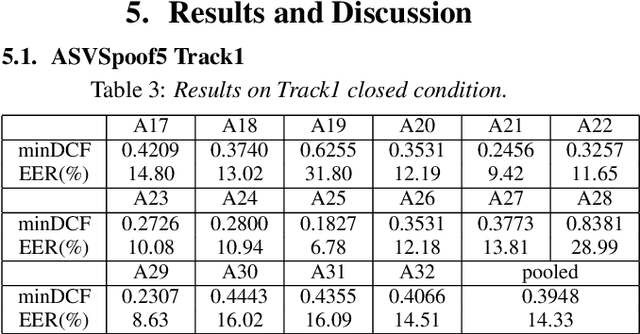
This paper describes the USTC-KXDIGIT system submitted to the ASVspoof5 Challenge for Track 1 (speech deepfake detection) and Track 2 (spoofing-robust automatic speaker verification, SASV). Track 1 showcases a diverse range of technical qualities from potential processing algorithms and includes both open and closed conditions. For these conditions, our system consists of a cascade of a frontend feature extractor and a back-end classifier. We focus on extensive embedding engineering and enhancing the generalization of the back-end classifier model. Specifically, the embedding engineering is based on hand-crafted features and speech representations from a self-supervised model, used for closed and open conditions, respectively. To detect spoof attacks under various adversarial conditions, we trained multiple systems on an augmented training set. Additionally, we used voice conversion technology to synthesize fake audio from genuine audio in the training set to enrich the synthesis algorithms. To leverage the complementary information learned by different model architectures, we employed activation ensemble and fused scores from different systems to obtain the final decision score for spoof detection. During the evaluation phase, the proposed methods achieved 0.3948 minDCF and 14.33% EER in the close condition, and 0.0750 minDCF and 2.59% EER in the open condition, demonstrating the robustness of our submitted systems under adversarial conditions. In Track 2, we continued using the CM system from Track 1 and fused it with a CNN-based ASV system. This approach achieved 0.2814 min-aDCF in the closed condition and 0.0756 min-aDCF in the open condition, showcasing superior performance in the SASV system.
FaMeSumm: Investigating and Improving Faithfulness of Medical Summarization
Nov 08, 2023



Summaries of medical text shall be faithful by being consistent and factual with source inputs, which is an important but understudied topic for safety and efficiency in healthcare. In this paper, we investigate and improve faithfulness in summarization on a broad range of medical summarization tasks. Our investigation reveals that current summarization models often produce unfaithful outputs for medical input text. We then introduce FaMeSumm, a framework to improve faithfulness by fine-tuning pre-trained language models based on medical knowledge. FaMeSumm performs contrastive learning on designed sets of faithful and unfaithful summaries, and it incorporates medical terms and their contexts to encourage faithful generation of medical terms. We conduct comprehensive experiments on three datasets in two languages: health question and radiology report summarization datasets in English, and a patient-doctor dialogue dataset in Chinese. Results demonstrate that FaMeSumm is flexible and effective by delivering consistent improvements over mainstream language models such as BART, T5, mT5, and PEGASUS, yielding state-of-the-art performances on metrics for faithfulness and general quality. Human evaluation by doctors also shows that FaMeSumm generates more faithful outputs. Our code is available at https://github.com/psunlpgroup/FaMeSumm .
Pre-training Language Model as a Multi-perspective Course Learner
May 06, 2023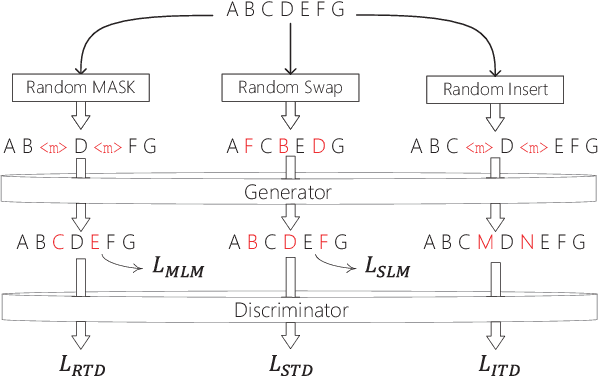

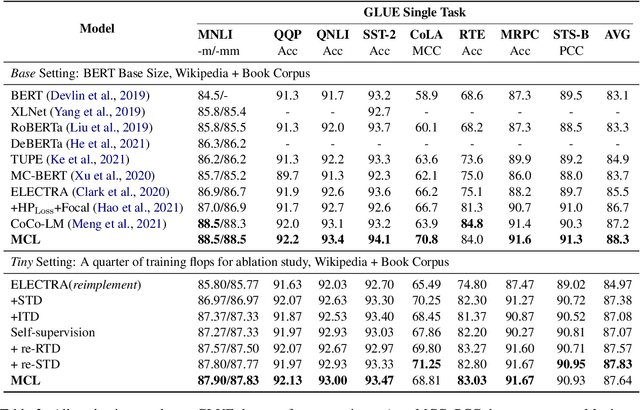
ELECTRA, the generator-discriminator pre-training framework, has achieved impressive semantic construction capability among various downstream tasks. Despite the convincing performance, ELECTRA still faces the challenges of monotonous training and deficient interaction. Generator with only masked language modeling (MLM) leads to biased learning and label imbalance for discriminator, decreasing learning efficiency; no explicit feedback loop from discriminator to generator results in the chasm between these two components, underutilizing the course learning. In this study, a multi-perspective course learning (MCL) method is proposed to fetch a many degrees and visual angles for sample-efficient pre-training, and to fully leverage the relationship between generator and discriminator. Concretely, three self-supervision courses are designed to alleviate inherent flaws of MLM and balance the label in a multi-perspective way. Besides, two self-correction courses are proposed to bridge the chasm between the two encoders by creating a "correction notebook" for secondary-supervision. Moreover, a course soups trial is conducted to solve the "tug-of-war" dynamics problem of MCL, evolving a stronger pre-trained model. Experimental results show that our method significantly improves ELECTRA's average performance by 2.8% and 3.2% absolute points respectively on GLUE and SQuAD 2.0 benchmarks, and overshadows recent advanced ELECTRA-style models under the same settings. The pre-trained MCL model is available at https://huggingface.co/McmanusChen/MCL-base.
Language-Universal Adapter Learning with Knowledge Distillation for End-to-End Multilingual Speech Recognition
Feb 28, 2023
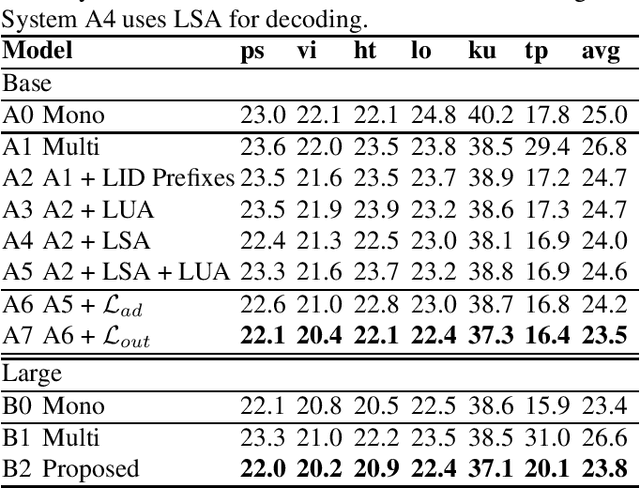

In this paper, we propose a language-universal adapter learning framework based on a pre-trained model for end-to-end multilingual automatic speech recognition (ASR). For acoustic modeling, the wav2vec 2.0 pre-trained model is fine-tuned by inserting language-specific and language-universal adapters. An online knowledge distillation is then used to enable the language-universal adapters to learn both language-specific and universal features. The linguistic information confusion is also reduced by leveraging language identifiers (LIDs). With LIDs we perform a position-wise modification on the multi-head attention outputs. In the inference procedure, the language-specific adapters are removed while the language-universal adapters are kept activated. The proposed method improves the recognition accuracy and addresses the linear increase of the number of adapters' parameters with the number of languages in common multilingual ASR systems. Experiments on the BABEL dataset confirm the effectiveness of the proposed framework. Compared to the conventional multilingual model, a 3.3% absolute error rate reduction is achieved. The code is available at: https://github.com/shen9712/UniversalAdapterLearning.
WIDER & CLOSER: Mixture of Short-channel Distillers for Zero-shot Cross-lingual Named Entity Recognition
Dec 07, 2022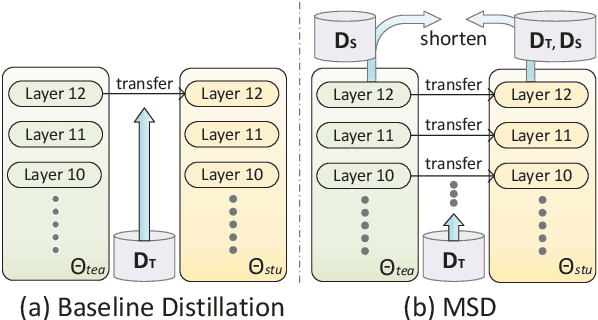
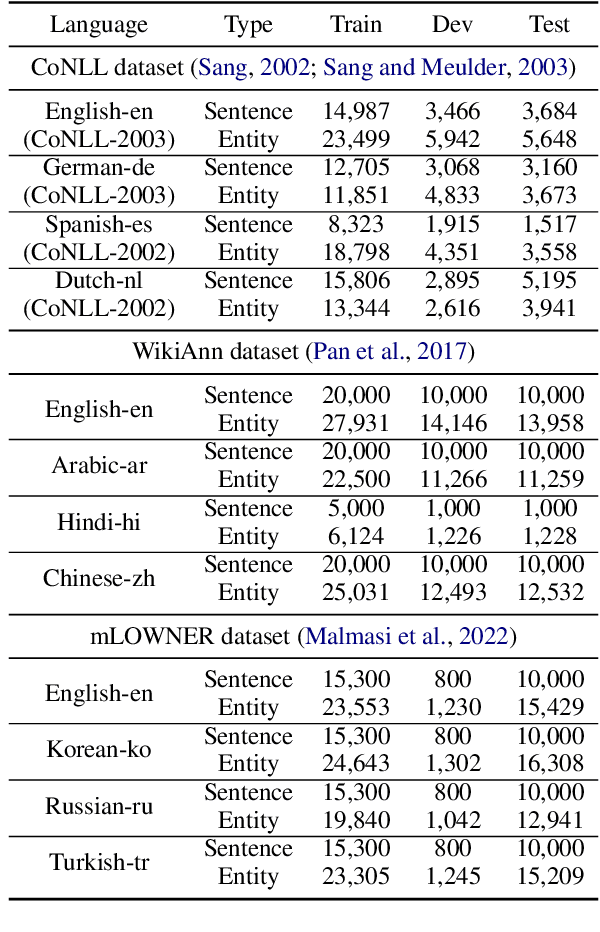
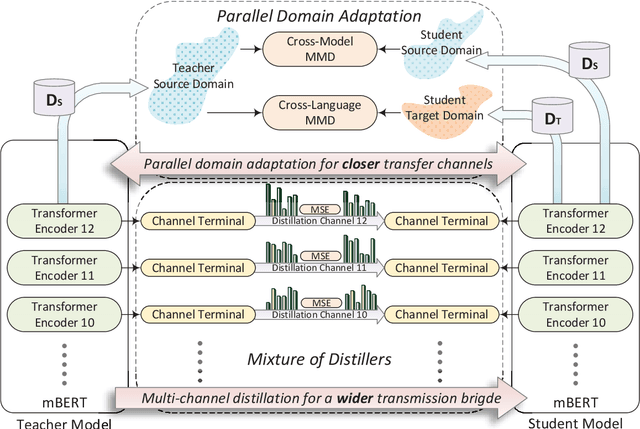
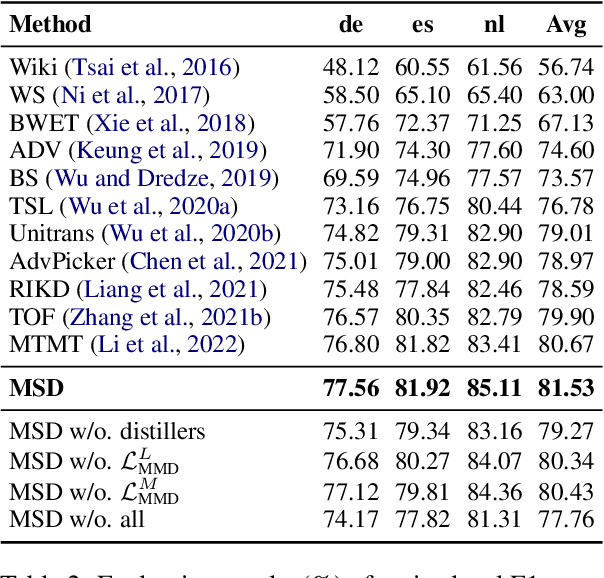
Zero-shot cross-lingual named entity recognition (NER) aims at transferring knowledge from annotated and rich-resource data in source languages to unlabeled and lean-resource data in target languages. Existing mainstream methods based on the teacher-student distillation framework ignore the rich and complementary information lying in the intermediate layers of pre-trained language models, and domain-invariant information is easily lost during transfer. In this study, a mixture of short-channel distillers (MSD) method is proposed to fully interact the rich hierarchical information in the teacher model and to transfer knowledge to the student model sufficiently and efficiently. Concretely, a multi-channel distillation framework is designed for sufficient information transfer by aggregating multiple distillers as a mixture. Besides, an unsupervised method adopting parallel domain adaptation is proposed to shorten the channels between the teacher and student models to preserve domain-invariant features. Experiments on four datasets across nine languages demonstrate that the proposed method achieves new state-of-the-art performance on zero-shot cross-lingual NER and shows great generalization and compatibility across languages and fields.
Feature Aggregation in Zero-Shot Cross-Lingual Transfer Using Multilingual BERT
May 17, 2022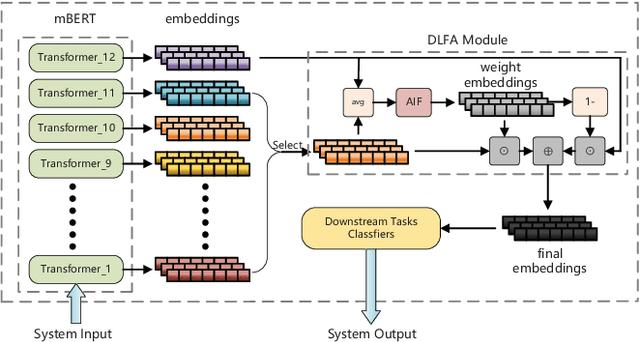
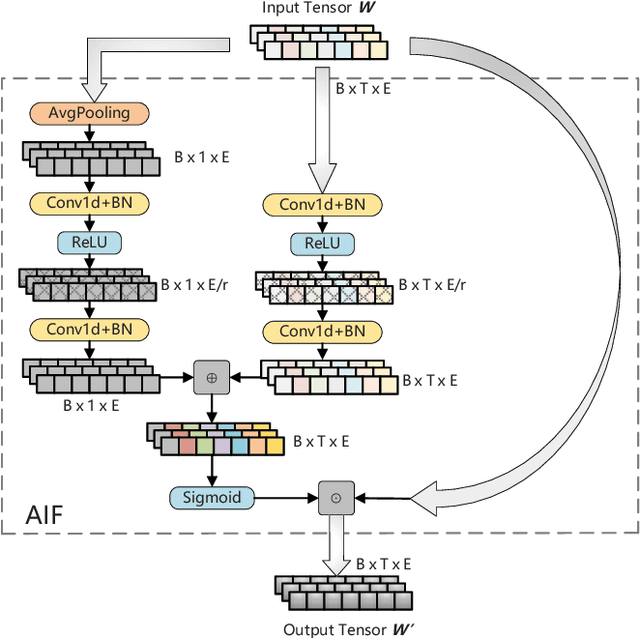
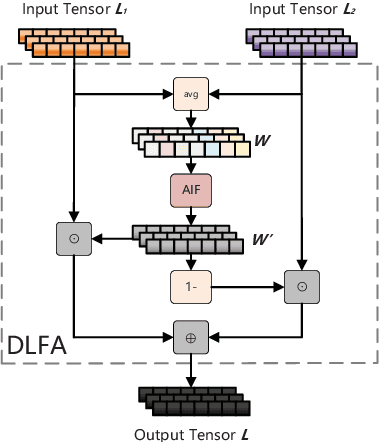
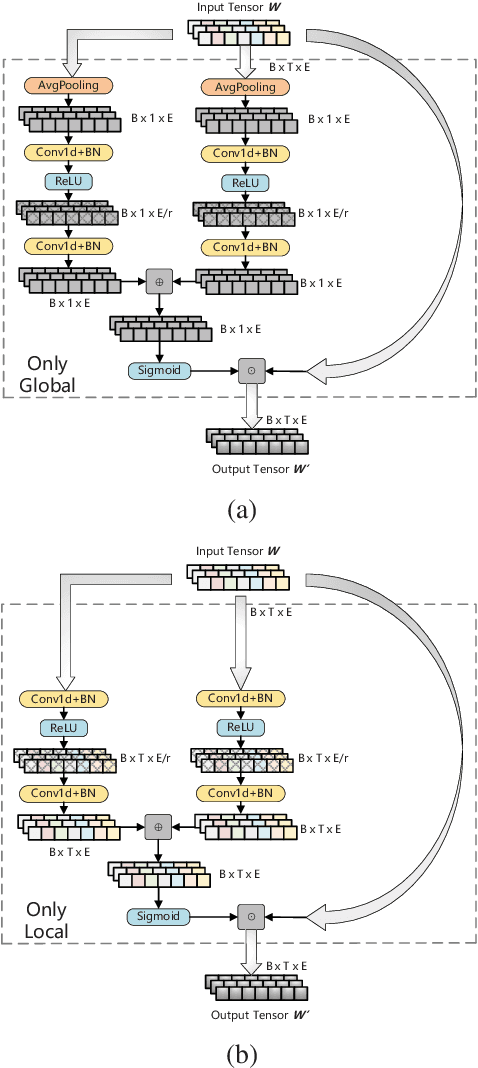
Multilingual BERT (mBERT), a language model pre-trained on large multilingual corpora, has impressive zero-shot cross-lingual transfer capabilities and performs surprisingly well on zero-shot POS tagging and Named Entity Recognition (NER), as well as on cross-lingual model transfer. At present, the mainstream methods to solve the cross-lingual downstream tasks are always using the last transformer layer's output of mBERT as the representation of linguistic information. In this work, we explore the complementary property of lower layers to the last transformer layer of mBERT. A feature aggregation module based on an attention mechanism is proposed to fuse the information contained in different layers of mBERT. The experiments are conducted on four zero-shot cross-lingual transfer datasets, and the proposed method obtains performance improvements on key multilingual benchmark tasks XNLI (+1.5 %), PAWS-X (+2.4 %), NER (+1.2 F1), and POS (+1.5 F1). Through the analysis of the experimental results, we prove that the layers before the last layer of mBERT can provide extra useful information for cross-lingual downstream tasks and explore the interpretability of mBERT empirically.
USTC-NELSLIP at SemEval-2022 Task 11: Gazetteer-Adapted Integration Network for Multilingual Complex Named Entity Recognition
Mar 07, 2022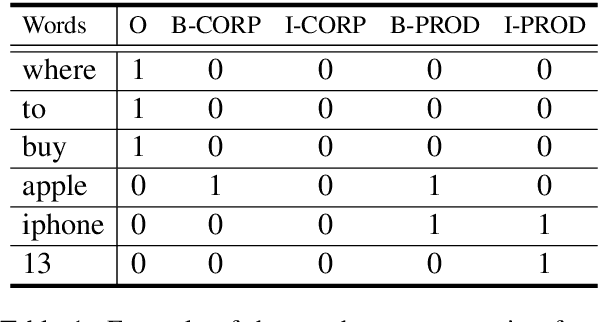

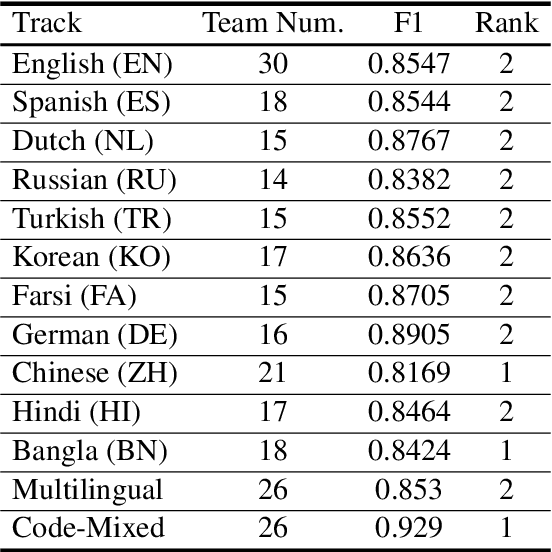
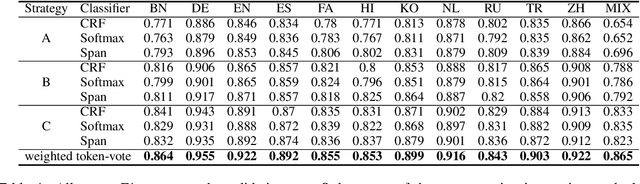
This paper describes the system developed by the USTC-NELSLIP team for SemEval-2022 Task 11 Multilingual Complex Named Entity Recognition (MultiCoNER). We propose a gazetteer-adapted integration network (GAIN) to improve the performance of language models for recognizing complex named entities. The method first adapts the representations of gazetteer networks to those of language models by minimizing the KL divergence between them. After adaptation, these two networks are then integrated for backend supervised named entity recognition (NER) training. The proposed method is applied to several state-of-the-art Transformer-based NER models with a gazetteer built from Wikidata, and shows great generalization ability across them. The final predictions are derived from an ensemble of these trained models. Experimental results and detailed analysis verify the effectiveness of the proposed method. The official results show that our system ranked 1st on three tracks (Chinese, Code-mixed and Bangla) and 2nd on the other ten tracks in this task.
Multi-Level Contrastive Learning for Cross-Lingual Alignment
Feb 26, 2022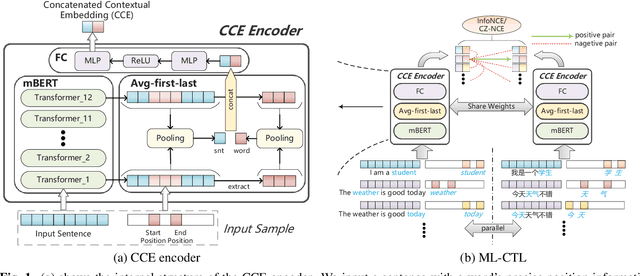
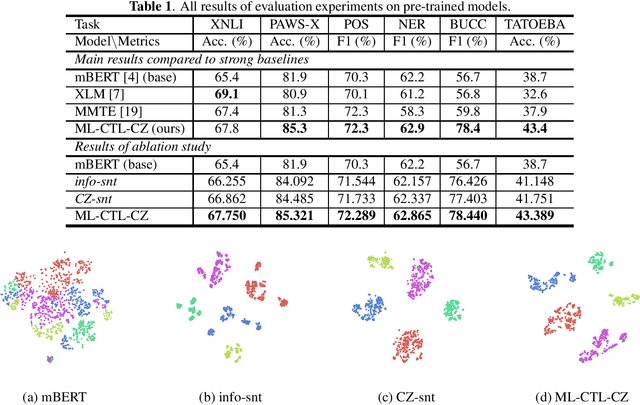
Cross-language pre-trained models such as multilingual BERT (mBERT) have achieved significant performance in various cross-lingual downstream NLP tasks. This paper proposes a multi-level contrastive learning (ML-CTL) framework to further improve the cross-lingual ability of pre-trained models. The proposed method uses translated parallel data to encourage the model to generate similar semantic embeddings for different languages. However, unlike the sentence-level alignment used in most previous studies, in this paper, we explicitly integrate the word-level information of each pair of parallel sentences into contrastive learning. Moreover, cross-zero noise contrastive estimation (CZ-NCE) loss is proposed to alleviate the impact of the floating-point error in the training process with a small batch size. The proposed method significantly improves the cross-lingual transfer ability of our basic model (mBERT) and outperforms on multiple zero-shot cross-lingual downstream tasks compared to the same-size models in the Xtreme benchmark.