 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream-Voice-Anon: Enhancing Utility of Real-Time Speaker Anonymization via Neural Audio Codec and Language Models
Jan 20, 2026Protecting speaker identity is crucial for online voice applications, yet streaming speaker anonymization (SA) remains underexplored. Recent research has demonstrated that neural audio codec (NAC) provides superior speaker feature disentanglement and linguistic fidelity. NAC can also be used with causal language models (LM) to enhance linguistic fidelity and prompt control for streaming tasks. However, existing NAC-based online LM systems are designed for voice conversion (VC) rather than anonymization, lacking the techniques required for privacy protection. Building on these advances, we present Stream-Voice-Anon, which adapts modern causal LM-based NAC architectures specifically for streaming SA by integrating anonymization techniques. Our anonymization approach incorporates pseudo-speaker representation sampling, a speaker embedding mixing and diverse prompt selection strategies for LM conditioning that leverage the disentanglement properties of quantized content codes to prevent speaker information leakage. Additionally, we compare dynamic and fixed delay configurations to explore latency-privacy trade-offs in real-time scenarios. Under the VoicePrivacy 2024 Challenge protocol, Stream-Voice-Anon achieves substantial improvements in intelligibility (up to 46% relative WER reduction) and emotion preservation (up to 28% UAR relative) compared to the previous state-of-the-art streaming method DarkStream while maintaining comparable latency (180ms vs 200ms) and privacy protection against lazy-informed attackers, though showing 15% relative degradation against semi-informed attackers.
ASVspoof 5: Evaluation of Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Jan 07, 2026ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake detection solutions. A significant change from previous challenge editions is a new crowdsourced database collected from a substantially greater number of speakers under diverse recording conditions, and a mix of cutting-edge and legacy generative speech technology. With the new database described elsewhere, we provide in this paper an overview of the ASVspoof 5 challenge results for the submissions of 53 participating teams. While many solutions perform well, performance degrades under adversarial attacks and the application of neural encoding/compression schemes. Together with a review of post-challenge results, we also report a study of calibration in addition to other principal challenges and outline a road-map for the future of ASVspoof.
IDMap: A Pseudo-Speaker Generator Framework Based on Speaker Identity Index to Vector Mapping
Nov 09, 2025Facilitated by the speech generation framework that disentangles speech into content, speaker, and prosody, voice anonymization is accomplished by substituting the original speaker embedding vector with that of a pseudo-speaker. In this framework, the pseudo-speaker generation forms a fundamental challenge. Current pseudo-speaker generation methods demonstrate limitations in the uniqueness of pseudo-speakers, consequently restricting their effectiveness in voice privacy protection. Besides, existing model-based methods suffer from heavy computation costs. Especially, in the large-scale scenario where a huge number of pseudo-speakers are generated, the limitations of uniqueness and computational inefficiency become more significant. To this end, this paper proposes a framework for pseudo-speaker generation, which establishes a mapping from speaker identity index to speaker vector in the feedforward architecture, termed IDMap. Specifically, the framework is specified into two models: IDMap-MLP and IDMap-Diff. Experiments were conducted on both small- and large-scale evaluation datasets. Small-scale evaluations on the LibriSpeech dataset validated the effectiveness of the proposed IDMap framework in enhancing the uniqueness of pseudo-speakers, thereby improving voice privacy protection, while at a reduced computational cost. Large-scale evaluations on the MLS and Common Voice datasets further justified the superiority of the IDMap framework regarding the stability of the voice privacy protection capability as the number of pseudo-speakers increased. Audio samples and open-source code can be found in https://github.com/VoicePrivacy/IDMap.
A Study of the Removability of Speaker-Adversarial Perturbations
Oct 10, 2025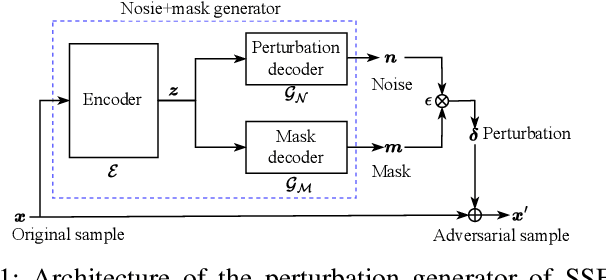
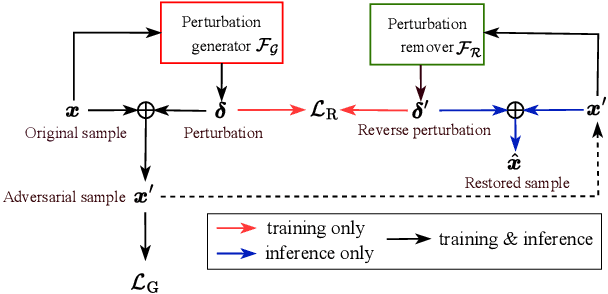
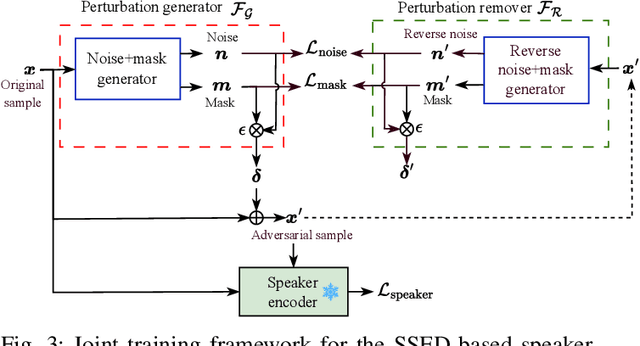

Recent advancements in adversarial attacks have demonstrated their effectiveness in misleading speaker recognition models, making wrong predictions about speaker identities. On the other hand, defense techniques against speaker-adversarial attacks focus on reducing the effects of speaker-adversarial perturbations on speaker attribute extraction. These techniques do not seek to fully remove the perturbations and restore the original speech. To this end, this paper studies the removability of speaker-adversarial perturbations. Specifically, the investigation is conducted assuming various degrees of awareness of the perturbation generator across three scenarios: ignorant, semi-informed, and well-informed. Besides, we consider both the optimization-based and feedforward perturbation generation methods. Experiments conducted on the LibriSpeech dataset demonstrated that: 1) in the ignorant scenario, speaker-adversarial perturbations cannot be eliminated, although their impact on speaker attribute extraction is reduced, 2) in the semi-informed scenario, the speaker-adversarial perturbations cannot be fully removed, while those generated by the feedforward model can be considerably reduced, and 3) in the well-informed scenario, speaker-adversarial perturbations are nearly eliminated, allowing for the restoration of the original speech. Audio samples can be found in https://voiceprivacy.github.io/Perturbation-Generation-Removal/.
Pinhole Effect on Linkability and Dispersion in Speaker Anonymization
Aug 23, 2025Speaker anonymization aims to conceal speaker-specific attributes in speech signals, making the anonymized speech unlinkable to the original speaker identity. Recent approaches achieve this by disentangling speech into content and speaker components, replacing the latter with pseudo speakers. The anonymized speech can be mapped either to a common pseudo speaker shared across utterances or to distinct pseudo speakers unique to each utterance. This paper investigates the impact of these mapping strategies on three key dimensions: speaker linkability, dispersion in the anonymized speaker space, and de-identification from the original identity. Our findings show that using distinct pseudo speakers increases speaker dispersion and reduces linkability compared to common pseudo-speaker mapping, thereby enhancing privacy preservation. These observations are interpreted through the proposed pinhole effect, a conceptual framework introduced to explain the relationship between mapping strategies and anonymization performance. The hypothesis is validated through empirical evaluation.
Subband Architecture Aided Selective Fixed-Filter Active Noise Control
Aug 01, 2025The feedforward selective fixed-filter method selects the most suitable pre-trained control filter based on the spectral features of the detected reference signal, effectively avoiding slow convergence in conventional adaptive algorithms. However, it can only handle limited types of noises, and the performance degrades when the input noise exhibits non-uniform power spectral density. To address these limitations, this paper devises a novel selective fixed-filter scheme based on a delayless subband structure. In the off-line training stage, subband control filters are pre-trained for different frequency ranges and stored in a dedicated sub-filter database. During the on-line control stage, the incoming noise is decomposed using a polyphase FFT filter bank, and a frequency-band-matching mechanism assigns each subband signal the most appropriate control filter. Subsequently, a weight stacking technique is employed to combine all subband weights into a fullband filter, enabling real-time noise suppression. Experimental results demonstrate that the proposed scheme provides fast convergence, effective noise reduction, and strong robustness in handling more complicated noisy environments.
Bayesian Learning for Domain-Invariant Speaker Verification and Anti-Spoofing
Jun 09, 2025The performance of automatic speaker verification (ASV) and anti-spoofing drops seriously under real-world domain mismatch conditions. The relaxed instance frequency-wise normalization (RFN), which normalizes the frequency components based on the feature statistics along the time and channel axes, is a promising approach to reducing the domain dependence in the feature maps of a speaker embedding network. We advocate that the different frequencies should receive different weights and that the weights' uncertainty due to domain shift should be accounted for. To these ends, we propose leveraging variational inference to model the posterior distribution of the weights, which results in Bayesian weighted RFN (BWRFN). This approach overcomes the limitations of fixed-weight RFN, making it more effective under domain mismatch conditions. Extensive experiments on cross-dataset ASV, cross-TTS anti-spoofing, and spoofing-robust ASV show that BWRFN is significantly better than WRFN and RFN.
Introducing voice timbre attribute detection
May 14, 2025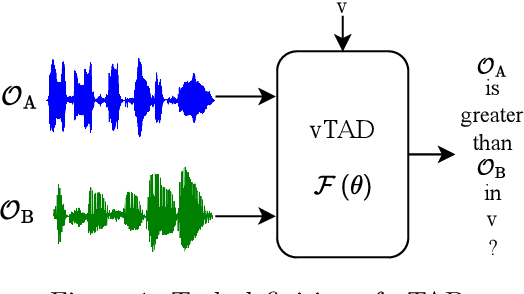
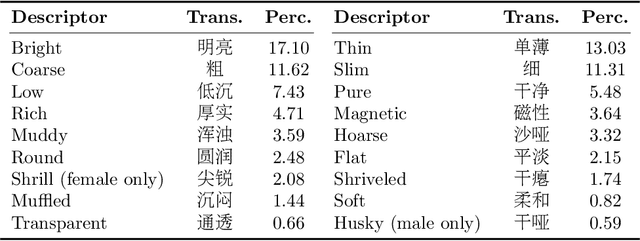
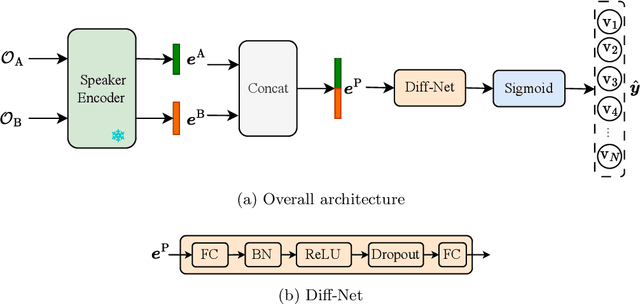
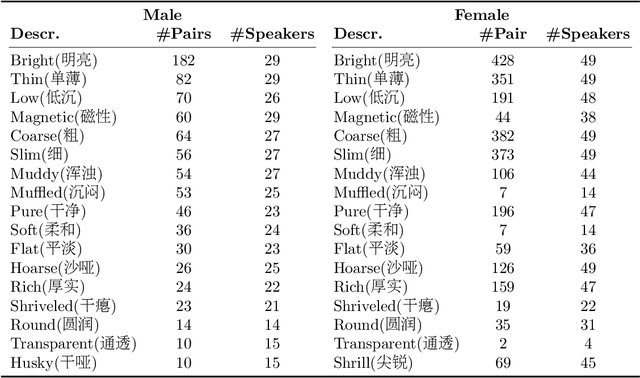
This paper focuses on explaining the timbre conveyed by speech signals and introduces a task termed voice timbre attribute detection (vTAD). In this task, voice timbre is explained with a set of sensory attributes describing its human perception. A pair of speech utterances is processed, and their intensity is compared in a designated timbre descriptor. Moreover, a framework is proposed, which is built upon the speaker embeddings extracted from the speech utterances. The investigation is conducted on the VCTK-RVA dataset. Experimental examinations on the ECAPA-TDNN and FACodec speaker encoders demonstrated that: 1) the ECAPA-TDNN speaker encoder was more capable in the seen scenario, where the testing speakers were included in the training set; 2) the FACodec speaker encoder was superior in the unseen scenario, where the testing speakers were not part of the training, indicating enhanced generalization capability. The VCTK-RVA dataset and open-source code are available on the website https://github.com/vTAD2025-Challenge/vTAD.
The Voice Timbre Attribute Detection 2025 Challenge Evaluation Plan
May 14, 2025Voice timbre refers to the unique quality or character of a person's voice that distinguishes it from others as perceived by human hearing. The Voice Timbre Attribute Detection (VtaD) 2025 challenge focuses on explaining the voice timbre attribute in a comparative manner. In this challenge, the human impression of voice timbre is verbalized with a set of sensory descriptors, including bright, coarse, soft, magnetic, and so on. The timbre is explained from the comparison between two voices in their intensity within a specific descriptor dimension. The VtaD 2025 challenge starts in May and culminates in a special proposal at the NCMMSC2025 conference in October 2025 in Zhenjiang, China.
Nes2Net: A Lightweight Nested Architecture for Foundation Model Driven Speech Anti-spoofing
Apr 08, 2025Speech foundation models have significantly advanced various speech-related tasks by providing exceptional representation capabilities. However, their high-dimensional output features often create a mismatch with downstream task models, which typically require lower-dimensional inputs. A common solution is to apply a dimensionality reduction (DR) layer, but this approach increases parameter overhead, computational costs, and risks losing valuable information. To address these issues, we propose Nested Res2Net (Nes2Net), a lightweight back-end architecture designed to directly process high-dimensional features without DR layers. The nested structure enhances multi-scale feature extraction, improves feature interaction, and preserves high-dimensional information. We first validate Nes2Net on CtrSVDD, a singing voice deepfake detection dataset, and report a 22% performance improvement and an 87% back-end computational cost reduction over the state-of-the-art baseline. Additionally, extensive testing across four diverse datasets: ASVspoof 2021, ASVspoof 5, PartialSpoof, and In-the-Wild, covering fully spoofed speech, adversarial attacks, partial spoofing, and real-world scenarios, consistently highlights Nes2Net's superior robustness and generalization capabilities. The code package and pre-trained models are available at https://github.com/Liu-Tianchi/Nes2Net.