 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRAF: Interference-Resilient Adaptive Fusion for Noise-Robust End-to-End Full-Duplex Spoken Dialogue Systems
Jun 04, 2026Full-duplex spoken dialogue models allow voice agents to listen and speak concurrently, enabling natural interaction with real-time overlap. However, end-to-end dual-channel models that jointly encode user and agent streams may degrade in realistic acoustic environments: interfering speakers leaking into the user microphone can be encoded as part of the user query, corrupting the LLM's conditioning and causing unstable turn-taking and reduced response quality. We propose Interference-Resilient Adaptive Fusion (IRAF), a lightweight, streaming-compatible module that modulates the contribution of user audio to the LLM frame by frame. IRAF predicts a scalar reliability gate from target-speaker and user audio embeddings and rescales user representations before fusion with agent embeddings. Experiments on MS-MARCO and InstructS2S-200K show consistent gains in response quality and full-duplex interaction under interfering-speaker conditions.
Privacy-Preserving End-to-End Full-Duplex Speech Dialogue Models
Mar 09, 2026End-to-end full-duplex speech models feed user audio through an always-on LLM backbone, yet the speaker privacy implications of their hidden representations remain unexamined. Following the VoicePrivacy 2024 protocol with a lazy-informed attacker, we show that the hidden states of SALM-Duplex and Moshi leak substantial speaker identity across all transformer layers. Layer-wise and turn-wise analyses reveal that leakage persists across all layers, with SALM-Duplex showing stronger leakage in early layers while Moshi leaks uniformly, and that Linkability rises sharply within the first few turns. We propose two streaming anonymization setups using Stream-Voice-Anon: a waveform-level front-end (Anon-W2W) and a feature-domain replacement (Anon-W2F). Anon-W2F raises EER by over 3.5x relative to the discrete encoder baseline (11.2% to 41.0%), approaching the 50% random-chance ceiling, while Anon-W2W retains 78-93% of baseline sBERT across setups with sub-second response latency (FRL under 0.8 s).
Stream-Voice-Anon: Enhancing Utility of Real-Time Speaker Anonymization via Neural Audio Codec and Language Models
Jan 20, 2026Protecting speaker identity is crucial for online voice applications, yet streaming speaker anonymization (SA) remains underexplored. Recent research has demonstrated that neural audio codec (NAC) provides superior speaker feature disentanglement and linguistic fidelity. NAC can also be used with causal language models (LM) to enhance linguistic fidelity and prompt control for streaming tasks. However, existing NAC-based online LM systems are designed for voice conversion (VC) rather than anonymization, lacking the techniques required for privacy protection. Building on these advances, we present Stream-Voice-Anon, which adapts modern causal LM-based NAC architectures specifically for streaming SA by integrating anonymization techniques. Our anonymization approach incorporates pseudo-speaker representation sampling, a speaker embedding mixing and diverse prompt selection strategies for LM conditioning that leverage the disentanglement properties of quantized content codes to prevent speaker information leakage. Additionally, we compare dynamic and fixed delay configurations to explore latency-privacy trade-offs in real-time scenarios. Under the VoicePrivacy 2024 Challenge protocol, Stream-Voice-Anon achieves substantial improvements in intelligibility (up to 46% relative WER reduction) and emotion preservation (up to 28% UAR relative) compared to the previous state-of-the-art streaming method DarkStream while maintaining comparable latency (180ms vs 200ms) and privacy protection against lazy-informed attackers, though showing 15% relative degradation against semi-informed attackers.
HoverAI: An Embodied Aerial Agent for Natural Human-Drone Interaction
Jan 20, 2026Drones operating in human-occupied spaces suffer from insufficient communication mechanisms that create uncertainty about their intentions. We present HoverAI, an embodied aerial agent that integrates drone mobility, infrastructure-independent visual projection, and real-time conversational AI into a unified platform. Equipped with a MEMS laser projector, onboard semi-rigid screen, and RGB camera, HoverAI perceives users through vision and voice, responding via lip-synced avatars that adapt appearance to user demographics. The system employs a multimodal pipeline combining VAD, ASR (Whisper), LLM-based intent classification, RAG for dialogue, face analysis for personalization, and voice synthesis (XTTS v2). Evaluation demonstrates high accuracy in command recognition (F1: 0.90), demographic estimation (gender F1: 0.89, age MAE: 5.14 years), and speech transcription (WER: 0.181). By uniting aerial robotics with adaptive conversational AI and self-contained visual output, HoverAI introduces a new class of spatially-aware, socially responsive embodied agents for applications in guidance, assistance, and human-centered interaction.
NTU-NPU System for Voice Privacy 2024 Challenge
Oct 03, 2024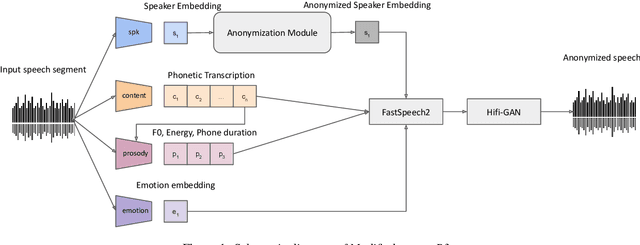

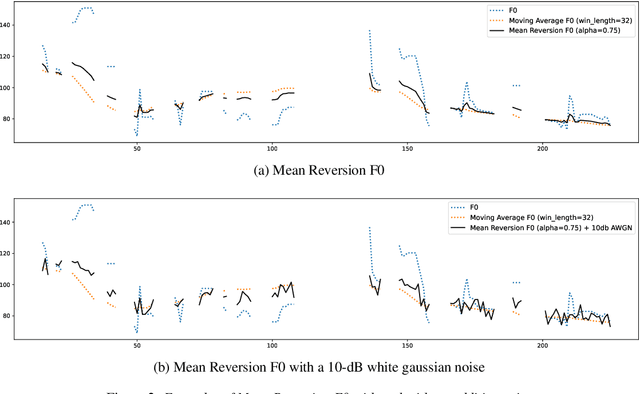
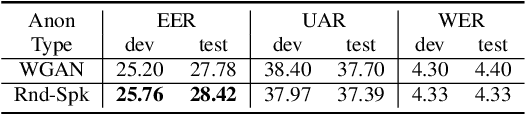
In this work, we describe our submissions for the Voice Privacy Challenge 2024. Rather than proposing a novel speech anonymization system, we enhance the provided baselines to meet all required conditions and improve evaluated metrics. Specifically, we implement emotion embedding and experiment with WavLM and ECAPA2 speaker embedders for the B3 baseline. Additionally, we compare different speaker and prosody anonymization techniques. Furthermore, we introduce Mean Reversion F0 for B5, which helps to enhance privacy without a loss in utility. Finally, we explore disentanglement models, namely $\beta$-VAE and NaturalSpeech3 FACodec.
NPU-NTU System for Voice Privacy 2024 Challenge
Sep 06, 2024

Speaker anonymization is an effective privacy protection solution that conceals the speaker's identity while preserving the linguistic content and paralinguistic information of the original speech. To establish a fair benchmark and facilitate comparison of speaker anonymization systems, the VoicePrivacy Challenge (VPC) was held in 2020 and 2022, with a new edition planned for 2024. In this paper, we describe our proposed speaker anonymization system for VPC 2024. Our system employs a disentangled neural codec architecture and a serial disentanglement strategy to gradually disentangle the global speaker identity and time-variant linguistic content and paralinguistic information. We introduce multiple distillation methods to disentangle linguistic content, speaker identity, and emotion. These methods include semantic distillation, supervised speaker distillation, and frame-level emotion distillation. Based on these distillations, we anonymize the original speaker identity using a weighted sum of a set of candidate speaker identities and a randomly generated speaker identity. Our system achieves the best trade-off of privacy protection and emotion preservation in VPC 2024.
Probabilistic Back-ends for Online Speaker Recognition and Clustering
Feb 19, 2023This paper focuses on multi-enrollment speaker recognition which naturally occurs in the task of online speaker clustering, and studies the properties of different scoring back-ends in this scenario. First, we show that popular cosine scoring suffers from poor score calibration with a varying number of enrollment utterances. Second, we propose a simple replacement for cosine scoring based on an extremely constrained version of probabilistic linear discriminant analysis (PLDA). The proposed model improves over the cosine scoring for multi-enrollment recognition while keeping the same performance in the case of one-to-one comparisons. Finally, we consider an online speaker clustering task where each step naturally involves multi-enrollment recognition. We propose an online clustering algorithm allowing us to take benefits from the PLDA model such as the ability to handle uncertainty and better score calibration. Our experiments demonstrate the effectiveness of the proposed algorithm.
Magnitude-aware Probabilistic Speaker Embeddings
Feb 28, 2022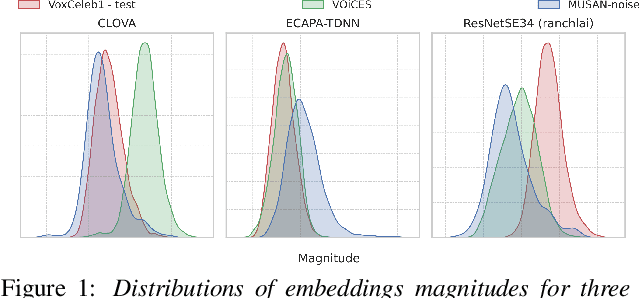


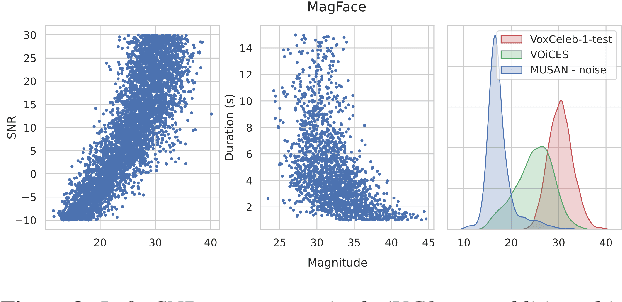
Recently, hyperspherical embeddings have established themselves as a dominant technique for face and voice recognition. Specifically, Euclidean space vector embeddings are learned to encode person-specific information in their direction while ignoring the magnitude. However, recent studies have shown that the magnitudes of the embeddings extracted by deep neural networks may indicate the quality of the corresponding inputs. This paper explores the properties of the magnitudes of the embeddings related to quality assessment and out-of-distribution detection. We propose a new probabilistic speaker embedding extractor using the information encoded in the embedding magnitude and leverage it in the speaker verification pipeline. We also propose several quality-aware diarization methods and incorporate the magnitudes in those. Our results indicate significant improvements over magnitude-agnostic baselines both in speaker verification and diarization tasks.