Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTU-NPU System for Voice Privacy 2024 Challenge
Paper and Code
Oct 03, 2024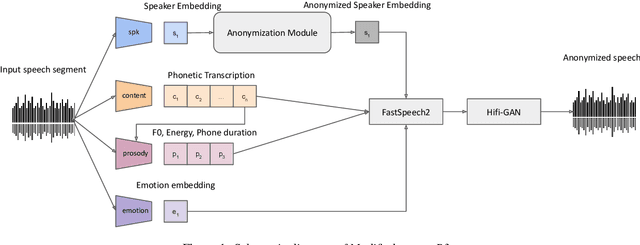

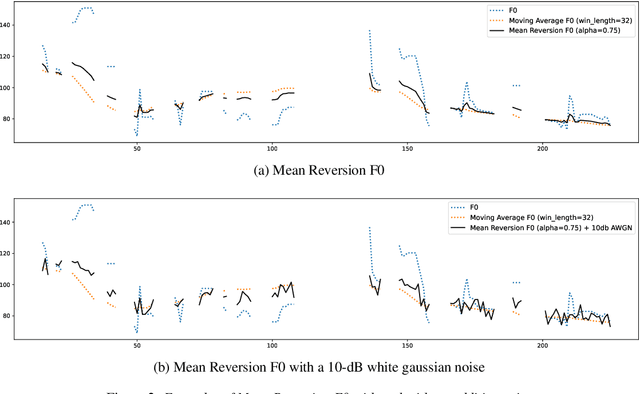
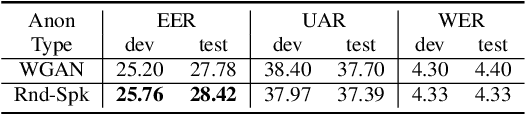
In this work, we describe our submissions for the Voice Privacy Challenge 2024. Rather than proposing a novel speech anonymization system, we enhance the provided baselines to meet all required conditions and improve evaluated metrics. Specifically, we implement emotion embedding and experiment with WavLM and ECAPA2 speaker embedders for the B3 baseline. Additionally, we compare different speaker and prosody anonymization techniques. Furthermore, we introduce Mean Reversion F0 for B5, which helps to enhance privacy without a loss in utility. Finally, we explore disentanglement models, namely $\beta$-VAE and NaturalSpeech3 FACodec.
* System description for VPC 2024
View paper on