 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR Challenge 2026: Robust Audio Deepfake Recognition under Media Transformations
May 10, 2026RADAR Challenge 2026 is an APSIPA Grand Challenge on Robust Audio Deepfake Recognition under Media Transformations, designed to simulate realistic media conditions in real-world audio distribution pipelines, including compression, resampling, noise, and reverberation. It consists of two phases: an English development phase with labeled data for analysis and paper writing, and a multilingual evaluation phase containing more than 100,000 utterances in English, Singapore English, Mandarin Chinese, Taiwanese Mandarin, Japanese, and Vietnamese. Systems are evaluated using equal error rate (EER) for binary real/fake classification. This paper describes the challenge task, the construction of the data set, the evaluation protocol, and the overall results. During the challenge, 33 teams submitted to the development phase and 22 teams submitted to the final evaluation phase. The reported results highlight the remaining challenges of robust audio deepfake detection under multilingual and media-transformed conditions.
WeDefense: A Toolkit to Defend Against Fake Audio
Jan 21, 2026The advances in generative AI have enabled the creation of synthetic audio which is perceptually indistinguishable from real, genuine audio. Although this stellar progress enables many positive applications, it also raises risks of misuse, such as for impersonation, disinformation and fraud. Despite a growing number of open-source fake audio detection codes released through numerous challenges and initiatives, most are tailored to specific competitions, datasets or models. A standardized and unified toolkit that supports the fair benchmarking and comparison of competing solutions with not just common databases, protocols, metrics, but also a shared codebase, is missing. To address this, we propose WeDefense, the first open-source toolkit to support both fake audio detection and localization. Beyond model training, WeDefense emphasizes critical yet often overlooked components: flexible input and augmentation, calibration, score fusion, standardized evaluation metrics, and analysis tools for deeper understanding and interpretation. The toolkit is publicly available at https://github.com/zlin0/wedefense with interactive demos for fake audio detection and localization.
NTU-NPU System for Voice Privacy 2024 Challenge
Oct 03, 2024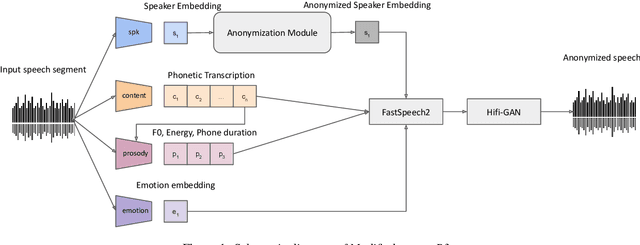

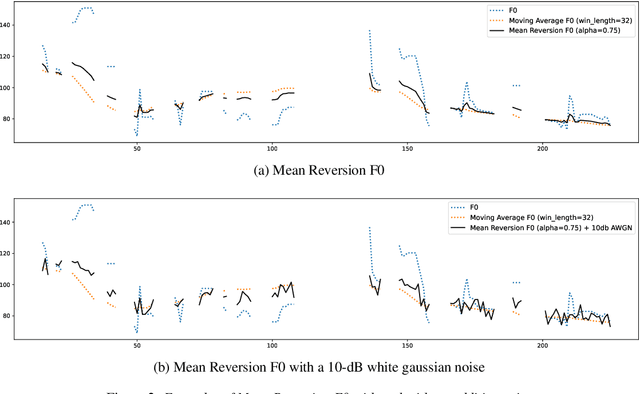
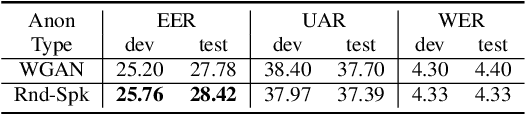
In this work, we describe our submissions for the Voice Privacy Challenge 2024. Rather than proposing a novel speech anonymization system, we enhance the provided baselines to meet all required conditions and improve evaluated metrics. Specifically, we implement emotion embedding and experiment with WavLM and ECAPA2 speaker embedders for the B3 baseline. Additionally, we compare different speaker and prosody anonymization techniques. Furthermore, we introduce Mean Reversion F0 for B5, which helps to enhance privacy without a loss in utility. Finally, we explore disentanglement models, namely $\beta$-VAE and NaturalSpeech3 FACodec.
Temporal-Channel Modeling in Multi-head Self-Attention for Synthetic Speech Detection
Jun 25, 2024Recent synthetic speech detectors leveraging the Transformer model have superior performance compared to the convolutional neural network counterparts. This improvement could be due to the powerful modeling ability of the multi-head self-attention (MHSA) in the Transformer model, which learns the temporal relationship of each input token. However, artifacts of synthetic speech can be located in specific regions of both frequency channels and temporal segments, while MHSA neglects this temporal-channel dependency of the input sequence. In this work, we proposed a Temporal-Channel Modeling (TCM) module to enhance MHSA's capability for capturing temporal-channel dependencies. Experimental results on the ASVspoof 2021 show that with only 0.03M additional parameters, the TCM module can outperform the state-of-the-art system by 9.25% in EER. Further ablation study reveals that utilizing both temporal and channel information yields the most improvement for detecting synthetic speech.
LaughNet: synthesizing laughter utterances from waveform silhouettes and a single laughter example
Oct 11, 2021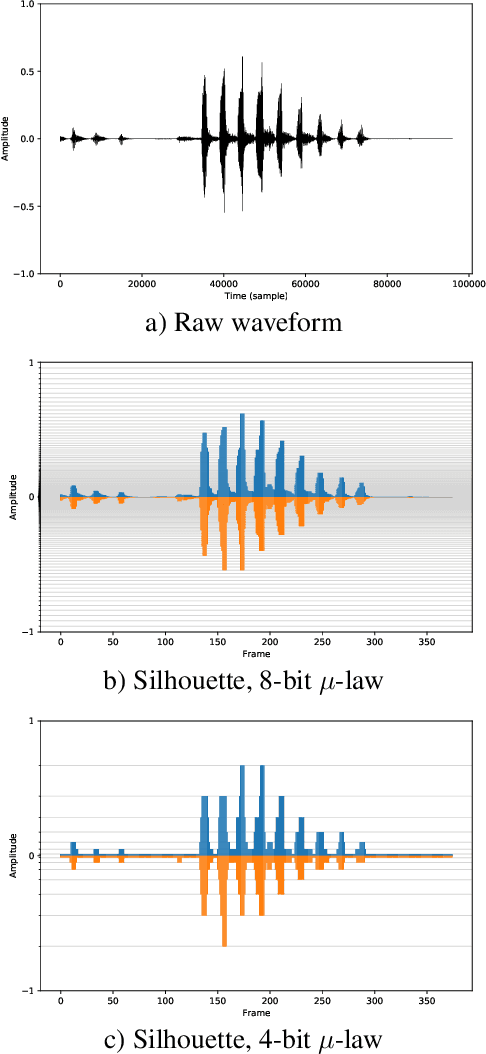
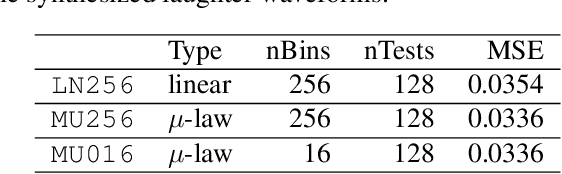
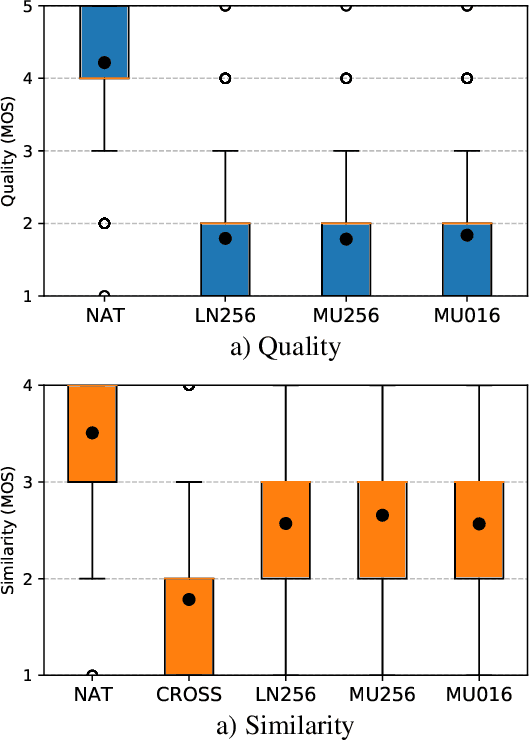
Emotional and controllable speech synthesis is a topic that has received much attention. However, most studies focused on improving the expressiveness and controllability in the context of linguistic content, even though natural verbal human communication is inseparable from spontaneous non-speech expressions such as laughter, crying, or grunting. We propose a model called LaughNet for synthesizing laughter by using waveform silhouettes as inputs. The motivation is not simply synthesizing new laughter utterances but testing a novel synthesis-control paradigm that uses an abstract representation of the waveform. We conducted basic listening test experiments, and the results showed that LaughNet can synthesize laughter utterances with moderate quality and retain the characteristics of the training example. More importantly, the generated waveforms have shapes similar to the input silhouettes. For future work, we will test the same method on other types of human nonverbal expressions and integrate it into more elaborated synthesis systems.
Preliminary study on using vector quantization latent spaces for TTS/VC systems with consistent performance
Jun 25, 2021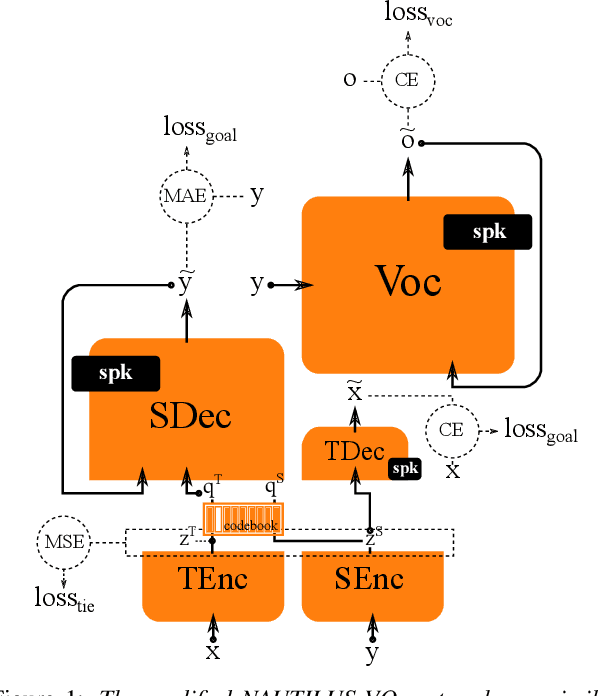
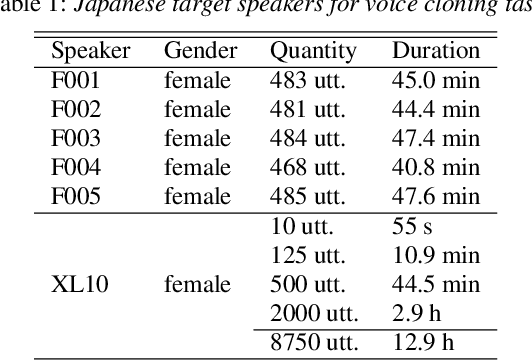
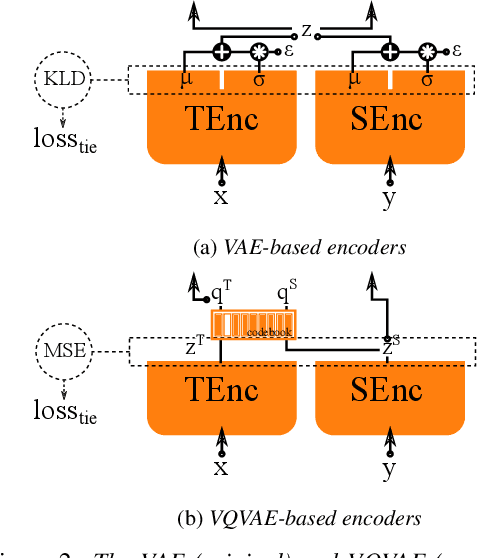
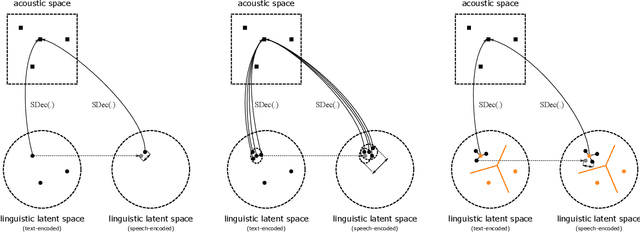
Generally speaking, the main objective when training a neural speech synthesis system is to synthesize natural and expressive speech from the output layer of the neural network without much attention given to the hidden layers. However, by learning useful latent representation, the system can be used for many more practical scenarios. In this paper, we investigate the use of quantized vectors to model the latent linguistic embedding and compare it with the continuous counterpart. By enforcing different policies over the latent spaces in the training, we are able to obtain a latent linguistic embedding that takes on different properties while having a similar performance in terms of quality and speaker similarity. Our experiments show that the voice cloning system built with vector quantization has only a small degradation in terms of perceptive evaluations, but has a discrete latent space that is useful for reducing the representation bit-rate, which is desirable for data transferring, or limiting the information leaking, which is important for speaker anonymization and other tasks of that nature.
Latent linguistic embedding for cross-lingual text-to-speech and voice conversion
Oct 08, 2020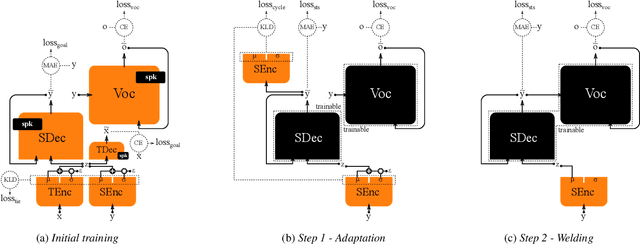
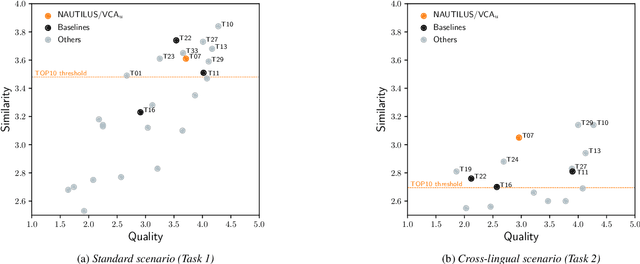
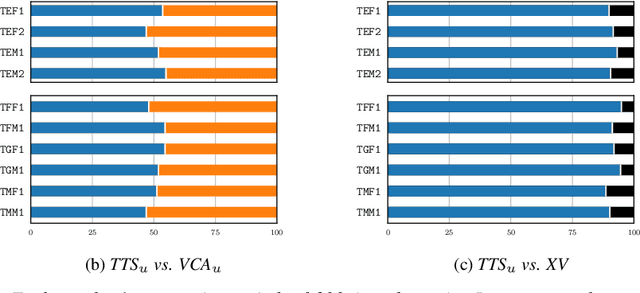
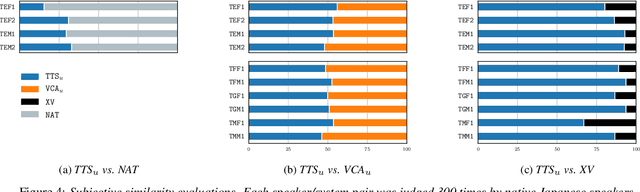
As the recently proposed voice cloning system, NAUTILUS, is capable of cloning unseen voices using untranscribed speech, we investigate the feasibility of using it to develop a unified cross-lingual TTS/VC system. Cross-lingual speech generation is the scenario in which speech utterances are generated with the voices of target speakers in a language not spoken by them originally. This type of system is not simply cloning the voice of the target speaker, but essentially creating a new voice that can be considered better than the original under a specific framing. By using a well-trained English latent linguistic embedding to create a cross-lingual TTS and VC system for several German, Finnish, and Mandarin speakers included in the Voice Conversion Challenge 2020, we show that our method not only creates cross-lingual VC with high speaker similarity but also can be seamlessly used for cross-lingual TTS without having to perform any extra steps. However, the subjective evaluations of perceived naturalness seemed to vary between target speakers, which is one aspect for future improvement.
NAUTILUS: a Versatile Voice Cloning System
May 22, 2020
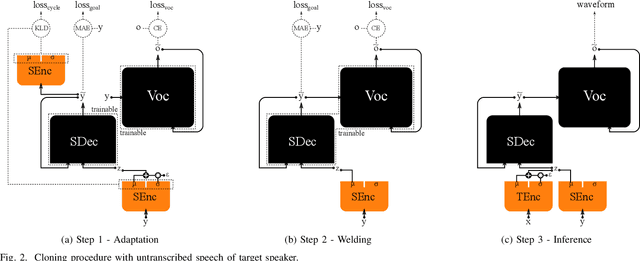
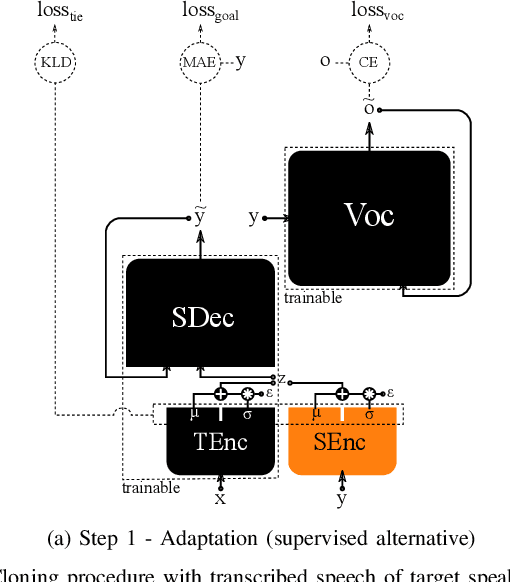
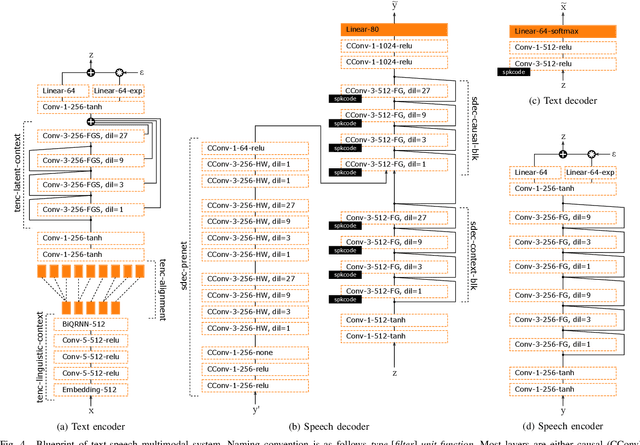
We introduce a novel speech synthesis system, called NAUTILUS, that can generate speech with a target voice either from a text input or a reference utterance of an arbitrary source speaker. By using a multi-speaker speech corpus to train all requisite encoders and decoders in the initial training stage, our system can clone unseen voices using untranscribed speech of target speakers on the basis of the backpropagation algorithm. Moreover, depending on the data circumstance of the target speaker, the cloning strategy can be adjusted to take advantage of additional data and modify the behaviors of text-to-speech (TTS) and/or voice conversion (VC) systems to accommodate the situation. We test the performance of the proposed framework by using deep convolution layers to model the encoders, decoders and WaveNet vocoder. Evaluations show that it achieves comparable quality with state-of-the-art TTS and VC systems when cloning with just five minutes of untranscribed speech. Moreover, it is demonstrated that the proposed framework has the ability to switch between TTS and VC with high speaker consistency, which will be useful for many applications.
Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech
Sep 14, 2019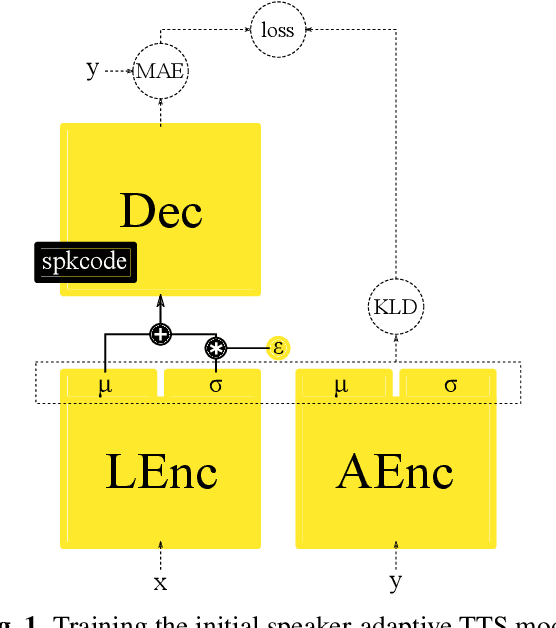
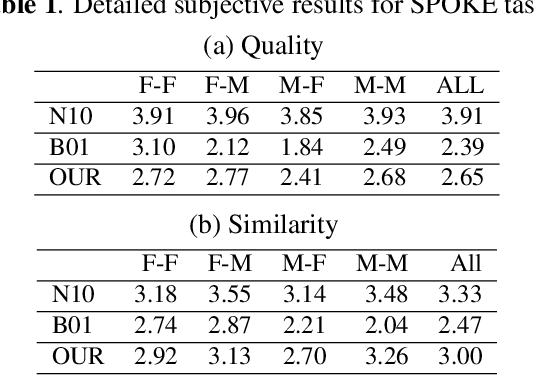
Voice conversion (VC) and text-to-speech (TTS) are two tasks that share a similar objective, generating speech with a target voice. However, they are usually developed independently under vastly different frameworks. In this paper, we propose a methodology to bootstrap a VC system from a pretrained speaker-adaptive TTS model and unify the techniques as well as the interpretations of these two tasks. Moreover by offloading the heavy data demand to the training stage of the TTS model, our VC system can be built using a small amount of target speaker speech data. It also opens up the possibility of using speech in a foreign unseen language to build the system. Our subjective evaluations show that the proposed framework is able to not only achieve competitive performance in the standard intra-language scenario but also adapt and convert using speech utterances in an unseen language.
A Unified Speaker Adaptation Method for Speech Synthesis using Transcribed and Untranscribed Speech with Backpropagation
Jun 18, 2019
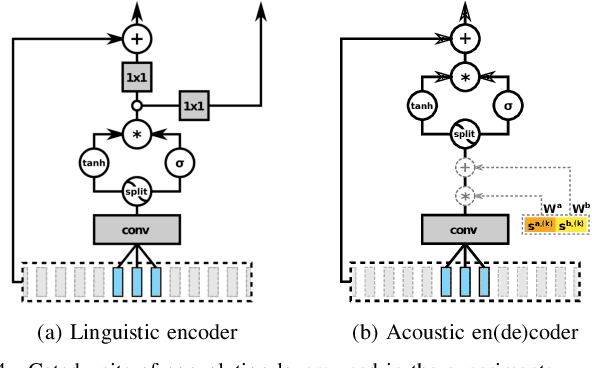
By representing speaker characteristic as a single fixed-length vector extracted solely from speech, we can train a neural multi-speaker speech synthesis model by conditioning the model on those vectors. This model can also be adapted to unseen speakers regardless of whether the transcript of adaptation data is available or not. However, this setup restricts the speaker component to just a single bias vector, which in turn limits the performance of adaptation process. In this study, we propose a novel speech synthesis model, which can be adapted to unseen speakers by fine-tuning part of or all of the network using either transcribed or untranscribed speech. Our methodology essentially consists of two steps: first, we split the conventional acoustic model into a speaker-independent (SI) linguistic encoder and a speaker-adaptive (SA) acoustic decoder; second, we train an auxiliary acoustic encoder that can be used as a substitute for the linguistic encoder whenever linguistic features are unobtainable. The results of objective and subjective evaluations show that adaptation using either transcribed or untranscribed speech with our methodology achieved a reasonable level of performance with an extremely limited amount of data and greatly improved performance with more data. Surprisingly, adaptation with untranscribed speech surpassed the transcribed counterpart in the subjective test, which reveals the limitations of the conventional acoustic model and hints at potential directions for improvements.