 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaughNet: synthesizing laughter utterances from waveform silhouettes and a single laughter example
Paper and Code
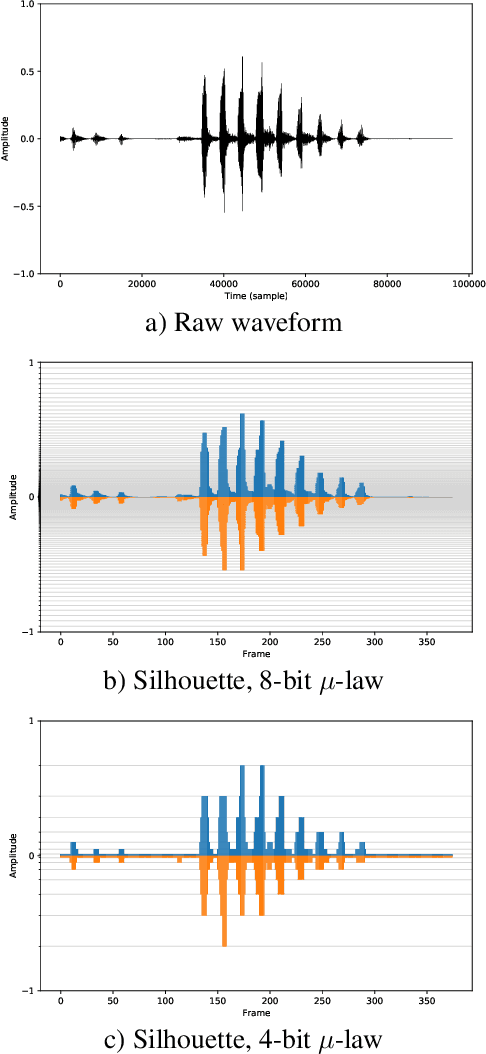
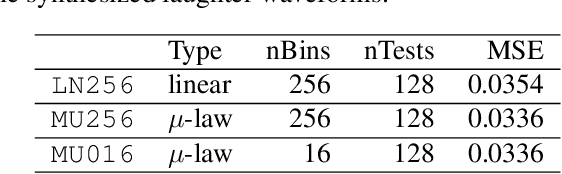
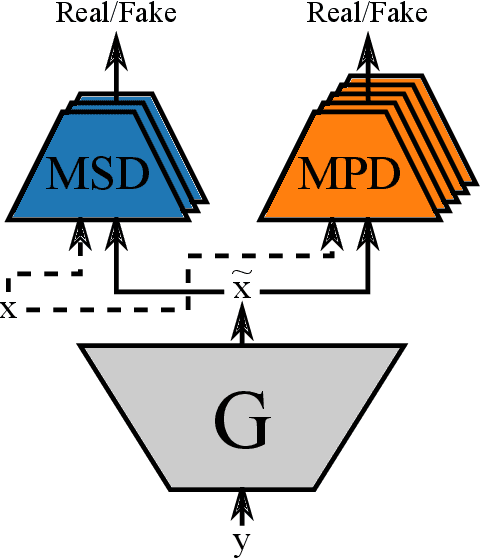
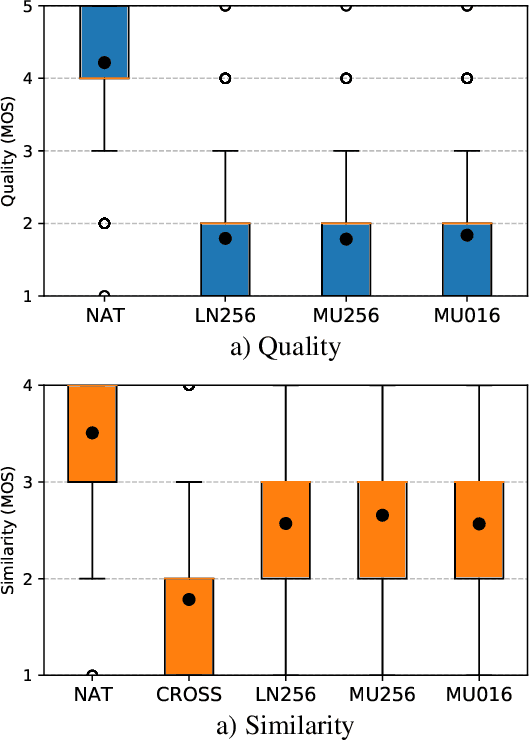
Emotional and controllable speech synthesis is a topic that has received much attention. However, most studies focused on improving the expressiveness and controllability in the context of linguistic content, even though natural verbal human communication is inseparable from spontaneous non-speech expressions such as laughter, crying, or grunting. We propose a model called LaughNet for synthesizing laughter by using waveform silhouettes as inputs. The motivation is not simply synthesizing new laughter utterances but testing a novel synthesis-control paradigm that uses an abstract representation of the waveform. We conducted basic listening test experiments, and the results showed that LaughNet can synthesize laughter utterances with moderate quality and retain the characteristics of the training example. More importantly, the generated waveforms have shapes similar to the input silhouettes. For future work, we will test the same method on other types of human nonverbal expressions and integrate it into more elaborated synthesis systems.