 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Multi-Speaker Neural Text-to-Speech Systems using Speaker-Imbalanced Speech Corpora
Apr 07, 2019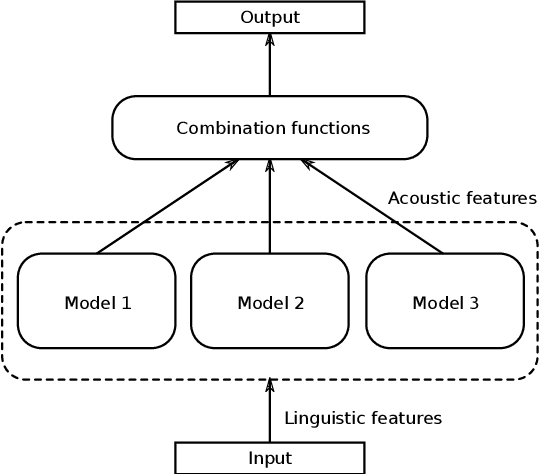
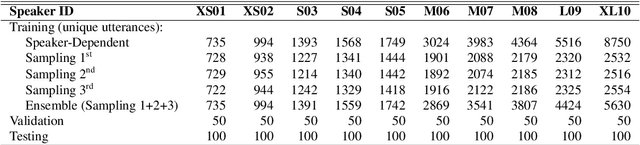
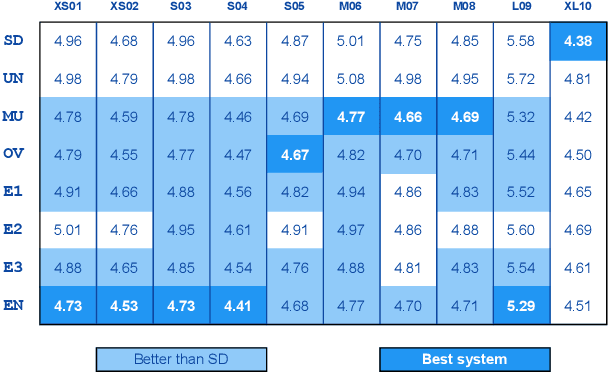
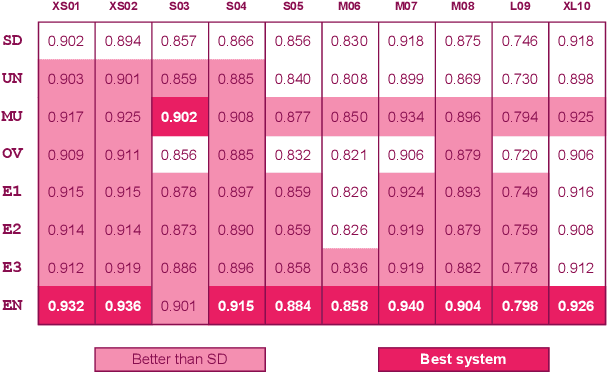
When the available data of a target speaker is insufficient to train a high quality speaker-dependent neural text-to-speech (TTS) system, we can combine data from multiple speakers and train a multi-speaker TTS model instead. Many studies have shown that neural multi-speaker TTS model trained with a small amount data from multiple speakers combined can generate synthetic speech with better quality and stability than a speaker-dependent one. However when the amount of data from each speaker is highly unbalanced, the best approach to make use of the excessive data remains unknown. Our experiments showed that simply combining all available data from every speaker to train a multi-speaker model produces better than or at least similar performance to its speaker-dependent counterpart. Moreover by using an ensemble multi-speaker model, in which each subsystem is trained on a subset of available data, we can further improve the quality of the synthetic speech especially for underrepresented speakers whose training data is limited.
Investigating accuracy of pitch-accent annotations in neural network-based speech synthesis and denoising effects
Aug 02, 2018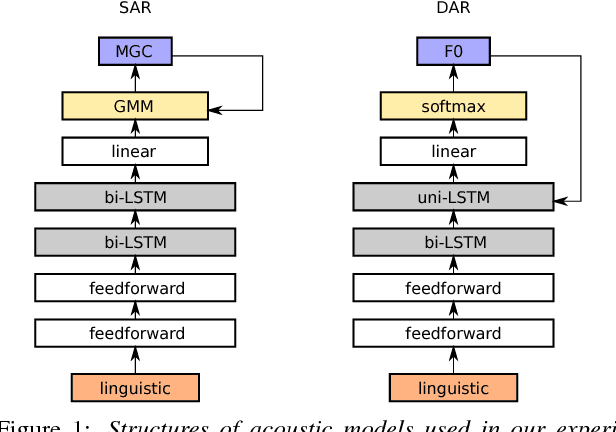
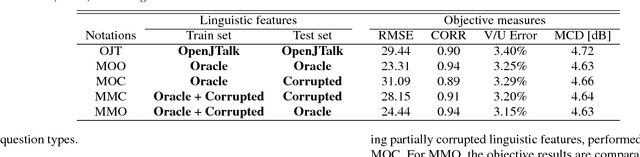
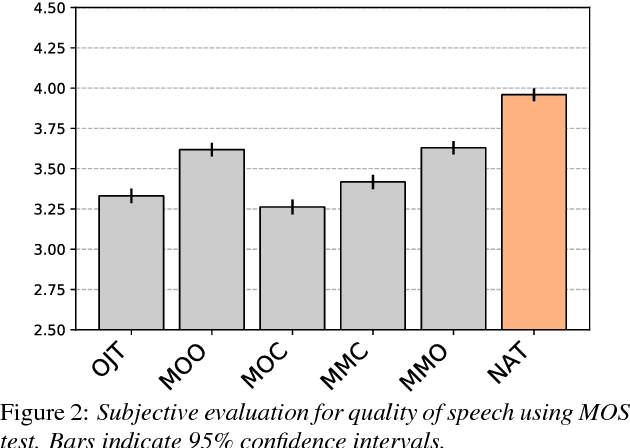
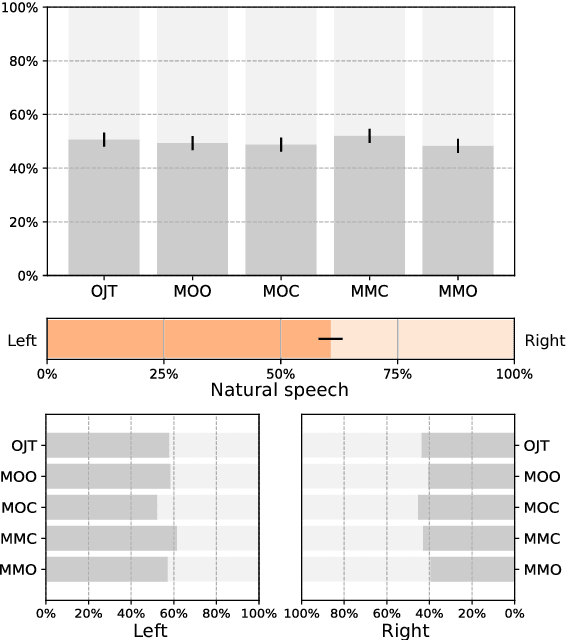
We investigated the impact of noisy linguistic features on the performance of a Japanese speech synthesis system based on neural network that uses WaveNet vocoder. We compared an ideal system that uses manually corrected linguistic features including phoneme and prosodic information in training and test sets against a few other systems that use corrupted linguistic features. Both subjective and objective results demonstrate that corrupted linguistic features, especially those in the test set, affected the ideal system's performance significantly in a statistical sense due to a mismatched condition between the training and test sets. Interestingly, while an utterance-level Turing test showed that listeners had a difficult time differentiating synthetic speech from natural speech, it further indicated that adding noise to the linguistic features in the training set can partially reduce the effect of the mismatch, regularize the model, and help the system perform better when linguistic features of the test set are noisy.