 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolating Speaker Identities in Embedding Space for Data Expansion
Aug 26, 2025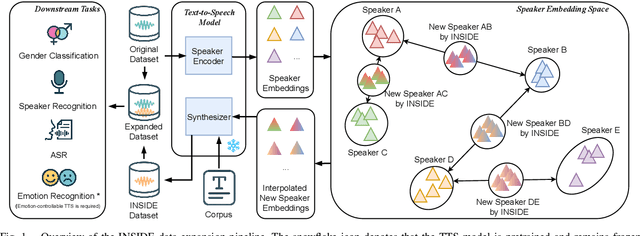
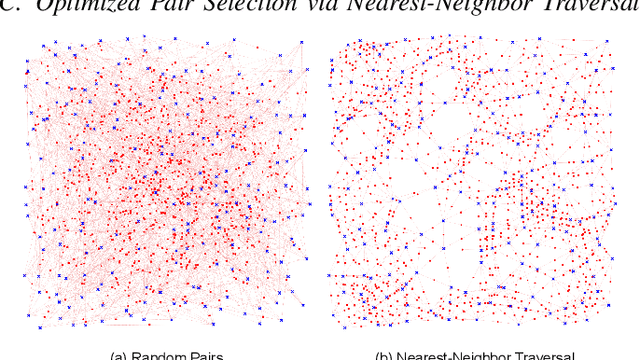
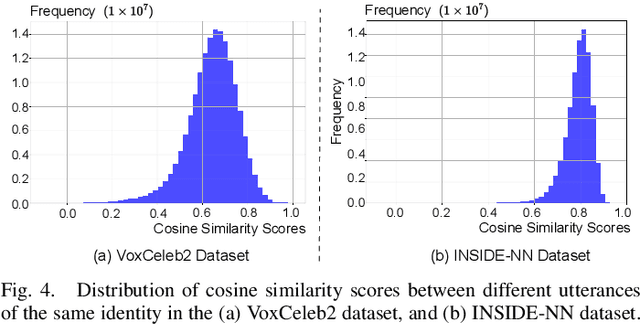
The success of deep learning-based speaker verification systems is largely attributed to access to large-scale and diverse speaker identity data. However, collecting data from more identities is expensive, challenging, and often limited by privacy concerns. To address this limitation, we propose INSIDE (Interpolating Speaker Identities in Embedding Space), a novel data expansion method that synthesizes new speaker identities by interpolating between existing speaker embeddings. Specifically, we select pairs of nearby speaker embeddings from a pretrained speaker embedding space and compute intermediate embeddings using spherical linear interpolation. These interpolated embeddings are then fed to a text-to-speech system to generate corresponding speech waveforms. The resulting data is combined with the original dataset to train downstream models. Experiments show that models trained with INSIDE-expanded data outperform those trained only on real data, achieving 3.06\% to 5.24\% relative improvements. While INSIDE is primarily designed for speaker verification, we also validate its effectiveness on gender classification, where it yields a 13.44\% relative improvement. Moreover, INSIDE is compatible with other augmentation techniques and can serve as a flexible, scalable addition to existing training pipelines.
Unified Audio Event Detection
Sep 13, 2024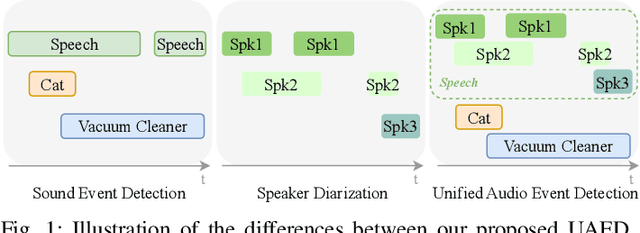
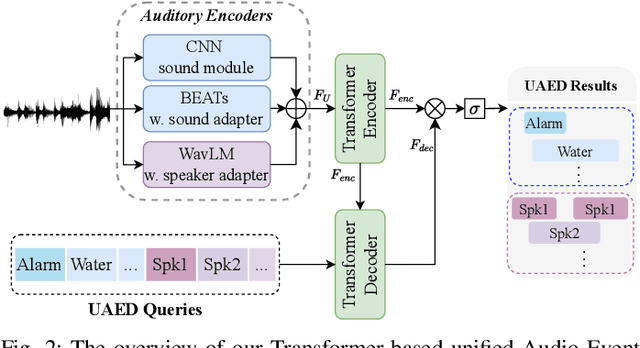
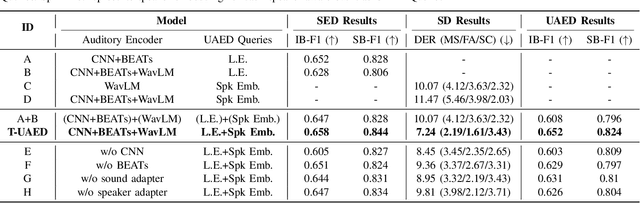
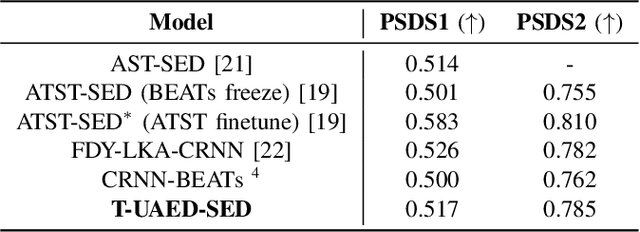
Sound Event Detection (SED) detects regions of sound events, while Speaker Diarization (SD) segments speech conversations attributed to individual speakers. In SED, all speaker segments are classified as a single speech event, while in SD, non-speech sounds are treated merely as background noise. Thus, both tasks provide only partial analysis in complex audio scenarios involving both speech conversation and non-speech sounds. In this paper, we introduce a novel task called Unified Audio Event Detection (UAED) for comprehensive audio analysis. UAED explores the synergy between SED and SD tasks, simultaneously detecting non-speech sound events and fine-grained speech events based on speaker identities. To tackle this task, we propose a Transformer-based UAED (T-UAED) framework and construct the UAED Data derived from the Librispeech dataset and DESED soundbank. Experiments demonstrate that the proposed framework effectively exploits task interactions and substantially outperforms the baseline that simply combines the outputs of SED and SD models. T-UAED also shows its versatility by performing comparably to specialized models for individual SED and SD tasks on DESED and CALLHOME datasets.
Multi-Stage Face-Voice Association Learning with Keynote Speaker Diarization
Jul 25, 2024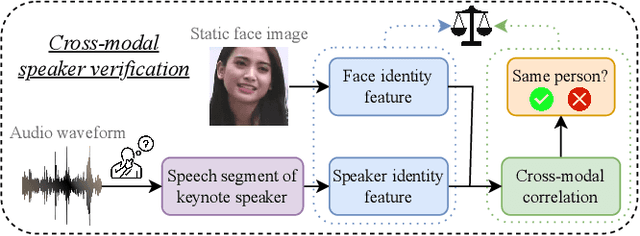
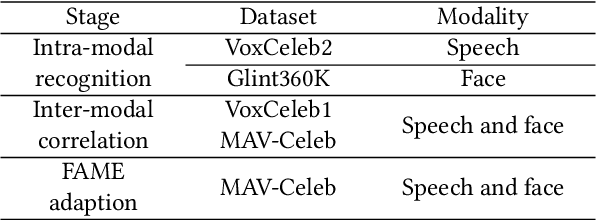
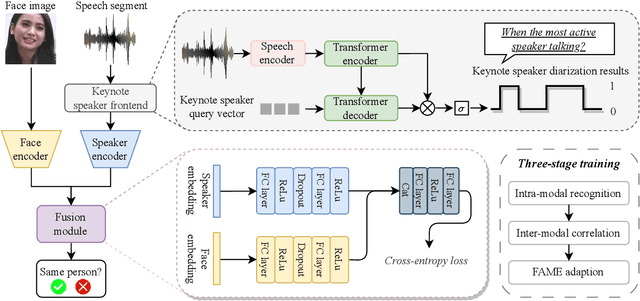

The human brain has the capability to associate the unknown person's voice and face by leveraging their general relationship, referred to as ``cross-modal speaker verification''. This task poses significant challenges due to the complex relationship between the modalities. In this paper, we propose a ``Multi-stage Face-voice Association Learning with Keynote Speaker Diarization''~(MFV-KSD) framework. MFV-KSD contains a keynote speaker diarization front-end to effectively address the noisy speech inputs issue. To balance and enhance the intra-modal feature learning and inter-modal correlation understanding, MFV-KSD utilizes a novel three-stage training strategy. Our experimental results demonstrated robust performance, achieving the first rank in the 2024 Face-voice Association in Multilingual Environments (FAME) challenge with an overall Equal Error Rate (EER) of 19.9%. Details can be found in https://github.com/TaoRuijie/MFV-KSD.
A Benchmark for Multi-speaker Anonymization
Jul 08, 2024
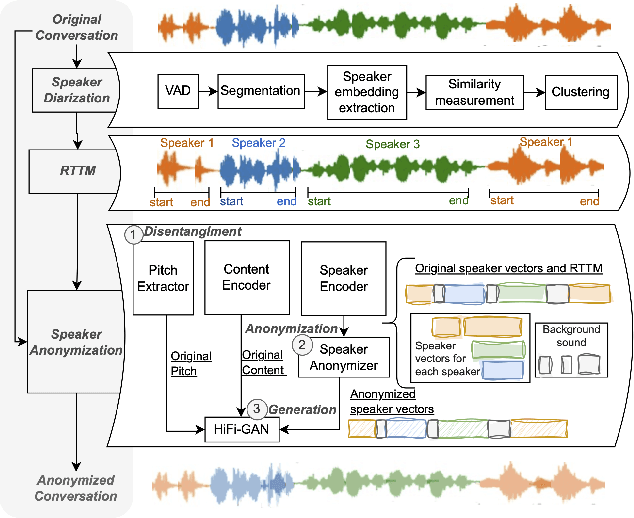
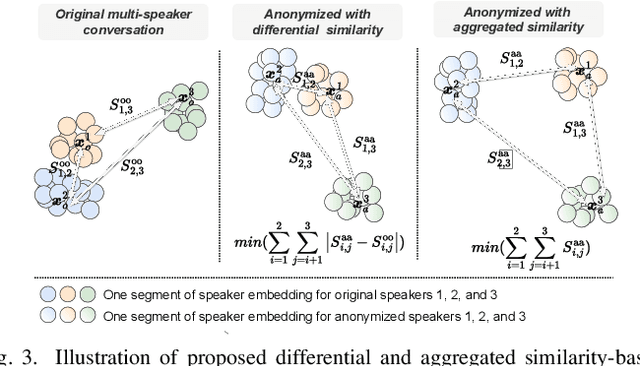
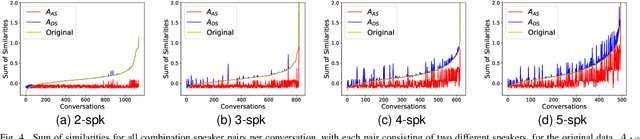
Privacy-preserving voice protection approaches primarily suppress privacy-related information derived from paralinguistic attributes while preserving the linguistic content. Existing solutions focus on single-speaker scenarios. However, they lack practicality for real-world applications, i.e., multi-speaker scenarios. In this paper, we present an initial attempt to provide a multi-speaker anonymization benchmark by defining the task and evaluation protocol, proposing benchmarking solutions, and discussing the privacy leakage of overlapping conversations. Specifically, ideal multi-speaker anonymization should preserve the number of speakers and the turn-taking structure of the conversation, ensuring accurate context conveyance while maintaining privacy. To achieve that, a cascaded system uses speaker diarization to aggregate the speech of each speaker and speaker anonymization to conceal speaker privacy and preserve speech content. Additionally, we propose two conversation-level speaker vector anonymization methods to improve the utility further. Both methods aim to make the original and corresponding pseudo-speaker identities of each speaker unlinkable while preserving or even improving the distinguishability among pseudo-speakers in a conversation. The first method minimizes the differential similarity across speaker pairs in the original and anonymized conversations to maintain original speaker relationships in the anonymized version. The other method minimizes the aggregated similarity across anonymized speakers to achieve better differentiation between speakers. Experiments conducted on both non-overlap simulated and real-world datasets demonstrate the effectiveness of the multi-speaker anonymization system with the proposed speaker anonymizers. Additionally, we analyzed overlapping speech regarding privacy leakage and provide potential solutions.
Temporal-Channel Modeling in Multi-head Self-Attention for Synthetic Speech Detection
Jun 25, 2024Recent synthetic speech detectors leveraging the Transformer model have superior performance compared to the convolutional neural network counterparts. This improvement could be due to the powerful modeling ability of the multi-head self-attention (MHSA) in the Transformer model, which learns the temporal relationship of each input token. However, artifacts of synthetic speech can be located in specific regions of both frequency channels and temporal segments, while MHSA neglects this temporal-channel dependency of the input sequence. In this work, we proposed a Temporal-Channel Modeling (TCM) module to enhance MHSA's capability for capturing temporal-channel dependencies. Experimental results on the ASVspoof 2021 show that with only 0.03M additional parameters, the TCM module can outperform the state-of-the-art system by 9.25% in EER. Further ablation study reveals that utilizing both temporal and channel information yields the most improvement for detecting synthetic speech.
Target Speech Diarization with Multimodal Prompts
Jun 11, 2024



Traditional speaker diarization seeks to detect ``who spoke when'' according to speaker characteristics. Extending to target speech diarization, we detect ``when target event occurs'' according to the semantic characteristics of speech. We propose a novel Multimodal Target Speech Diarization (MM-TSD) framework, which accommodates diverse and multi-modal prompts to specify target events in a flexible and user-friendly manner, including semantic language description, pre-enrolled speech, pre-registered face image, and audio-language logical prompts. We further propose a voice-face aligner module to project human voice and face representation into a shared space. We develop a multi-modal dataset based on VoxCeleb2 for MM-TSD training and evaluation. Additionally, we conduct comparative analysis and ablation studies for each category of prompts to validate the efficacy of each component in the proposed framework. Furthermore, our framework demonstrates versatility in performing various signal processing tasks, including speaker diarization and overlap speech detection, using task-specific prompts. MM-TSD achieves robust and comparable performance as a unified system compared to specialized models. Moreover, MM-TSD shows capability to handle complex conversations for real-world dataset.
How Do Neural Spoofing Countermeasures Detect Partially Spoofed Audio?
Jun 04, 2024Partially manipulating a sentence can greatly change its meaning. Recent work shows that countermeasures (CMs) trained on partially spoofed audio can effectively detect such spoofing. However, the current understanding of the decision-making process of CMs is limited. We utilize Grad-CAM and introduce a quantitative analysis metric to interpret CMs' decisions. We find that CMs prioritize the artifacts of transition regions created when concatenating bona fide and spoofed audio. This focus differs from that of CMs trained on fully spoofed audio, which concentrate on the pattern differences between bona fide and spoofed parts. Our further investigation explains the varying nature of CMs' focus while making correct or incorrect predictions. These insights provide a basis for the design of CM models and the creation of datasets. Moreover, this work lays a foundation of interpretability in the field of partial spoofed audio detection that has not been well explored previously.
Audio-Visual Target Speaker Extraction with Reverse Selective Auditory Attention
Apr 29, 2024



Audio-visual target speaker extraction (AV-TSE) aims to extract the specific person's speech from the audio mixture given auxiliary visual cues. Previous methods usually search for the target voice through speech-lip synchronization. However, this strategy mainly focuses on the existence of target speech, while ignoring the variations of the noise characteristics. That may result in extracting noisy signals from the incorrect sound source in challenging acoustic situations. To this end, we propose a novel reverse selective auditory attention mechanism, which can suppress interference speakers and non-speech signals to avoid incorrect speaker extraction. By estimating and utilizing the undesired noisy signal through this mechanism, we design an AV-TSE framework named Subtraction-and-ExtrAction network (SEANet) to suppress the noisy signals. We conduct abundant experiments by re-implementing three popular AV-TSE methods as the baselines and involving nine metrics for evaluation. The experimental results show that our proposed SEANet achieves state-of-the-art results and performs well for all five datasets. We will release the codes, the models and data logs.
Voice Conversion Augmentation for Speaker Recognition on Defective Datasets
Apr 01, 2024



Modern speaker recognition system relies on abundant and balanced datasets for classification training. However, diverse defective datasets, such as partially-labelled, small-scale, and imbalanced datasets, are common in real-world applications. Previous works usually studied specific solutions for each scenario from the algorithm perspective. However, the root cause of these problems lies in dataset imperfections. To address these challenges with a unified solution, we propose the Voice Conversion Augmentation (VCA) strategy to obtain pseudo speech from the training set. Furthermore, to guarantee generation quality, we designed the VCA-NN~(nearest neighbours) strategy to select source speech from utterances that are close to the target speech in the representation space. Our experimental results on three created datasets demonstrated that VCA-NN effectively mitigates these dataset problems, which provides a new direction for handling the speaker recognition problems from the data aspect.
Enhancing Real-World Active Speaker Detection with Multi-Modal Extraction Pre-Training
Apr 01, 2024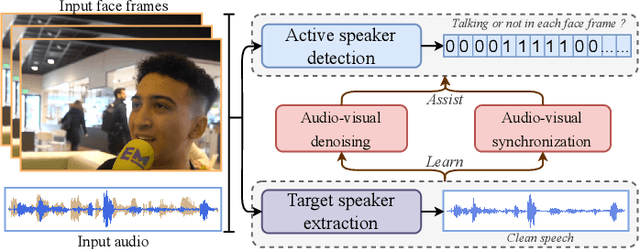
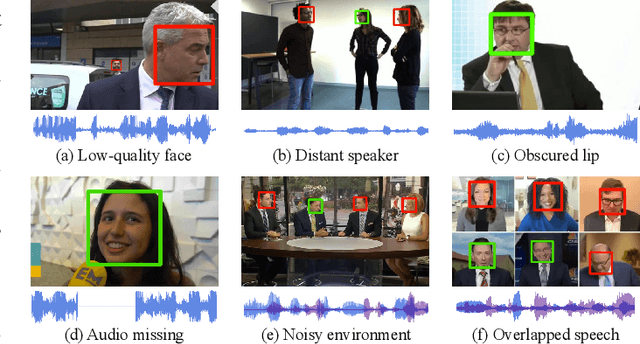
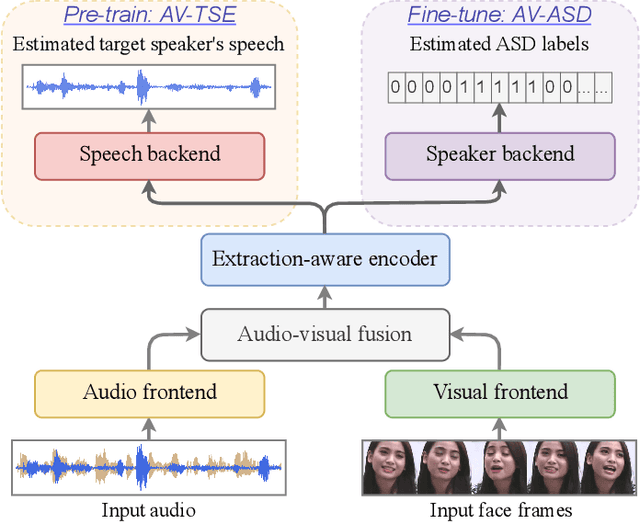
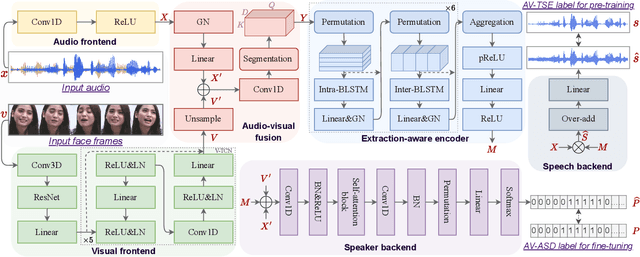
Audio-visual active speaker detection (AV-ASD) aims to identify which visible face is speaking in a scene with one or more persons. Most existing AV-ASD methods prioritize capturing speech-lip correspondence. However, there is a noticeable gap in addressing the challenges from real-world AV-ASD scenarios. Due to the presence of low-quality noisy videos in such cases, AV-ASD systems without a selective listening ability are short of effectively filtering out disruptive voice components from mixed audio inputs. In this paper, we propose a Multi-modal Speaker Extraction-to-Detection framework named `MuSED', which is pre-trained with audio-visual target speaker extraction to learn the denoising ability, then it is fine-tuned with the AV-ASD task. Meanwhile, to better capture the multi-modal information and deal with real-world problems such as missing modality, MuSED is modelled on the time domain directly and integrates the multi-modal plus-and-minus augmentation strategy. Our experiments demonstrate that MuSED substantially outperforms the state-of-the-art AV-ASD methods and achieves 95.6% mAP on the AVA-ActiveSpeaker dataset, 98.3% AP on the ASW dataset, and 97.9% F1 on the Columbia AV-ASD dataset, respectively. We will publicly release the code in due course.