 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoASR-Bench: Evaluating Large Speech Language Models on Low-Resource Automatic Speech Recognition Across Language Families
Mar 20, 2026Large language models (LLMs) have driven substantial advances in speech language models (SpeechLMs), yielding strong performance in automatic speech recognition (ASR) under high-resource conditions. However, existing benchmarks predominantly focus on high-resource languages, leaving the ASR behavior of SpeechLMs in low-resource languages insufficiently understood. This gap is critical, as practical ASR systems must reliably support low-resource languages and generalize across diverse language families, and it directly hinders the deployment of SpeechLM-based ASR in real-world multilingual scenarios. As a result, it is essential to evaluate SpeechLMs on low-resource languages to ensure their generalizability across different language families. To address this problem, we propose \textbf{LoASR-Bench}, a comprehensive benchmark designed to evaluate \textbf{lo}w-resource \textbf{a}utomatic \textbf{s}peech \textbf{r}ecognition (\textbf{ASR}) of the latest SpeechLMs across diverse language families. LoASR-Bench comprises 25 languages from 9 language families, featuring both Latin and non-Latin scripts, enabling cross-linguistic and cross-script assessment of ASR performance of current SpeechLMs. Experimental results highlight the limitations of the latest SpeechLMs in handling real-world low-resource languages.
MORE: Multi-Objective Adversarial Attacks on Speech Recognition
Jan 05, 2026The emergence of large-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-world applications. Ensuring robustness against even minor input perturbations is therefore critical for maintaining reliable performance in real-time environments. While prior work has mainly examined accuracy degradation under adversarial attacks, robustness with respect to efficiency remains largely unexplored. This narrow focus provides only a partial understanding of ASR model vulnerabilities. To address this gap, we conduct a comprehensive study of ASR robustness under multiple attack scenarios. We introduce MORE, a multi-objective repetitive doubling encouragement attack, which jointly degrades recognition accuracy and inference efficiency through a hierarchical staged repulsion-anchoring mechanism. Specifically, we reformulate multi-objective adversarial optimization into a hierarchical framework that sequentially achieves the dual objectives. To further amplify effectiveness, we propose a novel repetitive encouragement doubling objective (REDO) that induces duplicative text generation by maintaining accuracy degradation and periodically doubling the predicted sequence length. Overall, MORE compels ASR models to produce incorrect transcriptions at a substantially higher computational cost, triggered by a single adversarial input. Experiments show that MORE consistently yields significantly longer transcriptions while maintaining high word error rates compared to existing baselines, underscoring its effectiveness in multi-objective adversarial attack.
MultiAiTutor: Child-Friendly Educational Multilingual Speech Generation Tutor with LLMs
Aug 12, 2025Generative speech models have demonstrated significant potential in personalizing teacher-student interactions, offering valuable real-world applications for language learning in children's education. However, achieving high-quality, child-friendly speech generation remains challenging, particularly for low-resource languages across diverse languages and cultural contexts. In this paper, we propose MultiAiTutor, an educational multilingual generative AI tutor with child-friendly designs, leveraging LLM architecture for speech generation tailored for educational purposes. We propose to integrate age-appropriate multilingual speech generation using LLM architectures, facilitating young children's language learning through culturally relevant image-description tasks in three low-resource languages: Singaporean-accent Mandarin, Malay, and Tamil. Experimental results from both objective metrics and subjective evaluations demonstrate the superior performance of the proposed MultiAiTutor compared to baseline methods.
Confidence-Based Self-Training for EMG-to-Speech: Leveraging Synthetic EMG for Robust Modeling
Jun 13, 2025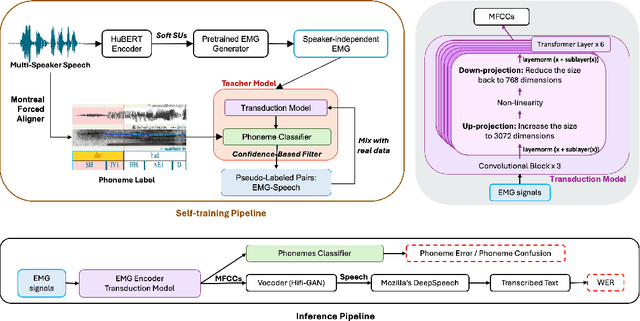
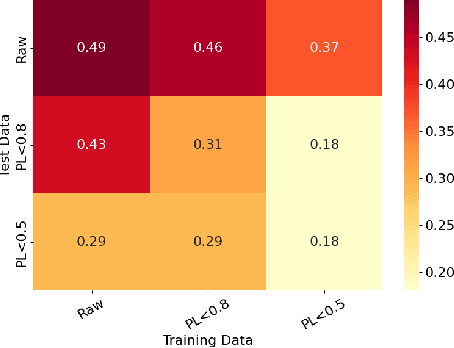
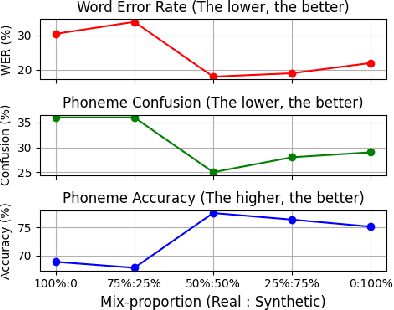

Voiced Electromyography (EMG)-to-Speech (V-ETS) models reconstruct speech from muscle activity signals, facilitating applications such as neurolaryngologic diagnostics. Despite its potential, the advancement of V-ETS is hindered by a scarcity of paired EMG-speech data. To address this, we propose a novel Confidence-based Multi-Speaker Self-training (CoM2S) approach, along with a newly curated Libri-EMG dataset. This approach leverages synthetic EMG data generated by a pre-trained model, followed by a proposed filtering mechanism based on phoneme-level confidence to enhance the ETS model through the proposed self-training techniques. Experiments demonstrate our method improves phoneme accuracy, reduces phonological confusion, and lowers word error rate, confirming the effectiveness of our CoM2S approach for V-ETS. In support of future research, we will release the codes and the proposed Libri-EMG dataset-an open-access, time-aligned, multi-speaker voiced EMG and speech recordings.
PAL: Prompting Analytic Learning with Missing Modality for Multi-Modal Class-Incremental Learning
Jan 16, 2025Multi-modal class-incremental learning (MMCIL) seeks to leverage multi-modal data, such as audio-visual and image-text pairs, thereby enabling models to learn continuously across a sequence of tasks while mitigating forgetting. While existing studies primarily focus on the integration and utilization of multi-modal information for MMCIL, a critical challenge remains: the issue of missing modalities during incremental learning phases. This oversight can exacerbate severe forgetting and significantly impair model performance. To bridge this gap, we propose PAL, a novel exemplar-free framework tailored to MMCIL under missing-modality scenarios. Concretely, we devise modality-specific prompts to compensate for missing information, facilitating the model to maintain a holistic representation of the data. On this foundation, we reformulate the MMCIL problem into a Recursive Least-Squares task, delivering an analytical linear solution. Building upon these, PAL not only alleviates the inherent under-fitting limitation in analytic learning but also preserves the holistic representation of missing-modality data, achieving superior performance with less forgetting across various multi-modal incremental scenarios. Extensive experiments demonstrate that PAL significantly outperforms competitive methods across various datasets, including UPMC-Food101 and N24News, showcasing its robustness towards modality absence and its anti-forgetting ability to maintain high incremental accuracy.
Transferable Adversarial Attacks against ASR
Nov 14, 2024


Given the extensive research and real-world applications of automatic speech recognition (ASR), ensuring the robustness of ASR models against minor input perturbations becomes a crucial consideration for maintaining their effectiveness in real-time scenarios. Previous explorations into ASR model robustness have predominantly revolved around evaluating accuracy on white-box settings with full access to ASR models. Nevertheless, full ASR model details are often not available in real-world applications. Therefore, evaluating the robustness of black-box ASR models is essential for a comprehensive understanding of ASR model resilience. In this regard, we thoroughly study the vulnerability of practical black-box attacks in cutting-edge ASR models and propose to employ two advanced time-domain-based transferable attacks alongside our differentiable feature extractor. We also propose a speech-aware gradient optimization approach (SAGO) for ASR, which forces mistranscription with minimal impact on human imperceptibility through voice activity detection rule and a speech-aware gradient-oriented optimizer. Our comprehensive experimental results reveal performance enhancements compared to baseline approaches across five models on two databases.
VoiceBench: Benchmarking LLM-Based Voice Assistants
Oct 22, 2024
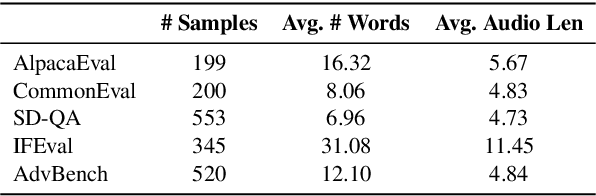

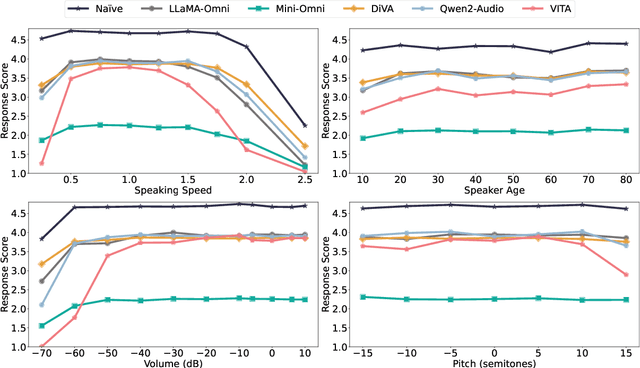
Building on the success of large language models (LLMs), recent advancements such as GPT-4o have enabled real-time speech interactions through LLM-based voice assistants, offering a significantly improved user experience compared to traditional text-based interactions. However, the absence of benchmarks designed to evaluate these speech interaction capabilities has hindered progress of LLM-based voice assistants development. Current evaluations focus primarily on automatic speech recognition (ASR) or general knowledge evaluation with clean speeches, neglecting the more intricate, real-world scenarios that involve diverse speaker characteristics, environmental and content factors. To address this, we introduce VoiceBench, the first benchmark designed to provide a multi-faceted evaluation of LLM-based voice assistants. VoiceBench also includes both real and synthetic spoken instructions that incorporate the above three key real-world variations. Extensive experiments reveal the limitations of current LLM-based voice assistant models and offer valuable insights for future research and development in this field.
Beyond Single-Audio: Advancing Multi-Audio Processing in Audio Large Language Models
Sep 27, 2024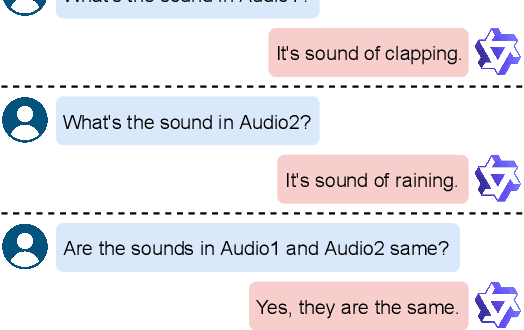
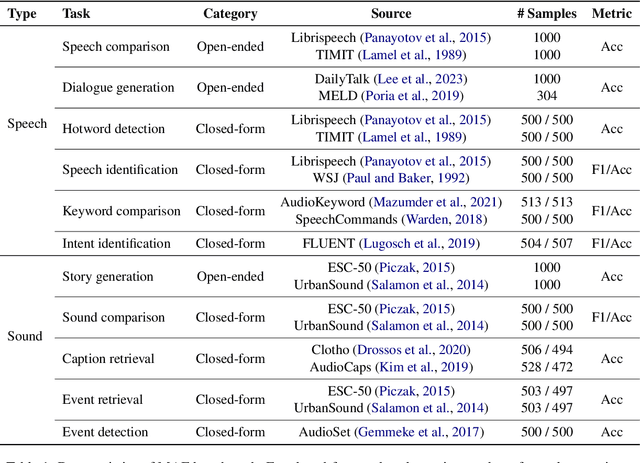
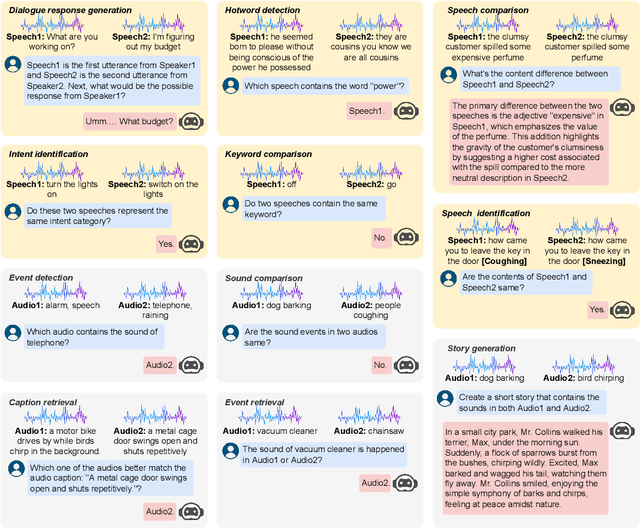
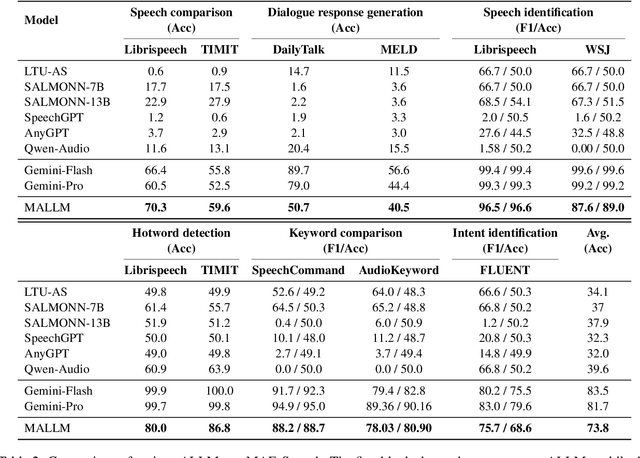
Various audio-LLMs (ALLMs) have been explored recently for tackling different audio tasks simultaneously using a single, unified model. While existing evaluations of ALLMs primarily focus on single-audio tasks, real-world applications often involve processing multiple audio streams simultaneously. To bridge this gap, we propose the first multi-audio evaluation (MAE) benchmark that consists of 20 datasets from 11 multi-audio tasks encompassing both speech and sound scenarios. Comprehensive experiments on MAE demonstrate that the existing ALLMs, while being powerful in comprehending primary audio elements in individual audio inputs, struggling to handle multi-audio scenarios. To this end, we propose a novel multi-audio-LLM (MALLM) to capture audio context among multiple similar audios using discriminative learning on our proposed synthetic data. The results demonstrate that the proposed MALLM outperforms all baselines and achieves high data efficiency using synthetic data without requiring human annotations. The proposed MALLM opens the door for ALLMs towards multi-audio processing era and brings us closer to replicating human auditory capabilities in machines.
Speech-Mamba: Long-Context Speech Recognition with Selective State Spaces Models
Sep 27, 2024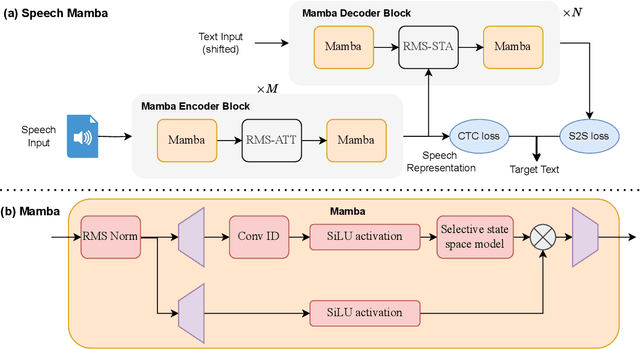


Current automatic speech recognition systems struggle with modeling long speech sequences due to high quadratic complexity of Transformer-based models. Selective state space models such as Mamba has performed well on long-sequence modeling in natural language processing and computer vision tasks. However, research endeavors in speech technology tasks has been under-explored. We propose Speech-Mamba, which incorporates selective state space modeling in Transformer neural architectures. Long sequence representations with selective state space models in Speech-Mamba is complemented with lower-level representations from Transformer-based modeling. Speech-mamba achieves better capacity to model long-range dependencies, as it scales near-linearly with sequence length.
Emo-DPO: Controllable Emotional Speech Synthesis through Direct Preference Optimization
Sep 16, 2024
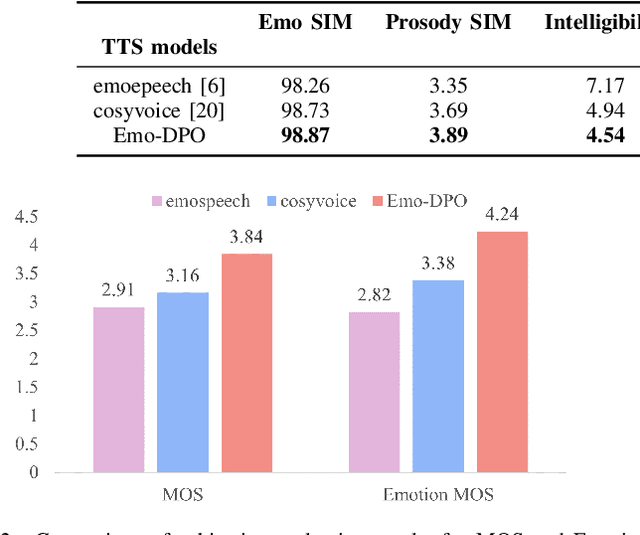


Current emotional text-to-speech (TTS) models predominantly conduct supervised training to learn the conversion from text and desired emotion to its emotional speech, focusing on a single emotion per text-speech pair. These models only learn the correct emotional outputs without fully comprehending other emotion characteristics, which limits their capabilities of capturing the nuances between different emotions. We propose a controllable Emo-DPO approach, which employs direct preference optimization to differentiate subtle emotional nuances between emotions through optimizing towards preferred emotions over less preferred emotional ones. Instead of relying on traditional neural architectures used in existing emotional TTS models, we propose utilizing the emotion-aware LLM-TTS neural architecture to leverage LLMs' in-context learning and instruction-following capabilities. Comprehensive experiments confirm that our proposed method outperforms the existing baselines.