 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Real-World Active Speaker Detection with Multi-Modal Extraction Pre-Training
Paper and Code
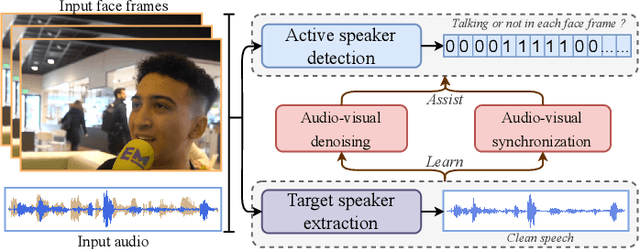
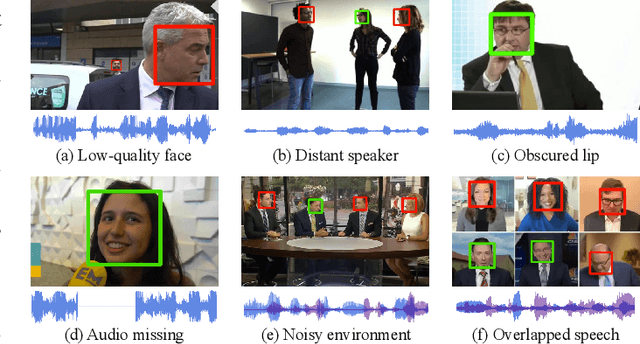
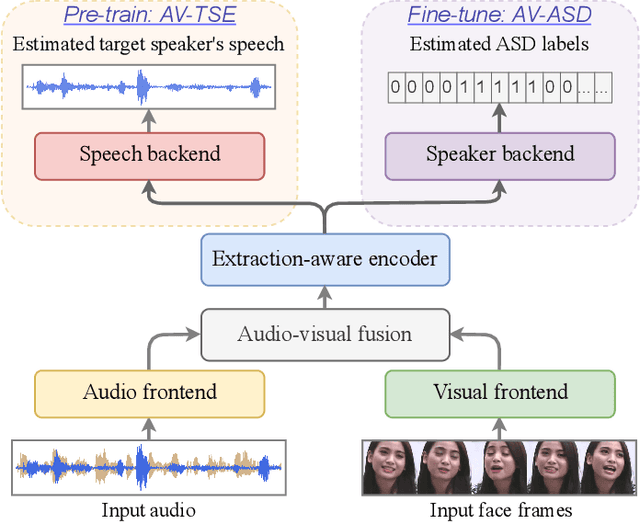
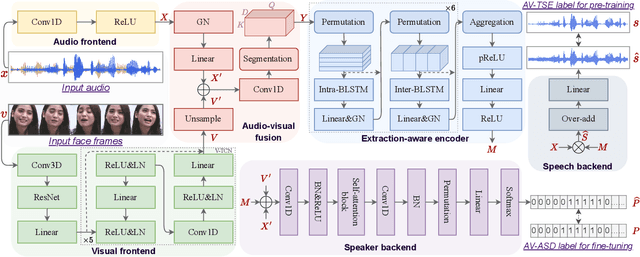
Audio-visual active speaker detection (AV-ASD) aims to identify which visible face is speaking in a scene with one or more persons. Most existing AV-ASD methods prioritize capturing speech-lip correspondence. However, there is a noticeable gap in addressing the challenges from real-world AV-ASD scenarios. Due to the presence of low-quality noisy videos in such cases, AV-ASD systems without a selective listening ability are short of effectively filtering out disruptive voice components from mixed audio inputs. In this paper, we propose a Multi-modal Speaker Extraction-to-Detection framework named `MuSED', which is pre-trained with audio-visual target speaker extraction to learn the denoising ability, then it is fine-tuned with the AV-ASD task. Meanwhile, to better capture the multi-modal information and deal with real-world problems such as missing modality, MuSED is modelled on the time domain directly and integrates the multi-modal plus-and-minus augmentation strategy. Our experiments demonstrate that MuSED substantially outperforms the state-of-the-art AV-ASD methods and achieves 95.6% mAP on the AVA-ActiveSpeaker dataset, 98.3% AP on the ASW dataset, and 97.9% F1 on the Columbia AV-ASD dataset, respectively. We will publicly release the code in due course.