 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothCLAP: Soft-Target Enhanced Contrastive Language\--Audio Pretraining for Affective Computing
Jan 18, 2026The ambiguity of human emotions poses several challenges for machine learning models, as they often overlap and lack clear delineating boundaries. Contrastive language-audio pretraining (CLAP) has emerged as a key technique for generalisable emotion recognition. However, as conventional CLAP enforces a strict one-to-one alignment between paired audio-text samples, it overlooks intra-modal similarity and treats all non-matching pairs as equally negative. This conflicts with the fuzzy boundaries between different emotions. To address this limitation, we propose SmoothCLAP, which introduces softened targets derived from intra-modal similarity and paralinguistic features. By combining these softened targets with conventional contrastive supervision, SmoothCLAP learns embeddings that respect graded emotional relationships, while retaining the same inference pipeline as CLAP. Experiments on eight affective computing tasks across English and German demonstrate that SmoothCLAP is consistently achieving superior performance. Our results highlight that leveraging soft supervision is a promising strategy for building emotion-aware audio-text models.
VP-SelDoA: Visual-prompted Selective DoA Estimation of Target Sound via Semantic-Spatial Matching
Jul 10, 2025Audio-visual sound source localization (AV-SSL) identifies the position of a sound source by exploiting the complementary strengths of auditory and visual signals. However, existing AV-SSL methods encounter three major challenges: 1) inability to selectively isolate the target sound source in multi-source scenarios, 2) misalignment between semantic visual features and spatial acoustic features, and 3) overreliance on paired audio-visual data. To overcome these limitations, we introduce Cross-Instance Audio-Visual Localization (CI-AVL), a novel task that leverages images from different instances of the same sound event category to localize target sound sources, thereby reducing dependence on paired data while enhancing generalization capabilities. Our proposed VP-SelDoA tackles this challenging task through a semantic-level modality fusion and employs a Frequency-Temporal ConMamba architecture to generate target-selective masks for sound isolation. We further develop a Semantic-Spatial Matching mechanism that aligns the heterogeneous semantic and spatial features via integrated cross- and self-attention mechanisms. To facilitate the CI-AVL research, we construct a large-scale dataset named VGG-SSL, comprising 13,981 spatial audio clips across 296 sound event categories. Extensive experiments show that our proposed method outperforms state-of-the-art audio-visual localization methods, achieving a mean absolute error (MAE) of 12.04 and an accuracy (ACC) of 78.23%.
MELT: Towards Automated Multimodal Emotion Data Annotation by Leveraging LLM Embedded Knowledge
May 30, 2025Although speech emotion recognition (SER) has advanced significantly with deep learning, annotation remains a major hurdle. Human annotation is not only costly but also subject to inconsistencies annotators often have different preferences and may lack the necessary contextual knowledge, which can lead to varied and inaccurate labels. Meanwhile, Large Language Models (LLMs) have emerged as a scalable alternative for annotating text data. However, the potential of LLMs to perform emotional speech data annotation without human supervision has yet to be thoroughly investigated. To address these problems, we apply GPT-4o to annotate a multimodal dataset collected from the sitcom Friends, using only textual cues as inputs. By crafting structured text prompts, our methodology capitalizes on the knowledge GPT-4o has accumulated during its training, showcasing that it can generate accurate and contextually relevant annotations without direct access to multimodal inputs. Therefore, we propose MELT, a multimodal emotion dataset fully annotated by GPT-4o. We demonstrate the effectiveness of MELT by fine-tuning four self-supervised learning (SSL) backbones and assessing speech emotion recognition performance across emotion datasets. Additionally, our subjective experiments\' results demonstrate a consistence performance improvement on SER.
The First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.
$C^2$AV-TSE: Context and Confidence-aware Audio Visual Target Speaker Extraction
Apr 01, 2025Audio-Visual Target Speaker Extraction (AV-TSE) aims to mimic the human ability to enhance auditory perception using visual cues. Although numerous models have been proposed recently, most of them estimate target signals by primarily relying on local dependencies within acoustic features, underutilizing the human-like capacity to infer unclear parts of speech through contextual information. This limitation results in not only suboptimal performance but also inconsistent extraction quality across the utterance, with some segments exhibiting poor quality or inadequate suppression of interfering speakers. To close this gap, we propose a model-agnostic strategy called the Mask-And-Recover (MAR). It integrates both inter- and intra-modality contextual correlations to enable global inference within extraction modules. Additionally, to better target challenging parts within each sample, we introduce a Fine-grained Confidence Score (FCS) model to assess extraction quality and guide extraction modules to emphasize improvement on low-quality segments. To validate the effectiveness of our proposed model-agnostic training paradigm, six popular AV-TSE backbones were adopted for evaluation on the VoxCeleb2 dataset, demonstrating consistent performance improvements across various metrics.
Analytic Class Incremental Learning for Sound Source Localization with Privacy Protection
Sep 11, 2024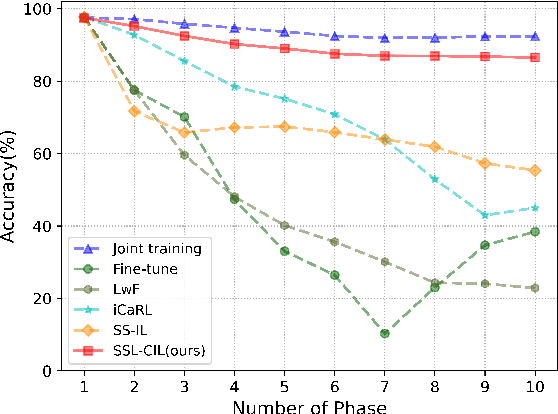
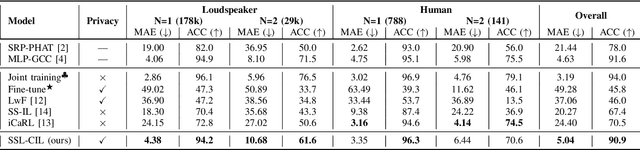

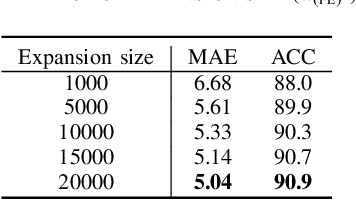
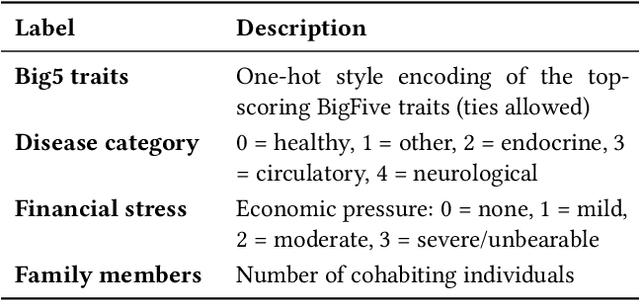
Sound Source Localization (SSL) enabling technology for applications such as surveillance and robotics. While traditional Signal Processing (SP)-based SSL methods provide analytic solutions under specific signal and noise assumptions, recent Deep Learning (DL)-based methods have significantly outperformed them. However, their success depends on extensive training data and substantial computational resources. Moreover, they often rely on large-scale annotated spatial data and may struggle when adapting to evolving sound classes. To mitigate these challenges, we propose a novel Class Incremental Learning (CIL) approach, termed SSL-CIL, which avoids serious accuracy degradation due to catastrophic forgetting by incrementally updating the DL-based SSL model through a closed-form analytic solution. In particular, data privacy is ensured since the learning process does not revisit any historical data (exemplar-free), which is more suitable for smart home scenarios. Empirical results in the public SSLR dataset demonstrate the superior performance of our proposal, achieving a localization accuracy of 90.9%, surpassing other competitive methods.
Human-Inspired Audio-Visual Speech Recognition: Spike Activity, Cueing Interaction and Causal Processing
Aug 29, 2024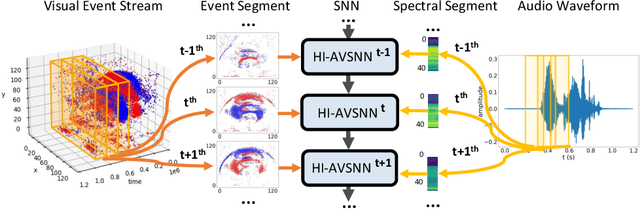
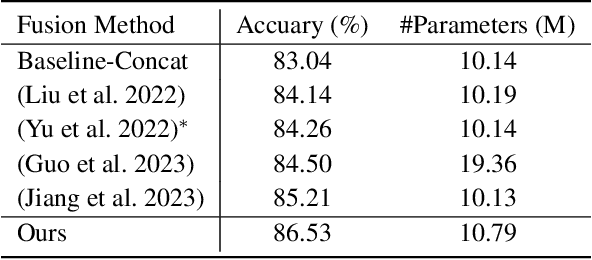
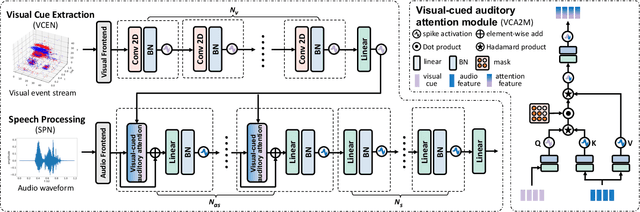

Humans naturally perform audiovisual speech recognition (AVSR), enhancing the accuracy and robustness by integrating auditory and visual information. Spiking neural networks (SNNs), which mimic the brain's information-processing mechanisms, are well-suited for emulating the human capability of AVSR. Despite their potential, research on SNNs for AVSR is scarce, with most existing audio-visual multimodal methods focused on object or digit recognition. These models simply integrate features from both modalities, neglecting their unique characteristics and interactions. Additionally, they often rely on future information for current processing, which increases recognition latency and limits real-time applicability. Inspired by human speech perception, this paper proposes a novel human-inspired SNN named HI-AVSNN for AVSR, incorporating three key characteristics: cueing interaction, causal processing and spike activity. For cueing interaction, we propose a visual-cued auditory attention module (VCA2M) that leverages visual cues to guide attention to auditory features. We achieve causal processing by aligning the SNN's temporal dimension with that of visual and auditory features and applying temporal masking to utilize only past and current information. To implement spike activity, in addition to using SNNs, we leverage the event camera to capture lip movement as spikes, mimicking the human retina and providing efficient visual data. We evaluate HI-AVSNN on an audiovisual speech recognition dataset combining the DVS-Lip dataset with its corresponding audio samples. Experimental results demonstrate the superiority of our proposed fusion method, outperforming existing audio-visual SNN fusion methods and achieving a 2.27% improvement in accuracy over the only existing SNN-based AVSR method.
Raindrop Clarity: A Dual-Focused Dataset for Day and Night Raindrop Removal
Jul 24, 2024



Existing raindrop removal datasets have two shortcomings. First, they consist of images captured by cameras with a focus on the background, leading to the presence of blurry raindrops. To our knowledge, none of these datasets include images where the focus is specifically on raindrops, which results in a blurry background. Second, these datasets predominantly consist of daytime images, thereby lacking nighttime raindrop scenarios. Consequently, algorithms trained on these datasets may struggle to perform effectively in raindrop-focused or nighttime scenarios. The absence of datasets specifically designed for raindrop-focused and nighttime raindrops constrains research in this area. In this paper, we introduce a large-scale, real-world raindrop removal dataset called Raindrop Clarity. Raindrop Clarity comprises 15,186 high-quality pairs/triplets (raindrops, blur, and background) of images with raindrops and the corresponding clear background images. There are 5,442 daytime raindrop images and 9,744 nighttime raindrop images. Specifically, the 5,442 daytime images include 3,606 raindrop- and 1,836 background-focused images. While the 9,744 nighttime images contain 4,838 raindrop- and 4,906 background-focused images. Our dataset will enable the community to explore background-focused and raindrop-focused images, including challenges unique to daytime and nighttime conditions. Our data and code are available at: \url{https://github.com/jinyeying/RaindropClarity}
Audio-Visual Target Speaker Extraction with Reverse Selective Auditory Attention
Apr 29, 2024



Audio-visual target speaker extraction (AV-TSE) aims to extract the specific person's speech from the audio mixture given auxiliary visual cues. Previous methods usually search for the target voice through speech-lip synchronization. However, this strategy mainly focuses on the existence of target speech, while ignoring the variations of the noise characteristics. That may result in extracting noisy signals from the incorrect sound source in challenging acoustic situations. To this end, we propose a novel reverse selective auditory attention mechanism, which can suppress interference speakers and non-speech signals to avoid incorrect speaker extraction. By estimating and utilizing the undesired noisy signal through this mechanism, we design an AV-TSE framework named Subtraction-and-ExtrAction network (SEANet) to suppress the noisy signals. We conduct abundant experiments by re-implementing three popular AV-TSE methods as the baselines and involving nine metrics for evaluation. The experimental results show that our proposed SEANet achieves state-of-the-art results and performs well for all five datasets. We will release the codes, the models and data logs.
Enhancing Real-World Active Speaker Detection with Multi-Modal Extraction Pre-Training
Apr 01, 2024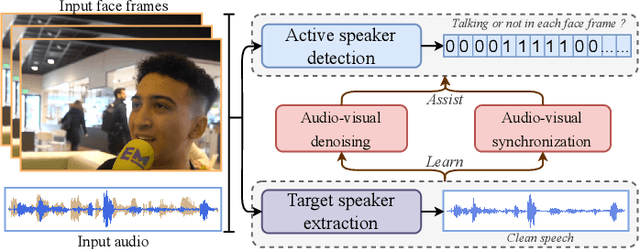
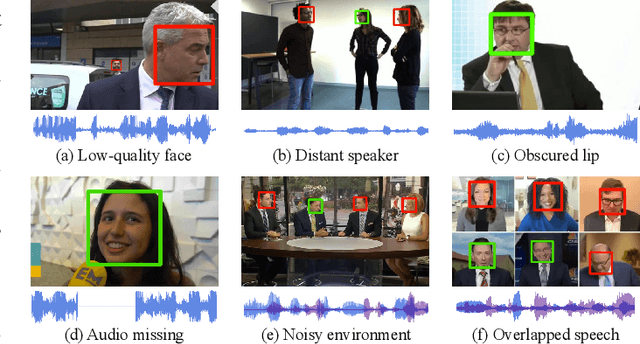
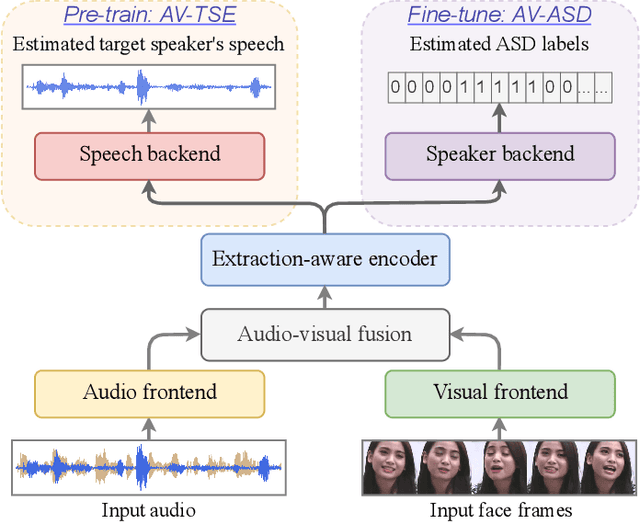
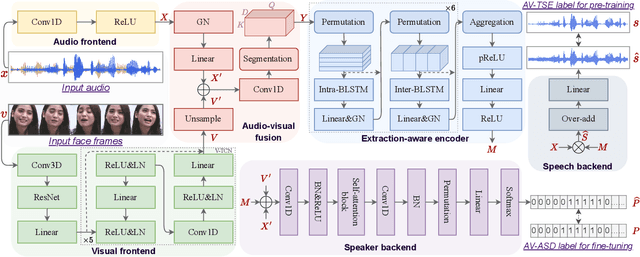
Audio-visual active speaker detection (AV-ASD) aims to identify which visible face is speaking in a scene with one or more persons. Most existing AV-ASD methods prioritize capturing speech-lip correspondence. However, there is a noticeable gap in addressing the challenges from real-world AV-ASD scenarios. Due to the presence of low-quality noisy videos in such cases, AV-ASD systems without a selective listening ability are short of effectively filtering out disruptive voice components from mixed audio inputs. In this paper, we propose a Multi-modal Speaker Extraction-to-Detection framework named `MuSED', which is pre-trained with audio-visual target speaker extraction to learn the denoising ability, then it is fine-tuned with the AV-ASD task. Meanwhile, to better capture the multi-modal information and deal with real-world problems such as missing modality, MuSED is modelled on the time domain directly and integrates the multi-modal plus-and-minus augmentation strategy. Our experiments demonstrate that MuSED substantially outperforms the state-of-the-art AV-ASD methods and achieves 95.6% mAP on the AVA-ActiveSpeaker dataset, 98.3% AP on the ASW dataset, and 97.9% F1 on the Columbia AV-ASD dataset, respectively. We will publicly release the code in due course.