 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-target DoA Estimation with an Audio-visual Fusion Mechanism
Paper and Code
May 13, 2021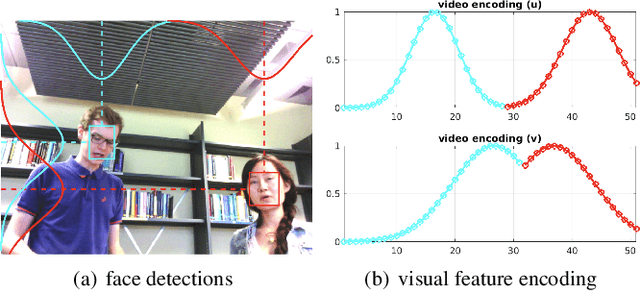
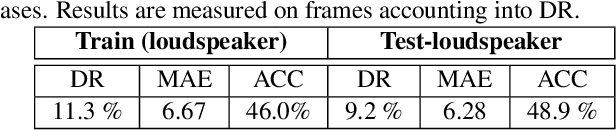
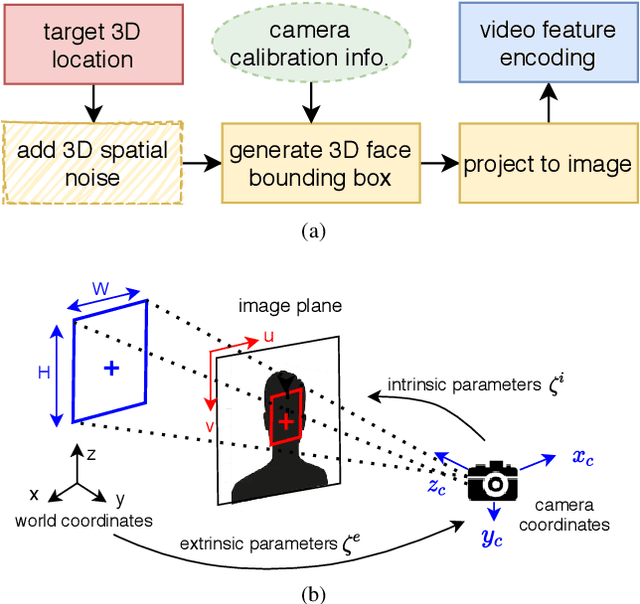

Most of the prior studies in the spatial \ac{DoA} domain focus on a single modality. However, humans use auditory and visual senses to detect the presence of sound sources. With this motivation, we propose to use neural networks with audio and visual signals for multi-speaker localization. The use of heterogeneous sensors can provide complementary information to overcome uni-modal challenges, such as noise, reverberation, illumination variations, and occlusions. We attempt to address these issues by introducing an adaptive weighting mechanism for audio-visual fusion. We also propose a novel video simulation method that generates visual features from noisy target 3D annotations that are synchronized with acoustic features. Experimental results confirm that audio-visual fusion consistently improves the performance of speaker DoA estimation, while the adaptive weighting mechanism shows clear benefits.