 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Teacher-Student Learning Approach for Multi-lingual Speech-to-Intent Classification
Sep 28, 2021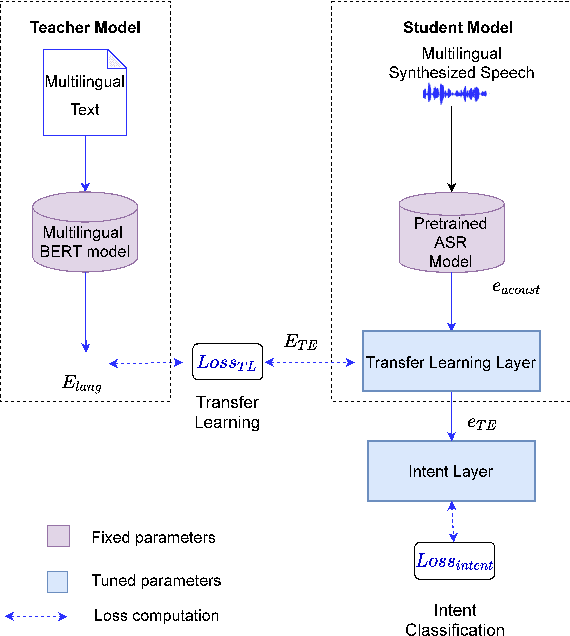
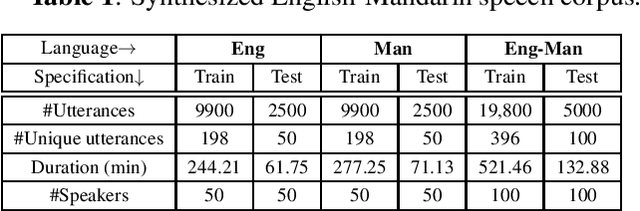
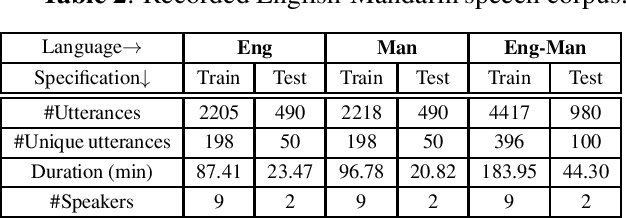
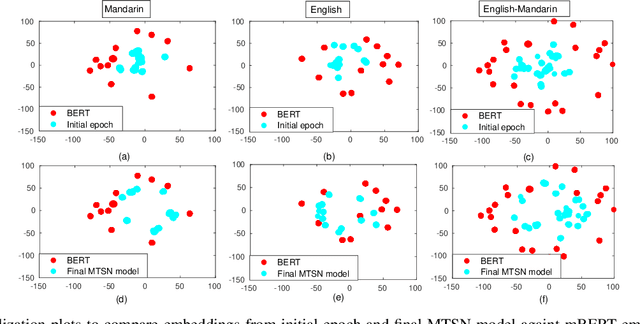
End-to-end speech-to-intent classification has shown its advantage in harvesting information from both text and speech. In this paper, we study a technique to develop such an end-to-end system that supports multiple languages. To overcome the scarcity of multi-lingual speech corpus, we exploit knowledge from a pre-trained multi-lingual natural language processing model. Multi-lingual bidirectional encoder representations from transformers (mBERT) models are trained on multiple languages and hence expected to perform well in the multi-lingual scenario. In this work, we employ a teacher-student learning approach to sufficiently extract information from an mBERT model to train a multi-lingual speech model. In particular, we use synthesized speech generated from an English-Mandarin text corpus for analysis and training of a multi-lingual intent classification model. We also demonstrate that the teacher-student learning approach obtains an improved performance (91.02%) over the traditional end-to-end (89.40%) intent classification approach in a practical multi-lingual scenario.
Knowledge Distillation from BERT Transformer to Speech Transformer for Intent Classification
Aug 05, 2021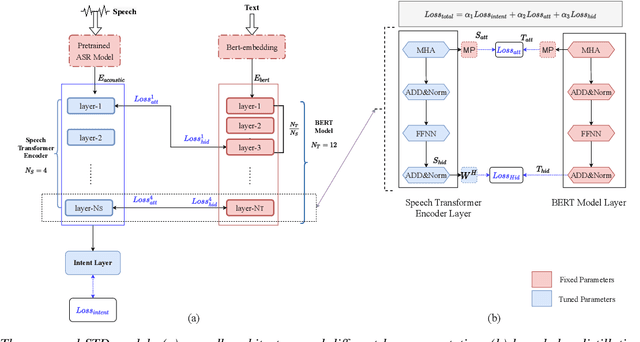
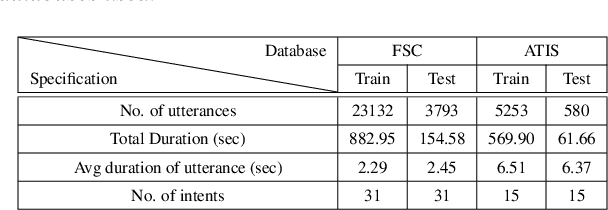
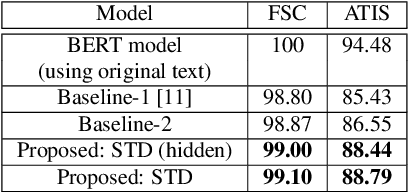
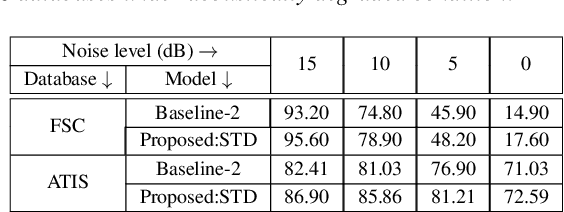
End-to-end intent classification using speech has numerous advantages compared to the conventional pipeline approach using automatic speech recognition (ASR), followed by natural language processing modules. It attempts to predict intent from speech without using an intermediate ASR module. However, such end-to-end framework suffers from the unavailability of large speech resources with higher acoustic variation in spoken language understanding. In this work, we exploit the scope of the transformer distillation method that is specifically designed for knowledge distillation from a transformer based language model to a transformer based speech model. In this regard, we leverage the reliable and widely used bidirectional encoder representations from transformers (BERT) model as a language model and transfer the knowledge to build an acoustic model for intent classification using the speech. In particular, a multilevel transformer based teacher-student model is designed, and knowledge distillation is performed across attention and hidden sub-layers of different transformer layers of the student and teacher models. We achieve an intent classification accuracy of 99.10% and 88.79% for Fluent speech corpus and ATIS database, respectively. Further, the proposed method demonstrates better performance and robustness in acoustically degraded condition compared to the baseline method.
Multi-target DoA Estimation with an Audio-visual Fusion Mechanism
May 13, 2021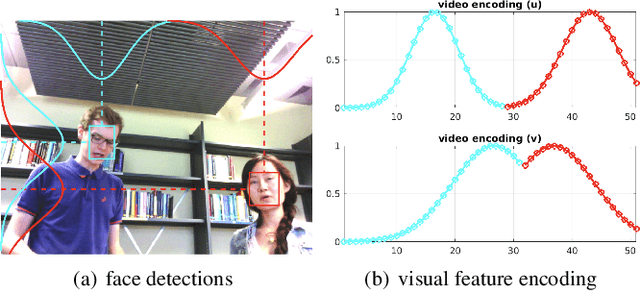
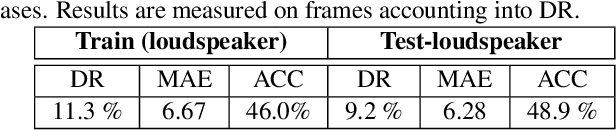
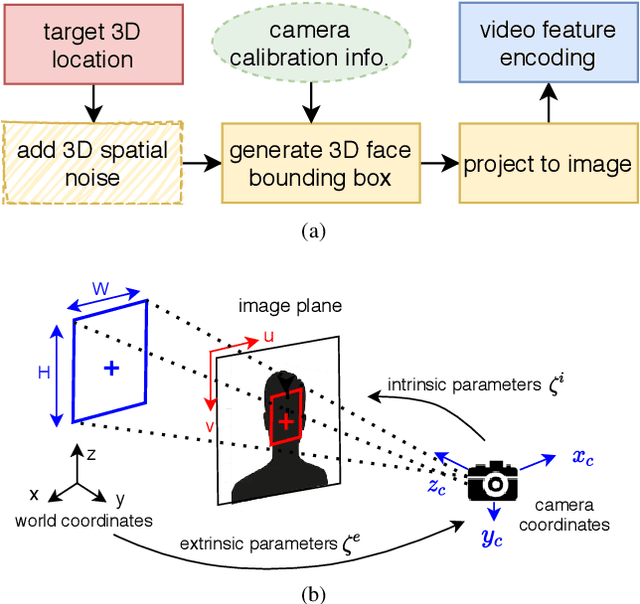

Most of the prior studies in the spatial \ac{DoA} domain focus on a single modality. However, humans use auditory and visual senses to detect the presence of sound sources. With this motivation, we propose to use neural networks with audio and visual signals for multi-speaker localization. The use of heterogeneous sensors can provide complementary information to overcome uni-modal challenges, such as noise, reverberation, illumination variations, and occlusions. We attempt to address these issues by introducing an adaptive weighting mechanism for audio-visual fusion. We also propose a novel video simulation method that generates visual features from noisy target 3D annotations that are synchronized with acoustic features. Experimental results confirm that audio-visual fusion consistently improves the performance of speaker DoA estimation, while the adaptive weighting mechanism shows clear benefits.
Leveraging Acoustic and Linguistic Embeddings from Pretrained speech and language Models for Intent Classification
Feb 15, 2021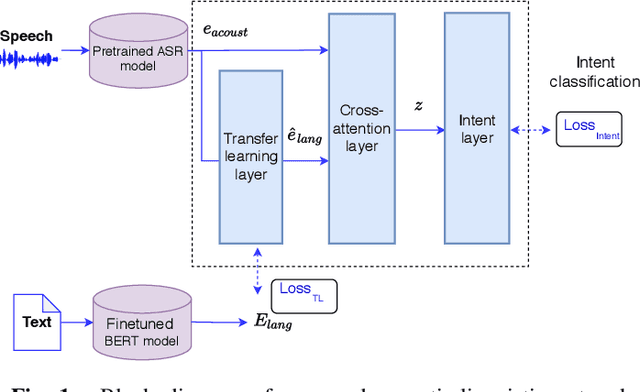
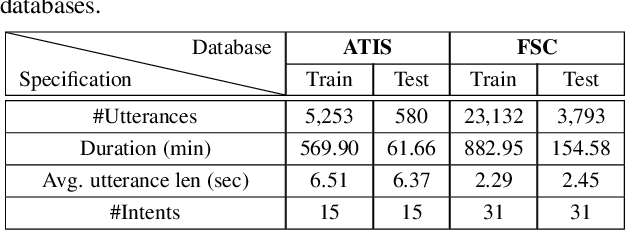
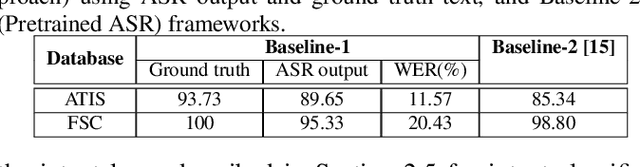
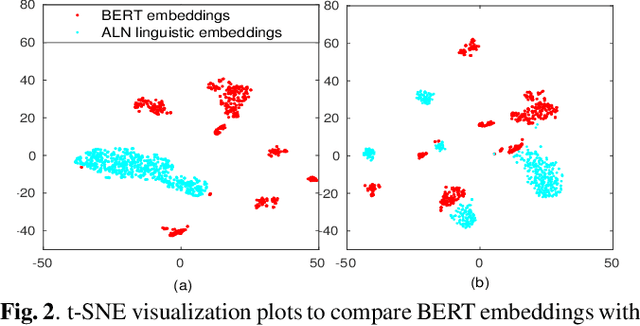
Intent classification is a task in spoken language understanding. An intent classification system is usually implemented as a pipeline process, with a speech recognition module followed by text processing that classifies the intents. There are also studies of end-to-end system that takes acoustic features as input and classifies the intents directly. Such systems don't take advantage of relevant linguistic information, and suffer from limited training data. In this work, we propose a novel intent classification framework that employs acoustic features extracted from a pretrained speech recognition system and linguistic features learned from a pretrained language model. We use knowledge distillation technique to map the acoustic embeddings towards linguistic embeddings. We perform fusion of both acoustic and linguistic embeddings through cross-attention approach to classify intents. With the proposed method, we achieve 90.86% and 99.07% accuracy on ATIS and Fluent speech corpus, respectively.
Speaker-Utterance Dual Attention for Speaker and Utterance Verification
Aug 20, 2020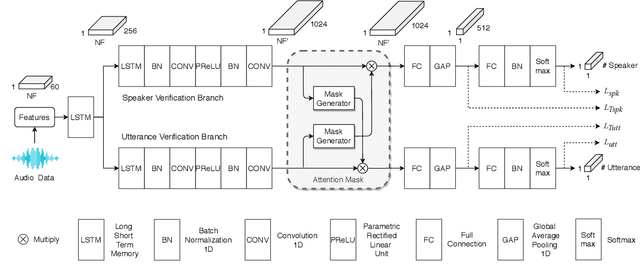
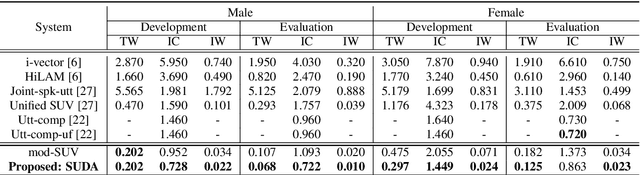
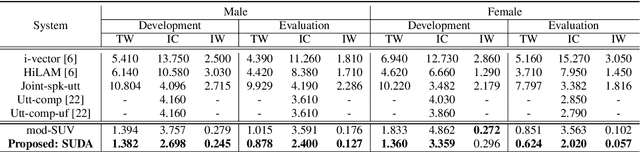
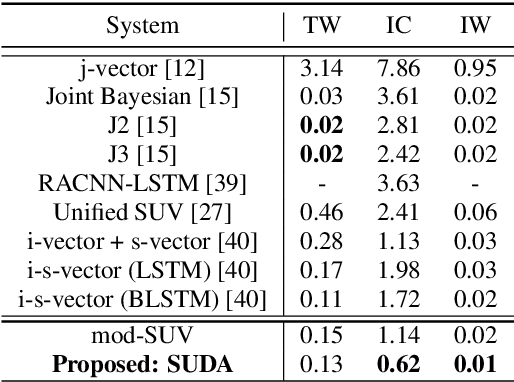
In this paper, we study a novel technique that exploits the interaction between speaker traits and linguistic content to improve both speaker verification and utterance verification performance. We implement an idea of speaker-utterance dual attention (SUDA) in a unified neural network. The dual attention refers to an attention mechanism for the two tasks of speaker and utterance verification. The proposed SUDA features an attention mask mechanism to learn the interaction between the speaker and utterance information streams. This helps to focus only on the required information for respective task by masking the irrelevant counterparts. The studies conducted on RSR2015 corpus confirm that the proposed SUDA outperforms the framework without attention mask as well as several competitive systems for both speaker and utterance verification.