 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Streaming and Non-streaming Zipformer-based ASR
Jun 17, 2025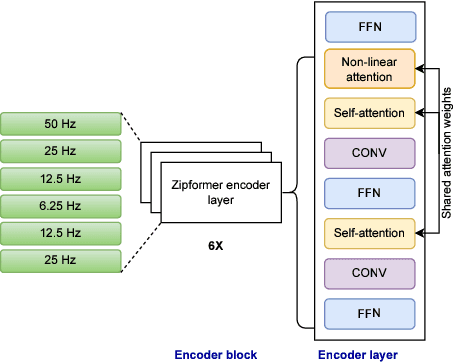
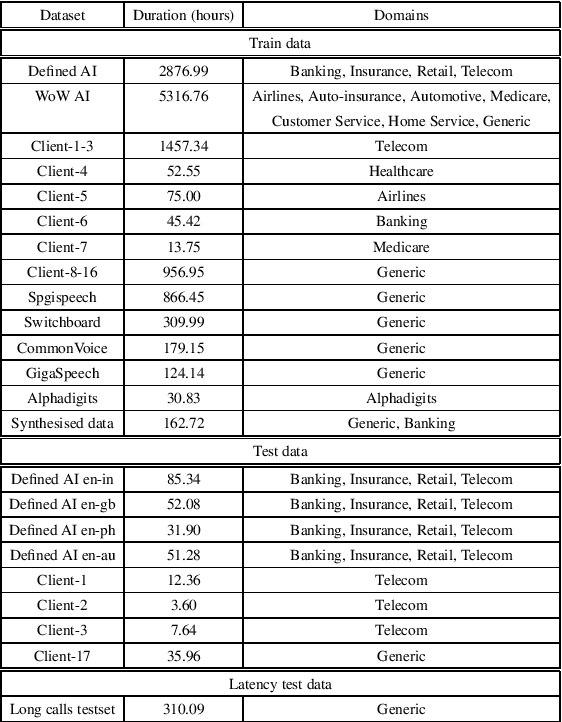
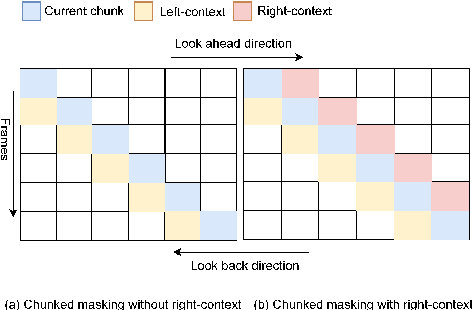
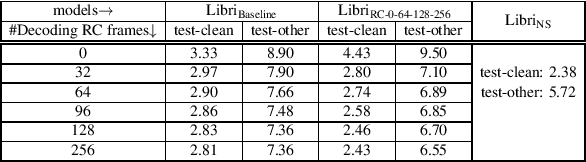
There has been increasing interest in unifying streaming and non-streaming automatic speech recognition (ASR) models to reduce development, training, and deployment costs. We present a unified framework that trains a single end-to-end ASR model for both streaming and non-streaming applications, leveraging future context information. We propose to use dynamic right-context through the chunked attention masking in the training of zipformer-based ASR models. We demonstrate that using right-context is more effective in zipformer models compared to other conformer models due to its multi-scale nature. We analyze the effect of varying the number of right-context frames on accuracy and latency of the streaming ASR models. We use Librispeech and large in-house conversational datasets to train different versions of streaming and non-streaming models and evaluate them in a production grade server-client setup across diverse testsets of different domains. The proposed strategy reduces word error by relative 7.9\% with a small degradation in user-perceived latency. By adding more right-context frames, we are able to achieve streaming performance close to that of non-streaming models. Our approach also allows flexible control of the latency-accuracy tradeoff according to customers requirements.
Better Semi-supervised Learning for Multi-domain ASR Through Incremental Retraining and Data Filtering
Jun 05, 2025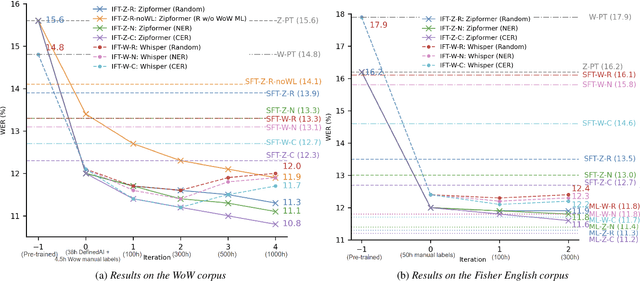
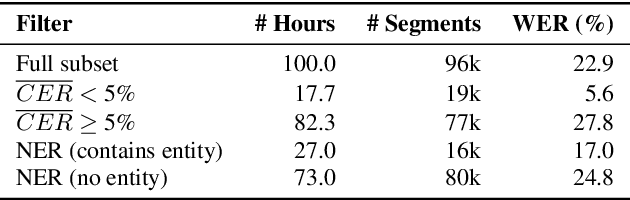

Fine-tuning pretrained ASR models for specific domains is challenging when labeled data is scarce. But unlabeled audio and labeled data from related domains are often available. We propose an incremental semi-supervised learning pipeline that first integrates a small in-domain labeled set and an auxiliary dataset from a closely related domain, achieving a relative improvement of 4% over no auxiliary data. Filtering based on multi-model consensus or named entity recognition (NER) is then applied to select and iteratively refine pseudo-labels, showing slower performance saturation compared to random selection. Evaluated on the multi-domain Wow call center and Fisher English corpora, it outperforms single-step fine-tuning. Consensus-based filtering outperforms other methods, providing up to 22.3% relative improvement on Wow and 24.8% on Fisher over single-step fine-tuning with random selection. NER is the second-best filter, providing competitive performance at a lower computational cost.
Effectiveness of Text, Acoustic, and Lattice-based representations in Spoken Language Understanding tasks
Dec 16, 2022



In this paper, we perform an exhaustive evaluation of different representations to address the intent classification problem in a Spoken Language Understanding (SLU) setup. We benchmark three types of systems to perform the SLU intent detection task: 1) text-based, 2) lattice-based, and a novel 3) multimodal approach. Our work provides a comprehensive analysis of what could be the achievable performance of different state-of-the-art SLU systems under different circumstances, e.g., automatically- vs. manually-generated transcripts. We evaluate the systems on the publicly available SLURP spoken language resource corpus. Our results indicate that using richer forms of Automatic Speech Recognition (ASR) outputs allows SLU systems to improve in comparison to the 1-best setup (4% relative improvement). However, crossmodal approaches, i.e., learning from acoustic and text embeddings, obtains performance similar to the oracle setup, and a relative improvement of 18% over the 1-best configuration. Thus, crossmodal architectures represent a good alternative to overcome the limitations of working purely automatically generated textual data.
Exploring Teacher-Student Learning Approach for Multi-lingual Speech-to-Intent Classification
Sep 28, 2021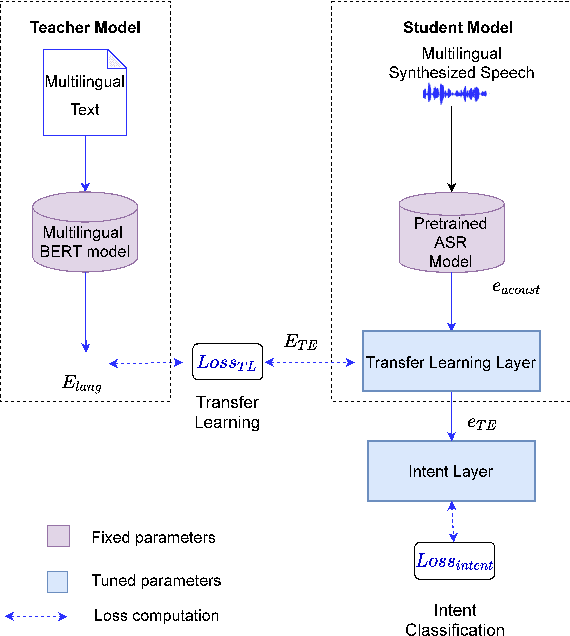
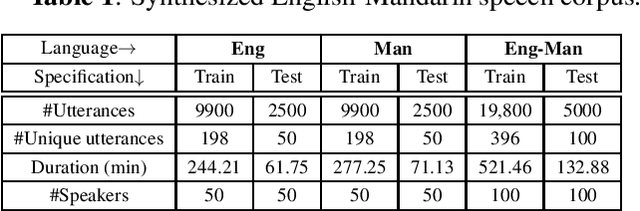
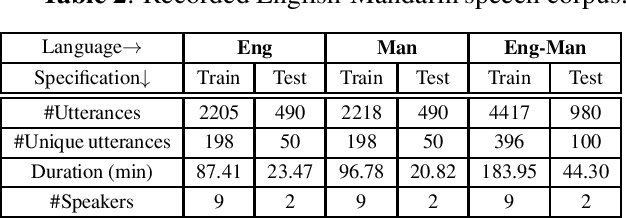
End-to-end speech-to-intent classification has shown its advantage in harvesting information from both text and speech. In this paper, we study a technique to develop such an end-to-end system that supports multiple languages. To overcome the scarcity of multi-lingual speech corpus, we exploit knowledge from a pre-trained multi-lingual natural language processing model. Multi-lingual bidirectional encoder representations from transformers (mBERT) models are trained on multiple languages and hence expected to perform well in the multi-lingual scenario. In this work, we employ a teacher-student learning approach to sufficiently extract information from an mBERT model to train a multi-lingual speech model. In particular, we use synthesized speech generated from an English-Mandarin text corpus for analysis and training of a multi-lingual intent classification model. We also demonstrate that the teacher-student learning approach obtains an improved performance (91.02%) over the traditional end-to-end (89.40%) intent classification approach in a practical multi-lingual scenario.
Knowledge Distillation from BERT Transformer to Speech Transformer for Intent Classification
Aug 05, 2021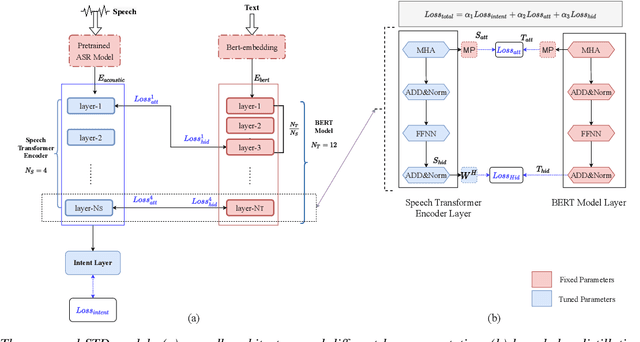
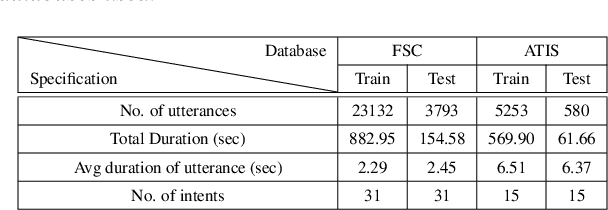
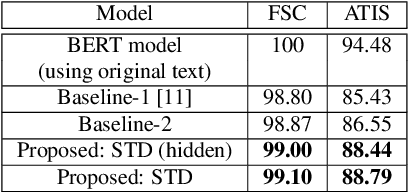
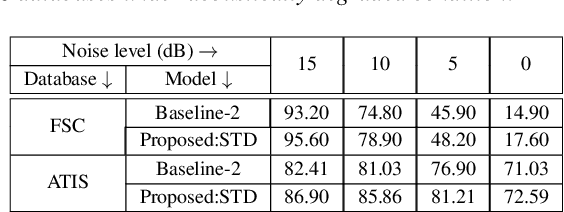
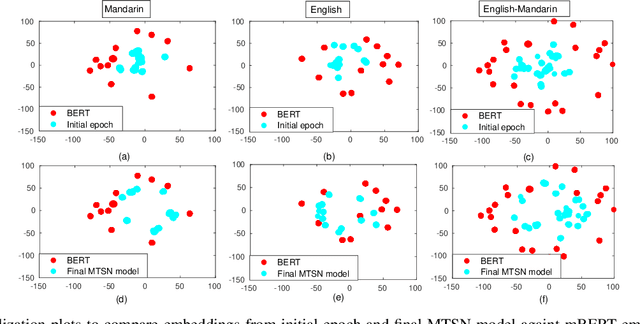
End-to-end intent classification using speech has numerous advantages compared to the conventional pipeline approach using automatic speech recognition (ASR), followed by natural language processing modules. It attempts to predict intent from speech without using an intermediate ASR module. However, such end-to-end framework suffers from the unavailability of large speech resources with higher acoustic variation in spoken language understanding. In this work, we exploit the scope of the transformer distillation method that is specifically designed for knowledge distillation from a transformer based language model to a transformer based speech model. In this regard, we leverage the reliable and widely used bidirectional encoder representations from transformers (BERT) model as a language model and transfer the knowledge to build an acoustic model for intent classification using the speech. In particular, a multilevel transformer based teacher-student model is designed, and knowledge distillation is performed across attention and hidden sub-layers of different transformer layers of the student and teacher models. We achieve an intent classification accuracy of 99.10% and 88.79% for Fluent speech corpus and ATIS database, respectively. Further, the proposed method demonstrates better performance and robustness in acoustically degraded condition compared to the baseline method.
SLoClas: A Database for Joint Sound Localization and Classification
Aug 05, 2021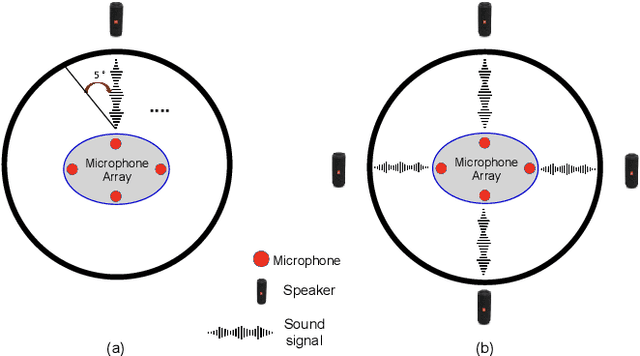

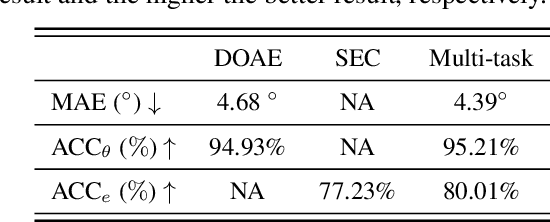
In this work, we present the development of a new database, namely Sound Localization and Classification (SLoClas) corpus, for studying and analyzing sound localization and classification. The corpus contains a total of 23.27 hours of data recorded using a 4-channel microphone array. 10 classes of sounds are played over a loudspeaker at 1.5 meters distance from the array by varying the Direction-of-Arrival (DoA) from 1 degree to 360 degree at an interval of 5 degree. To facilitate the study of noise robustness, 6 types of outdoor noise are recorded at 4 DoAs, using the same devices. Moreover, we propose a baseline method, namely Sound Localization and Classification Network (SLCnet) and present the experimental results and analysis conducted on the collected SLoClas database. We achieve the accuracy of 95.21% and 80.01% for sound localization and classification, respectively. We publicly release this database and the source code for research purpose.
Sonority Measurement Using System, Source, and Suprasegmental Information
Jul 01, 2021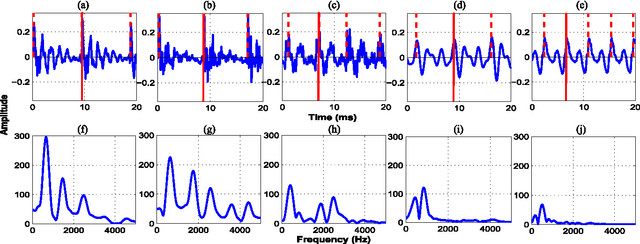


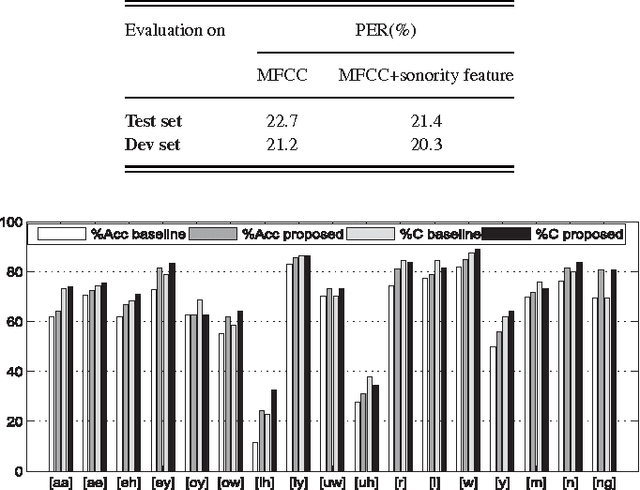
Sonorant sounds are characterized by regions with prominent formant structure, high energy and high degree of periodicity. In this work, the vocal-tract system, excitation source and suprasegmental features derived from the speech signal are analyzed to measure the sonority information present in each of them. Vocal-tract system information is extracted from the Hilbert envelope of numerator of group delay function. It is derived from zero time windowed speech signal that provides better resolution of the formants. A five-dimensional feature set is computed from the estimated formants to measure the prominence of the spectral peaks. A feature representing strength of excitation is derived from the Hilbert envelope of linear prediction residual, which represents the source information. Correlation of speech over ten consecutive pitch periods is used as the suprasegmental feature representing periodicity information. The combination of evidences from the three different aspects of speech provides better discrimination among different sonorant classes, compared to the baseline MFCC features. The usefulness of the proposed sonority feature is demonstrated in the tasks of phoneme recognition and sonorant classification.
Leveraging Acoustic and Linguistic Embeddings from Pretrained speech and language Models for Intent Classification
Feb 15, 2021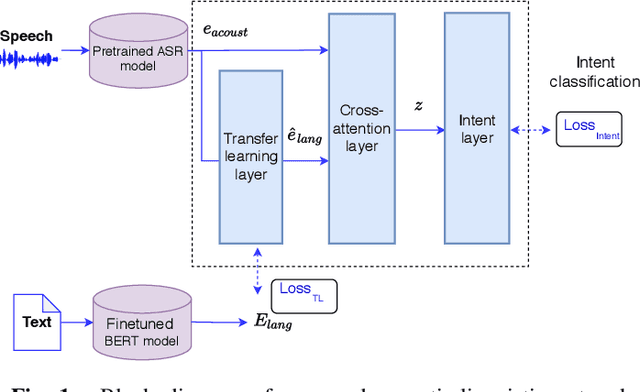
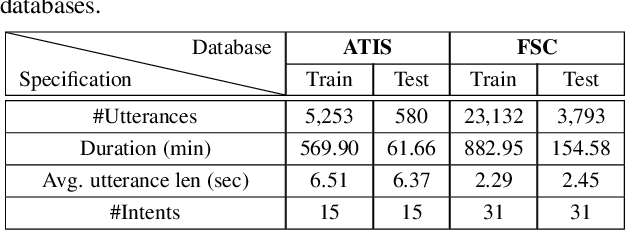
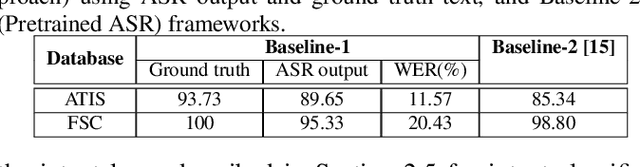
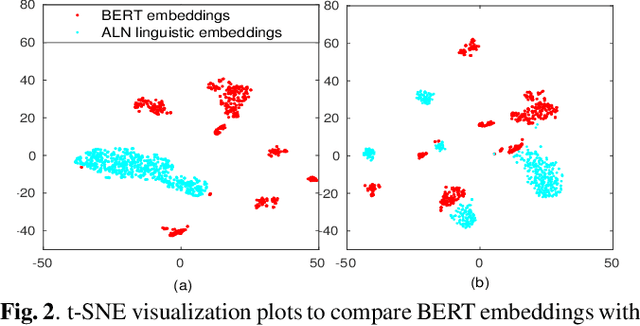
Intent classification is a task in spoken language understanding. An intent classification system is usually implemented as a pipeline process, with a speech recognition module followed by text processing that classifies the intents. There are also studies of end-to-end system that takes acoustic features as input and classifies the intents directly. Such systems don't take advantage of relevant linguistic information, and suffer from limited training data. In this work, we propose a novel intent classification framework that employs acoustic features extracted from a pretrained speech recognition system and linguistic features learned from a pretrained language model. We use knowledge distillation technique to map the acoustic embeddings towards linguistic embeddings. We perform fusion of both acoustic and linguistic embeddings through cross-attention approach to classify intents. With the proposed method, we achieve 90.86% and 99.07% accuracy on ATIS and Fluent speech corpus, respectively.