 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Prompt Sensitivity in LLM-based Speech Recognition Through Learnable Projection
Jan 28, 2026LLM-based automatic speech recognition (ASR), a well-established approach, connects speech foundation models to large language models (LLMs) through a speech-to-LLM projector, yielding promising results. A common design choice in these architectures is the use of a fixed, manually defined prompt during both training and inference. This setup not only enables applicability across a range of practical scenarios, but also helps maximize model performance. However, the impact of prompt design remains underexplored. This paper presents a comprehensive analysis of commonly used prompts across diverse datasets, showing that prompt choice significantly affects ASR performance and introduces instability, with no single prompt performing best across all cases. Inspired by the speech-to-LLM projector, we propose a prompt projector module, a simple, model-agnostic extension that learns to project prompt embeddings to more effective regions of the LLM input space, without modifying the underlying LLM-based ASR model. Experiments on four datasets show that the addition of a prompt projector consistently improves performance, reduces variability, and outperforms the best manually selected prompts.
Text-only adaptation in LLM-based ASR through text denoising
Jan 28, 2026Adapting automatic speech recognition (ASR) systems based on large language models (LLMs) to new domains using text-only data is a significant yet underexplored challenge. Standard fine-tuning of the LLM on target-domain text often disrupts the critical alignment between speech and text modalities learned by the projector, degrading performance. We introduce a novel text-only adaptation method that emulates the audio projection task by treating it as a text denoising task. Our approach thus trains the LLM to recover clean transcripts from noisy inputs. This process effectively adapts the model to a target domain while preserving cross-modal alignment. Our solution is lightweight, requiring no architectural changes or additional parameters. Extensive evaluation on two datasets demonstrates up to 22.1% relative improvement, outperforming recent state-of-the-art text-only adaptation methods.
Slot Filling as a Reasoning Task for SpeechLLMs
Oct 22, 2025We propose integration of reasoning into speech large language models (speechLLMs) for the end-to-end slot-filling task. Inspired by the recent development of reasoning LLMs, we use a chain-of-thought framework to decompose the slot-filling task into multiple reasoning steps, create a reasoning dataset and apply the supervised fine-tuning strategy to a speechLLM. We distinguish between regular and reasoning speechLLMs and experiment with different types and sizes of LLMs as their text foundation models. We demonstrate performance improvements by introducing reasoning (intermediate) steps. However, we show that a reasoning textual LLM developed mainly for math, logic and coding domains might be inferior as a foundation model for a reasoning speechLLM. We further show that hybrid speechLLMs, built on a hybrid text foundation LLM and fine-tuned to preserve both direct and reasoning modes of operation, have better performance than those fine-tuned employing only one mode of operation.
Better Semi-supervised Learning for Multi-domain ASR Through Incremental Retraining and Data Filtering
Jun 05, 2025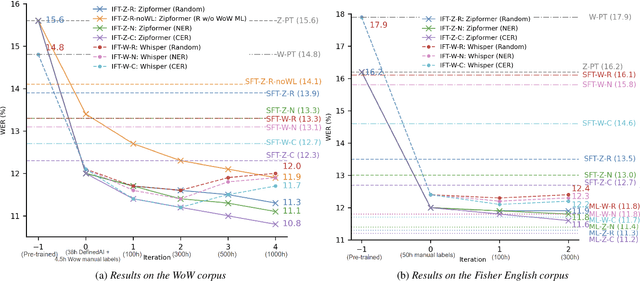
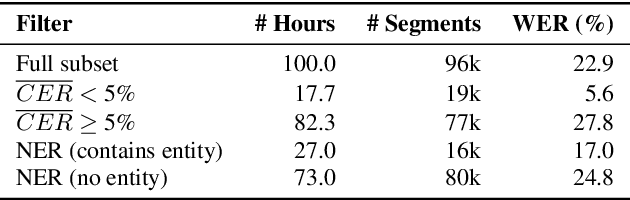

Fine-tuning pretrained ASR models for specific domains is challenging when labeled data is scarce. But unlabeled audio and labeled data from related domains are often available. We propose an incremental semi-supervised learning pipeline that first integrates a small in-domain labeled set and an auxiliary dataset from a closely related domain, achieving a relative improvement of 4% over no auxiliary data. Filtering based on multi-model consensus or named entity recognition (NER) is then applied to select and iteratively refine pseudo-labels, showing slower performance saturation compared to random selection. Evaluated on the multi-domain Wow call center and Fisher English corpora, it outperforms single-step fine-tuning. Consensus-based filtering outperforms other methods, providing up to 22.3% relative improvement on Wow and 24.8% on Fisher over single-step fine-tuning with random selection. NER is the second-best filter, providing competitive performance at a lower computational cost.
Zero-shot Slot Filling in the Age of LLMs for Dialogue Systems
Nov 28, 2024Zero-shot slot filling is a well-established subtask of Natural Language Understanding (NLU). However, most existing methods primarily focus on single-turn text data, overlooking the unique complexities of conversational dialogue. Conversational data is highly dynamic, often involving abrupt topic shifts, interruptions, and implicit references that make it difficult to directly apply zero-shot slot filling techniques, even with the remarkable capabilities of large language models (LLMs). This paper addresses these challenges by proposing strategies for automatic data annotation with slot induction and black-box knowledge distillation (KD) from a teacher LLM to a smaller model, outperforming vanilla LLMs on internal datasets by 26% absolute increase in F1 score. Additionally, we introduce an efficient system architecture for call center product settings that surpasses off-the-shelf extractive models by 34% relative F1 score, enabling near real-time inference on dialogue streams with higher accuracy, while preserving low latency.