 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-only adaptation in LLM-based ASR through text denoising
Jan 28, 2026Adapting automatic speech recognition (ASR) systems based on large language models (LLMs) to new domains using text-only data is a significant yet underexplored challenge. Standard fine-tuning of the LLM on target-domain text often disrupts the critical alignment between speech and text modalities learned by the projector, degrading performance. We introduce a novel text-only adaptation method that emulates the audio projection task by treating it as a text denoising task. Our approach thus trains the LLM to recover clean transcripts from noisy inputs. This process effectively adapts the model to a target domain while preserving cross-modal alignment. Our solution is lightweight, requiring no architectural changes or additional parameters. Extensive evaluation on two datasets demonstrates up to 22.1% relative improvement, outperforming recent state-of-the-art text-only adaptation methods.
Reducing Prompt Sensitivity in LLM-based Speech Recognition Through Learnable Projection
Jan 28, 2026LLM-based automatic speech recognition (ASR), a well-established approach, connects speech foundation models to large language models (LLMs) through a speech-to-LLM projector, yielding promising results. A common design choice in these architectures is the use of a fixed, manually defined prompt during both training and inference. This setup not only enables applicability across a range of practical scenarios, but also helps maximize model performance. However, the impact of prompt design remains underexplored. This paper presents a comprehensive analysis of commonly used prompts across diverse datasets, showing that prompt choice significantly affects ASR performance and introduces instability, with no single prompt performing best across all cases. Inspired by the speech-to-LLM projector, we propose a prompt projector module, a simple, model-agnostic extension that learns to project prompt embeddings to more effective regions of the LLM input space, without modifying the underlying LLM-based ASR model. Experiments on four datasets show that the addition of a prompt projector consistently improves performance, reduces variability, and outperforms the best manually selected prompts.
TokenVerse++: Towards Flexible Multitask Learning with Dynamic Task Activation
Aug 27, 2025Token-based multitasking frameworks like TokenVerse require all training utterances to have labels for all tasks, hindering their ability to leverage partially annotated datasets and scale effectively. We propose TokenVerse++, which introduces learnable vectors in the acoustic embedding space of the XLSR-Transducer ASR model for dynamic task activation. This core mechanism enables training with utterances labeled for only a subset of tasks, a key advantage over TokenVerse. We demonstrate this by successfully integrating a dataset with partial labels, specifically for ASR and an additional task, language identification, improving overall performance. TokenVerse++ achieves results on par with or exceeding TokenVerse across multiple tasks, establishing it as a more practical multitask alternative without sacrificing ASR performance.
Unifying Streaming and Non-streaming Zipformer-based ASR
Jun 17, 2025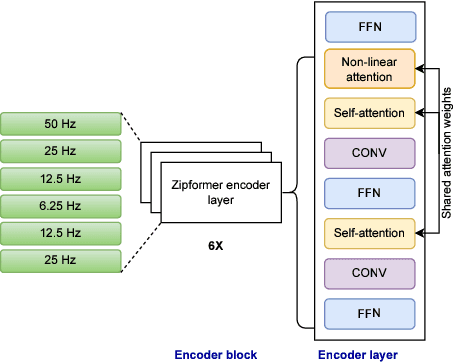
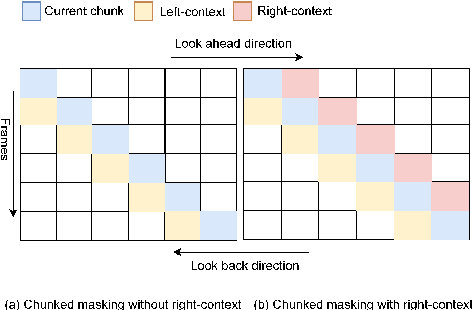
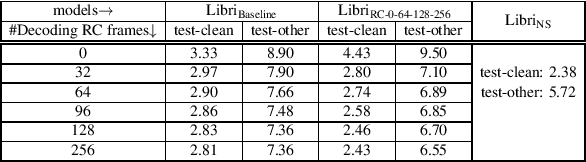
There has been increasing interest in unifying streaming and non-streaming automatic speech recognition (ASR) models to reduce development, training, and deployment costs. We present a unified framework that trains a single end-to-end ASR model for both streaming and non-streaming applications, leveraging future context information. We propose to use dynamic right-context through the chunked attention masking in the training of zipformer-based ASR models. We demonstrate that using right-context is more effective in zipformer models compared to other conformer models due to its multi-scale nature. We analyze the effect of varying the number of right-context frames on accuracy and latency of the streaming ASR models. We use Librispeech and large in-house conversational datasets to train different versions of streaming and non-streaming models and evaluate them in a production grade server-client setup across diverse testsets of different domains. The proposed strategy reduces word error by relative 7.9\% with a small degradation in user-perceived latency. By adding more right-context frames, we are able to achieve streaming performance close to that of non-streaming models. Our approach also allows flexible control of the latency-accuracy tradeoff according to customers requirements.
Better Semi-supervised Learning for Multi-domain ASR Through Incremental Retraining and Data Filtering
Jun 05, 2025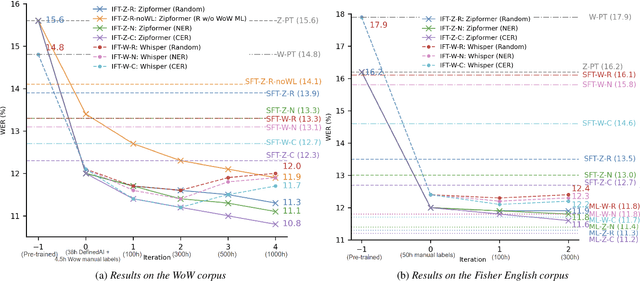
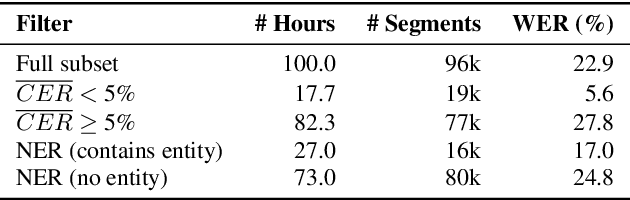

Fine-tuning pretrained ASR models for specific domains is challenging when labeled data is scarce. But unlabeled audio and labeled data from related domains are often available. We propose an incremental semi-supervised learning pipeline that first integrates a small in-domain labeled set and an auxiliary dataset from a closely related domain, achieving a relative improvement of 4% over no auxiliary data. Filtering based on multi-model consensus or named entity recognition (NER) is then applied to select and iteratively refine pseudo-labels, showing slower performance saturation compared to random selection. Evaluated on the multi-domain Wow call center and Fisher English corpora, it outperforms single-step fine-tuning. Consensus-based filtering outperforms other methods, providing up to 22.3% relative improvement on Wow and 24.8% on Fisher over single-step fine-tuning with random selection. NER is the second-best filter, providing competitive performance at a lower computational cost.
A Differentiable Alignment Framework for Sequence-to-Sequence Modeling via Optimal Transport
Feb 03, 2025



Accurate sequence-to-sequence (seq2seq) alignment is critical for applications like medical speech analysis and language learning tools relying on automatic speech recognition (ASR). State-of-the-art end-to-end (E2E) ASR systems, such as the Connectionist Temporal Classification (CTC) and transducer-based models, suffer from peaky behavior and alignment inaccuracies. In this paper, we propose a novel differentiable alignment framework based on one-dimensional optimal transport, enabling the model to learn a single alignment and perform ASR in an E2E manner. We introduce a pseudo-metric, called Sequence Optimal Transport Distance (SOTD), over the sequence space and discuss its theoretical properties. Based on the SOTD, we propose Optimal Temporal Transport Classification (OTTC) loss for ASR and contrast its behavior with CTC. Experimental results on the TIMIT, AMI, and LibriSpeech datasets show that our method considerably improves alignment performance, though with a trade-off in ASR performance when compared to CTC. We believe this work opens new avenues for seq2seq alignment research, providing a solid foundation for further exploration and development within the community.
Performance evaluation of SLAM-ASR: The Good, the Bad, the Ugly, and the Way Forward
Nov 06, 2024



Recent research has demonstrated that training a linear connector between speech foundation encoders and large language models (LLMs) enables this architecture to achieve strong ASR capabilities. Despite the impressive results, it remains unclear whether these simple approaches are robust enough across different scenarios and speech conditions, such as domain shifts and different speech perturbations. In this paper, we address these questions by conducting various ablation experiments using a recent and widely adopted approach called SLAM-ASR. We present novel empirical findings that offer insights on how to effectively utilize the SLAM-ASR architecture across a wide range of settings. Our main findings indicate that the SLAM-ASR exhibits poor performance in cross-domain evaluation settings. Additionally, speech perturbations within in-domain data, such as changes in speed or the presence of additive noise, can significantly impact performance. Our findings offer critical insights for fine-tuning and configuring robust LLM-based ASR models, tailored to different data characteristics and computational resources.
TokenVerse: Unifying Speech and NLP Tasks via Transducer-based ASR
Jul 05, 2024



In traditional conversational intelligence from speech, a cascaded pipeline is used, involving tasks such as voice activity detection, diarization, transcription, and subsequent processing with different NLP models for tasks like semantic endpointing and named entity recognition (NER). Our paper introduces TokenVerse, a single Transducer-based model designed to handle multiple tasks. This is achieved by integrating task-specific tokens into the reference text during ASR model training, streamlining the inference and eliminating the need for separate NLP models. In addition to ASR, we conduct experiments on 3 different tasks: speaker change detection, endpointing, and NER. Our experiments on a public and a private dataset show that the proposed method improves ASR by up to 7.7% in relative WER while outperforming the cascaded pipeline approach in individual task performance. Additionally, we present task transfer learning to a new task within an existing TokenVerse.
XLSR-Transducer: Streaming ASR for Self-Supervised Pretrained Models
Jul 05, 2024



Self-supervised pretrained models exhibit competitive performance in automatic speech recognition on finetuning, even with limited in-domain supervised data for training. However, popular pretrained models are not suitable for streaming ASR because they are trained with full attention context. In this paper, we introduce XLSR-Transducer, where the XLSR-53 model is used as encoder in transducer setup. Our experiments on the AMI dataset reveal that the XLSR-Transducer achieves 4% absolute WER improvement over Whisper large-v2 and 8% over a Zipformer transducer model trained from scratch.To enable streaming capabilities, we investigate different attention masking patterns in the self-attention computation of transformer layers within the XLSR-53 model. We validate XLSR-Transducer on AMI and 5 languages from CommonVoice under low-resource scenarios. Finally, with the introduction of attention sinks, we reduce the left context by half while achieving a relative 12% improvement in WER.
Improved far-field speech recognition using Joint Variational Autoencoder
Apr 24, 2022
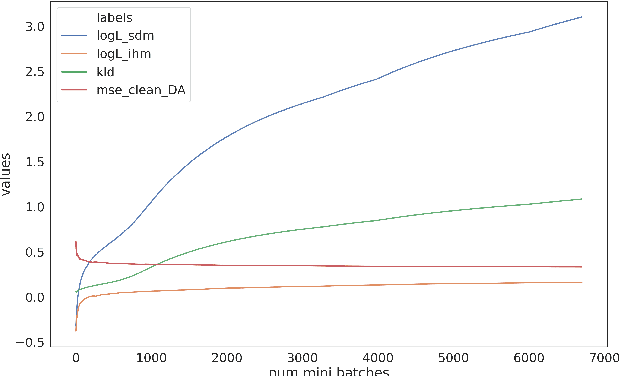

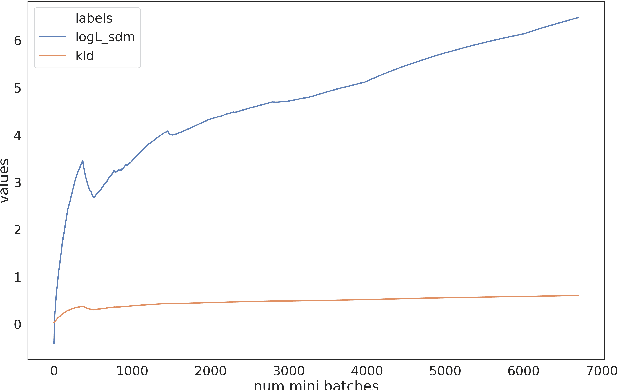
Automatic Speech Recognition (ASR) systems suffer considerably when source speech is corrupted with noise or room impulse responses (RIR). Typically, speech enhancement is applied in both mismatched and matched scenario training and testing. In matched setting, acoustic model (AM) is trained on dereverberated far-field features while in mismatched setting, AM is fixed. In recent past, mapping speech features from far-field to close-talk using denoising autoencoder (DA) has been explored. In this paper, we focus on matched scenario training and show that the proposed joint VAE based mapping achieves a significant improvement over DA. Specifically, we observe an absolute improvement of 2.5% in word error rate (WER) compared to DA based enhancement and 3.96% compared to AM trained directly on far-field filterbank features.