 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Textures: Learning from Multi-domain Artistic Images for Arbitrary Style Transfer
May 25, 2018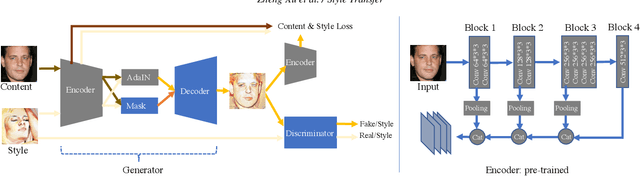



We propose a fast feed-forward network for arbitrary style transfer, which can generate stylized image for previously unseen content and style image pairs. Besides the traditional content and style representation based on deep features and statistics for textures, we use adversarial networks to regularize the generation of stylized images. Our adversarial network learns the intrinsic property of image styles from large-scale multi-domain artistic images. The adversarial training is challenging because both the input and output of our generator are diverse multi-domain images. We use a conditional generator that stylized content by shifting the statistics of deep features, and a conditional discriminator based on the coarse category of styles. Moreover, we propose a mask module to spatially decide the stylization level and stabilize adversarial training by avoiding mode collapse. As a side effect, our trained discriminator can be applied to rank and select representative stylized images. We qualitatively and quantitatively evaluate the proposed method, and compare with recent style transfer methods.
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
Oct 27, 2016


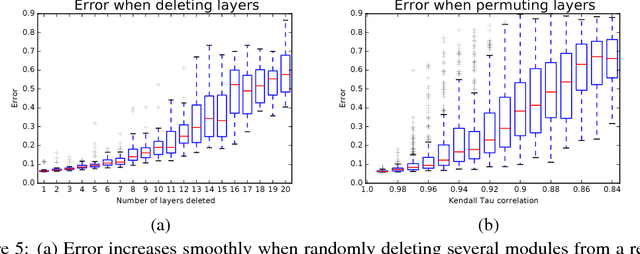
In this work we propose a novel interpretation of residual networks showing that they can be seen as a collection of many paths of differing length. Moreover, residual networks seem to enable very deep networks by leveraging only the short paths during training. To support this observation, we rewrite residual networks as an explicit collection of paths. Unlike traditional models, paths through residual networks vary in length. Further, a lesion study reveals that these paths show ensemble-like behavior in the sense that they do not strongly depend on each other. Finally, and most surprising, most paths are shorter than one might expect, and only the short paths are needed during training, as longer paths do not contribute any gradient. For example, most of the gradient in a residual network with 110 layers comes from paths that are only 10-34 layers deep. Our results reveal one of the key characteristics that seem to enable the training of very deep networks: Residual networks avoid the vanishing gradient problem by introducing short paths which can carry gradient throughout the extent of very deep networks.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015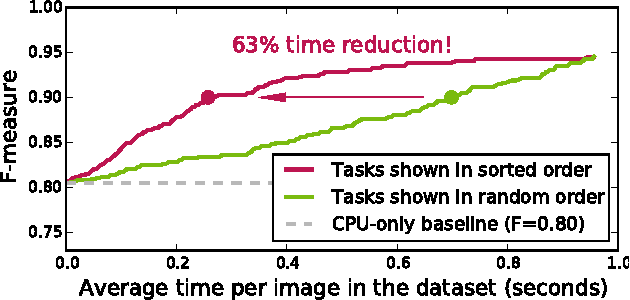
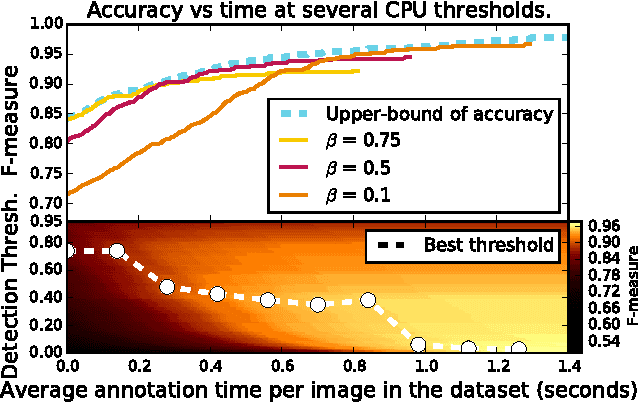
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.