 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Defines Fairness? Target-Based Prompting for Demographic Representation in Generative Models
Apr 22, 2026Text-to-image(T2I) models like Stable Diffusion and DALL-E have made generative AI widely accessible, yet recent studies reveal that these systems often replicate societal biases, particularly in how they depict demographic groups across professions. Prompts such as 'doctor' or 'CEO' frequently yield lighter-skinned outputs, while lower-status roles like 'janitor' show more diversity, reinforcing stereotypes. Existing mitigation methods typically require retraining or curated datasets, making them inaccessible to most users. We propose a lightweight, inference-time framework that mitigates representational bias through prompt-level intervention without modifying the underlying model. Instead of assuming a single definition of fairness, our approach allows users to select among multiple fairness specifications-ranging from simple choices such as a uniform distribution to more complex definitions informed by a large language model(LLM) that cites sources and provides confidence estimates. These distributions guide the construction of demographic specific prompt variants in the corresponding proportions, and we evaluate alignment by auditing adherence to the declared target and measuring the resulting skin tone distribution rather than assuming uniformity as 'fairness'. Across 36 prompts spanning 30 occupations and 6 non-occupational contexts, our method shifts observed skin-tone outcomes in directions consistent with the declared target, and reduces deviation from targets when the target is defined directly in skin-tone space(fallback). This work demonstrates how fairness interventions can be made transparent, controllable, and usable at inference time, directly empowering users of generative AI.
Hidden in Plain Text: Measuring LLM Deception Quality Against Human Baselines Using Social Deduction Games
Jan 20, 2026Large Language Model (LLM) agents are increasingly used in many applications, raising concerns about their safety. While previous work has shown that LLMs can deceive in controlled tasks, less is known about their ability to deceive using natural language in social contexts. In this paper, we study deception in the Social Deduction Game (SDG) Mafia, where success is dependent on deceiving others through conversation. Unlike previous SDG studies, we use an asynchronous multi-agent framework which better simulates realistic social contexts. We simulate 35 Mafia games with GPT-4o LLM agents. We then create a Mafia Detector using GPT-4-Turbo to analyze game transcripts without player role information to predict the mafia players. We use prediction accuracy as a surrogate marker for deception quality. We compare this prediction accuracy to that of 28 human games and a random baseline. Results show that the Mafia Detector's mafia prediction accuracy is lower on LLM games than on human games. The result is consistent regardless of the game days and the number of mafias detected. This indicates that LLMs blend in better and thus deceive more effectively. We also release a dataset of LLM Mafia transcripts to support future research. Our findings underscore both the sophistication and risks of LLM deception in social contexts.
AI for Green Spaces: Leveraging Autonomous Navigation and Computer Vision for Park Litter Removal
Jan 17, 2026There are 50 billion pieces of litter in the U.S. alone. Grass fields contribute to this problem because picnickers tend to leave trash on the field. We propose building a robot that can autonomously navigate, identify, and pick up trash in parks. To autonomously navigate the park, we used a Spanning Tree Coverage (STC) algorithm to generate a coverage path the robot could follow. To navigate this path, we successfully used Real-Time Kinematic (RTK) GPS, which provides a centimeter-level reading every second. For computer vision, we utilized the ResNet50 Convolutional Neural Network (CNN), which detects trash with 94.52% accuracy. For trash pickup, we tested multiple design concepts. We select a new pickup mechanism that specifically targets the trash we encounter on the field. Our solution achieved an overall success rate of 80%, demonstrating that autonomous trash pickup robots on grass fields are a viable solution.
* Published in IEEE/SICE SII 2025
Guideline-Consistent Segmentation via Multi-Agent Refinement
Sep 04, 2025Semantic segmentation in real-world applications often requires not only accurate masks but also strict adherence to textual labeling guidelines. These guidelines are typically complex and long, and both human and automated labeling often fail to follow them faithfully. Traditional approaches depend on expensive task-specific retraining that must be repeated as the guidelines evolve. Although recent open-vocabulary segmentation methods excel with simple prompts, they often fail when confronted with sets of paragraph-length guidelines that specify intricate segmentation rules. To address this, we introduce a multi-agent, training-free framework that coordinates general-purpose vision-language models within an iterative Worker-Supervisor refinement architecture. The Worker performs the segmentation, the Supervisor critiques it against the retrieved guidelines, and a lightweight reinforcement learning stop policy decides when to terminate the loop, ensuring guideline-consistent masks while balancing resource use. Evaluated on the Waymo and ReasonSeg datasets, our method notably outperforms state-of-the-art baselines, demonstrating strong generalization and instruction adherence.
GenIR: Generative Visual Feedback for Mental Image Retrieval
Jun 06, 2025Vision-language models (VLMs) have shown strong performance on text-to-image retrieval benchmarks. However, bridging this success to real-world applications remains a challenge. In practice, human search behavior is rarely a one-shot action. Instead, it is often a multi-round process guided by clues in mind, that is, a mental image ranging from vague recollections to vivid mental representations of the target image. Motivated by this gap, we study the task of Mental Image Retrieval (MIR), which targets the realistic yet underexplored setting where users refine their search for a mentally envisioned image through multi-round interactions with an image search engine. Central to successful interactive retrieval is the capability of machines to provide users with clear, actionable feedback; however, existing methods rely on indirect or abstract verbal feedback, which can be ambiguous, misleading, or ineffective for users to refine the query. To overcome this, we propose GenIR, a generative multi-round retrieval paradigm leveraging diffusion-based image generation to explicitly reify the AI system's understanding at each round. These synthetic visual representations provide clear, interpretable feedback, enabling users to refine their queries intuitively and effectively. We further introduce a fully automated pipeline to generate a high-quality multi-round MIR dataset. Experimental results demonstrate that GenIR significantly outperforms existing interactive methods in the MIR scenario. This work establishes a new task with a dataset and an effective generative retrieval method, providing a foundation for future research in this direction.
J-CaPA : Joint Channel and Pyramid Attention Improves Medical Image Segmentation
Nov 25, 2024Medical image segmentation is crucial for diagnosis and treatment planning. Traditional CNN-based models, like U-Net, have shown promising results but struggle to capture long-range dependencies and global context. To address these limitations, we propose a transformer-based architecture that jointly applies Channel Attention and Pyramid Attention mechanisms to improve multi-scale feature extraction and enhance segmentation performance for medical images. Increasing model complexity requires more training data, and we further improve model generalization with CutMix data augmentation. Our approach is evaluated on the Synapse multi-organ segmentation dataset, achieving a 6.9% improvement in Mean Dice score and a 39.9% improvement in Hausdorff Distance (HD95) over an implementation without our enhancements. Our proposed model demonstrates improved segmentation accuracy for complex anatomical structures, outperforming existing state-of-the-art methods.
Automatic Dataset Construction (ADC): Sample Collection, Data Curation, and Beyond
Aug 21, 2024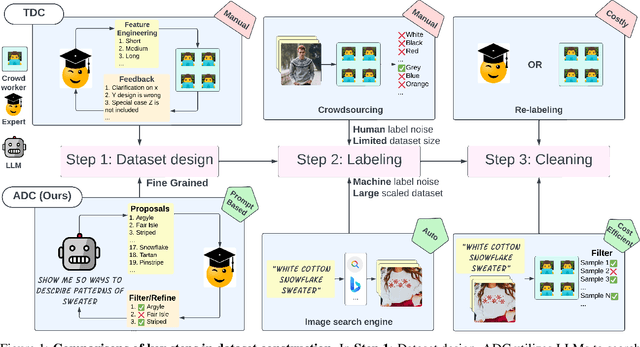

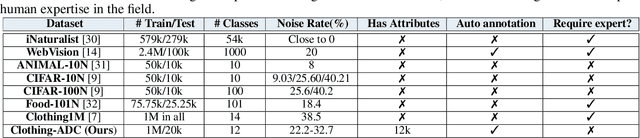
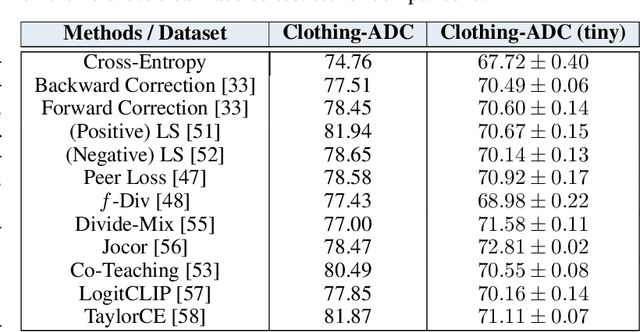
Large-scale data collection is essential for developing personalized training data, mitigating the shortage of training data, and fine-tuning specialized models. However, creating high-quality datasets quickly and accurately remains a challenge due to annotation errors, the substantial time and costs associated with human labor. To address these issues, we propose Automatic Dataset Construction (ADC), an innovative methodology that automates dataset creation with negligible cost and high efficiency. Taking the image classification task as a starting point, ADC leverages LLMs for the detailed class design and code generation to collect relevant samples via search engines, significantly reducing the need for manual annotation and speeding up the data generation process. Despite these advantages, ADC also encounters real-world challenges such as label errors (label noise) and imbalanced data distributions (label bias). We provide open-source software that incorporates existing methods for label error detection, robust learning under noisy and biased data, ensuring a higher-quality training data and more robust model training procedure. Furthermore, we design three benchmark datasets focused on label noise detection, label noise learning, and class-imbalanced learning. These datasets are vital because there are few existing datasets specifically for label noise detection, despite its importance. Finally, we evaluate the performance of existing popular methods on these datasets, thereby facilitating further research in the field.
Reducing Vision Transformer Latency on Edge Devices via GPU Tail Effect and Training-free Token Pruning
Jul 01, 2024This paper investigates how to efficiently deploy transformer-based neural networks on edge devices. Recent methods reduce the latency of transformer neural networks by removing or merging tokens, with small accuracy degradation. However, these methods are not designed with edge device deployment in mind, and do not leverage information about the hardware characteristics to improve efficiency. First, we show that the relationship between latency and workload size is governed by the GPU tail-effect. This relationship is used to create a token pruning schedule tailored for a pre-trained model and device pair. Second, we demonstrate a training-free token pruning method utilizing this relationship. This method achieves accuracy-latency trade-offs in a hardware aware manner. We show that for single batch inference, other methods may actually increase latency by 18.6-30.3% with respect to baseline, while we can reduce it by 9%. For similar latency (within 5.2%) across devices we achieve 78.6%-84.5% ImageNet1K accuracy, while the state-of-the-art, Token Merging, achieves 45.8%-85.4%.
VortexViz: Finding Vortex Boundaries by Learning from Particle Trajectories
Apr 01, 2024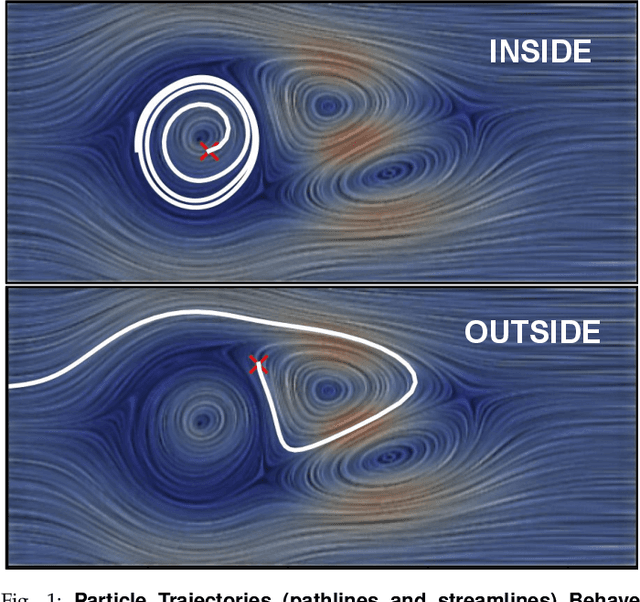
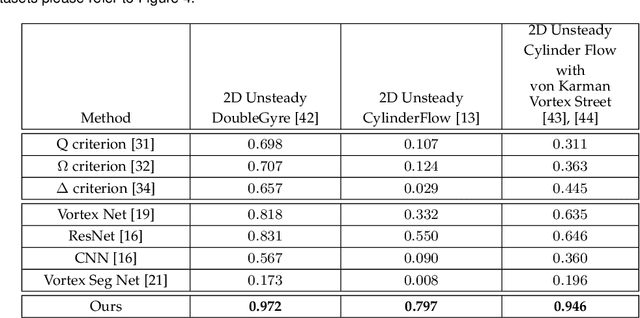
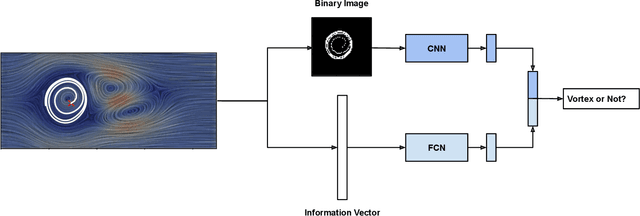
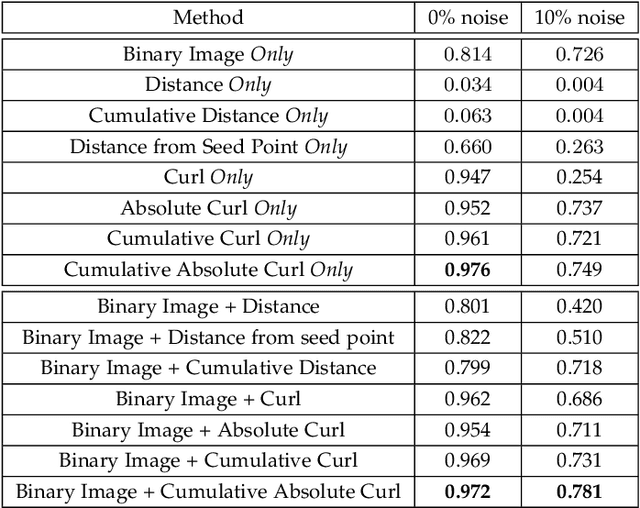
Vortices are studied in various scientific disciplines, offering insights into fluid flow behavior. Visualizing the boundary of vortices is crucial for understanding flow phenomena and detecting flow irregularities. This paper addresses the challenge of accurately extracting vortex boundaries using deep learning techniques. While existing methods primarily train on velocity components, we propose a novel approach incorporating particle trajectories (streamlines or pathlines) into the learning process. By leveraging the regional/local characteristics of the flow field captured by streamlines or pathlines, our methodology aims to enhance the accuracy of vortex boundary extraction.
SplatFace: Gaussian Splat Face Reconstruction Leveraging an Optimizable Surface
Mar 29, 2024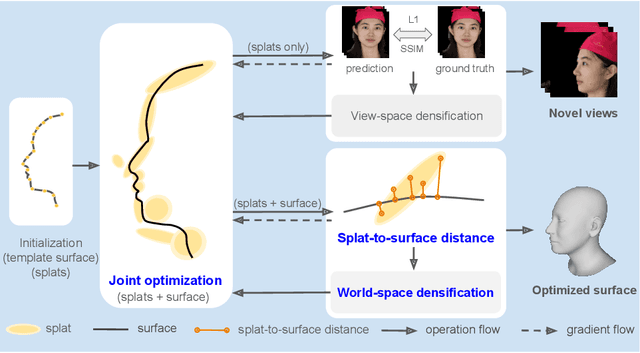
We present SplatFace, a novel Gaussian splatting framework designed for 3D human face reconstruction without reliance on accurate pre-determined geometry. Our method is designed to simultaneously deliver both high-quality novel view rendering and accurate 3D mesh reconstructions. We incorporate a generic 3D Morphable Model (3DMM) to provide a surface geometric structure, making it possible to reconstruct faces with a limited set of input images. We introduce a joint optimization strategy that refines both the Gaussians and the morphable surface through a synergistic non-rigid alignment process. A novel distance metric, splat-to-surface, is proposed to improve alignment by considering both the Gaussian position and covariance. The surface information is also utilized to incorporate a world-space densification process, resulting in superior reconstruction quality. Our experimental analysis demonstrates that the proposed method is competitive with both other Gaussian splatting techniques in novel view synthesis and other 3D reconstruction methods in producing 3D face meshes with high geometric precision.