 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden in Plain Text: Measuring LLM Deception Quality Against Human Baselines Using Social Deduction Games
Jan 20, 2026Large Language Model (LLM) agents are increasingly used in many applications, raising concerns about their safety. While previous work has shown that LLMs can deceive in controlled tasks, less is known about their ability to deceive using natural language in social contexts. In this paper, we study deception in the Social Deduction Game (SDG) Mafia, where success is dependent on deceiving others through conversation. Unlike previous SDG studies, we use an asynchronous multi-agent framework which better simulates realistic social contexts. We simulate 35 Mafia games with GPT-4o LLM agents. We then create a Mafia Detector using GPT-4-Turbo to analyze game transcripts without player role information to predict the mafia players. We use prediction accuracy as a surrogate marker for deception quality. We compare this prediction accuracy to that of 28 human games and a random baseline. Results show that the Mafia Detector's mafia prediction accuracy is lower on LLM games than on human games. The result is consistent regardless of the game days and the number of mafias detected. This indicates that LLMs blend in better and thus deceive more effectively. We also release a dataset of LLM Mafia transcripts to support future research. Our findings underscore both the sophistication and risks of LLM deception in social contexts.
Guideline-Consistent Segmentation via Multi-Agent Refinement
Sep 04, 2025Semantic segmentation in real-world applications often requires not only accurate masks but also strict adherence to textual labeling guidelines. These guidelines are typically complex and long, and both human and automated labeling often fail to follow them faithfully. Traditional approaches depend on expensive task-specific retraining that must be repeated as the guidelines evolve. Although recent open-vocabulary segmentation methods excel with simple prompts, they often fail when confronted with sets of paragraph-length guidelines that specify intricate segmentation rules. To address this, we introduce a multi-agent, training-free framework that coordinates general-purpose vision-language models within an iterative Worker-Supervisor refinement architecture. The Worker performs the segmentation, the Supervisor critiques it against the retrieved guidelines, and a lightweight reinforcement learning stop policy decides when to terminate the loop, ensuring guideline-consistent masks while balancing resource use. Evaluated on the Waymo and ReasonSeg datasets, our method notably outperforms state-of-the-art baselines, demonstrating strong generalization and instruction adherence.
Few-shot Novel View Synthesis using Depth Aware 3D Gaussian Splatting
Oct 14, 2024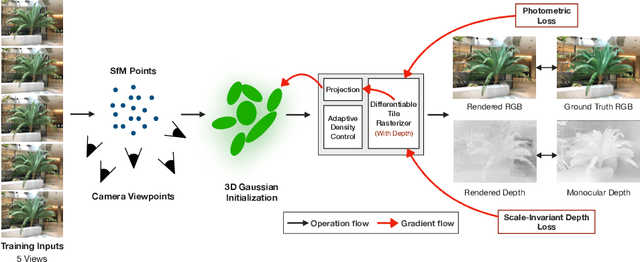



3D Gaussian splatting has surpassed neural radiance field methods in novel view synthesis by achieving lower computational costs and real-time high-quality rendering. Although it produces a high-quality rendering with a lot of input views, its performance drops significantly when only a few views are available. In this work, we address this by proposing a depth-aware Gaussian splatting method for few-shot novel view synthesis. We use monocular depth prediction as a prior, along with a scale-invariant depth loss, to constrain the 3D shape under just a few input views. We also model color using lower-order spherical harmonics to avoid overfitting. Further, we observe that removing splats with lower opacity periodically, as performed in the original work, leads to a very sparse point cloud and, hence, a lower-quality rendering. To mitigate this, we retain all the splats, leading to a better reconstruction in a few view settings. Experimental results show that our method outperforms the traditional 3D Gaussian splatting methods by achieving improvements of 10.5% in peak signal-to-noise ratio, 6% in structural similarity index, and 14.1% in perceptual similarity, thereby validating the effectiveness of our approach. The code will be made available at: https://github.com/raja-kumar/depth-aware-3DGS
A Survey on Human-AI Teaming with Large Pre-Trained Models
Mar 07, 2024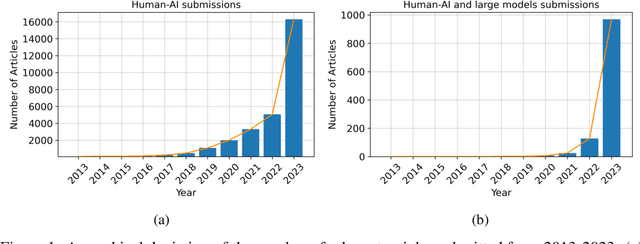
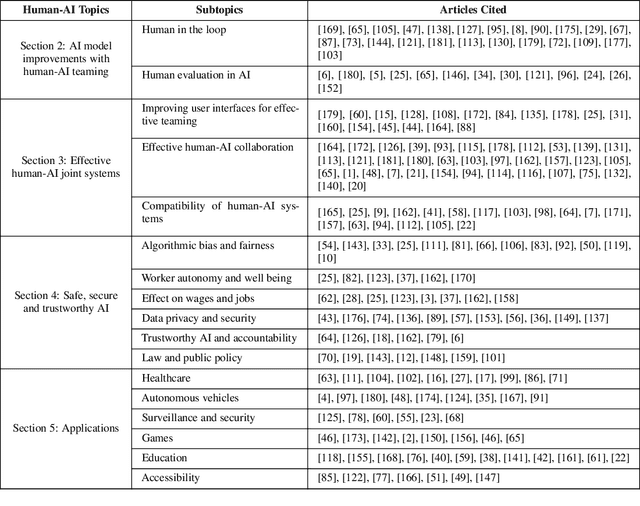
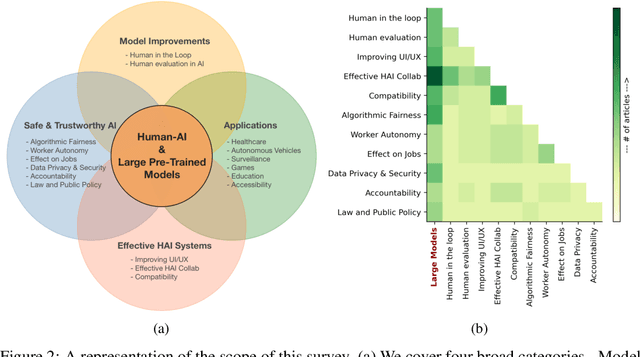
In the rapidly evolving landscape of artificial intelligence (AI), the collaboration between human intelligence and AI systems, known as Human-AI (HAI) Teaming, has emerged as a cornerstone for advancing problem-solving and decision-making processes. The advent of Large Pre-trained Models (LPtM) has significantly transformed this landscape, offering unprecedented capabilities by leveraging vast amounts of data to understand and predict complex patterns. This paper surveys the pivotal integration of LPtMs with HAI, emphasizing how these models enhance collaborative intelligence beyond traditional approaches. It examines the synergistic potential of LPtMs in augmenting human capabilities, discussing this collaboration for AI model improvements, effective teaming, ethical considerations, and their broad applied implications in various sectors. Through this exploration, the study sheds light on the transformative impact of LPtM-enhanced HAI Teaming, providing insights for future research, policy development, and strategic implementations aimed at harnessing the full potential of this collaboration for research and societal benefit.