 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Aware Bayesian Optimization for Prototyping Interactive Devices
Feb 02, 2026Deciding which idea is worth prototyping is a central concern in iterative design. A prototype should be produced when the expected improvement is high and the cost is low. However, this is hard to decide, because costs can vary drastically: a simple parameter tweak may take seconds, while fabricating hardware consumes material and energy. Such asymmetries, can discourage a designer from exploring the design space. In this paper, we present an extension of cost-aware Bayesian optimization to account for diverse prototyping costs. The method builds on the power of Bayesian optimization and requires only a minimal modification to the acquisition function. The key idea is to use designer-estimated costs to guide sampling toward more cost-effective prototypes. In technical evaluations, the method achieved comparable utility to a cost-agnostic baseline while requiring only ${\approx}70\%$ of the cost; under strict budgets, it outperformed the baseline threefold. A within-subjects study with 12 participants in a realistic joystick design task demonstrated similar benefits. These results show that accounting for prototyping costs can make Bayesian optimization more compatible with real-world design projects.
SocialMOIF: Multi-Order Intention Fusion for Pedestrian Trajectory Prediction
Apr 22, 2025The analysis and prediction of agent trajectories are crucial for decision-making processes in intelligent systems, with precise short-term trajectory forecasting being highly significant across a range of applications. Agents and their social interactions have been quantified and modeled by researchers from various perspectives; however, substantial limitations exist in the current work due to the inherent high uncertainty of agent intentions and the complex higher-order influences among neighboring groups. SocialMOIF is proposed to tackle these challenges, concentrating on the higher-order intention interactions among neighboring groups while reinforcing the primary role of first-order intention interactions between neighbors and the target agent. This method develops a multi-order intention fusion model to achieve a more comprehensive understanding of both direct and indirect intention information. Within SocialMOIF, a trajectory distribution approximator is designed to guide the trajectories toward values that align more closely with the actual data, thereby enhancing model interpretability. Furthermore, a global trajectory optimizer is introduced to enable more accurate and efficient parallel predictions. By incorporating a novel loss function that accounts for distance and direction during training, experimental results demonstrate that the model outperforms previous state-of-the-art baselines across multiple metrics in both dynamic and static datasets.
Knowledge-Guided Wasserstein Distributionally Robust Optimization
Feb 12, 2025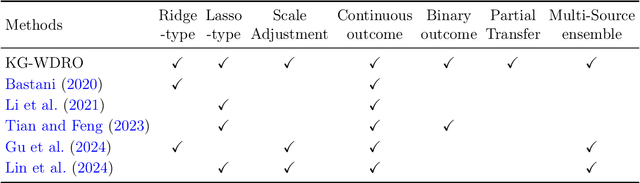
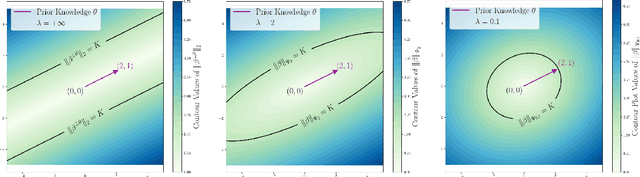
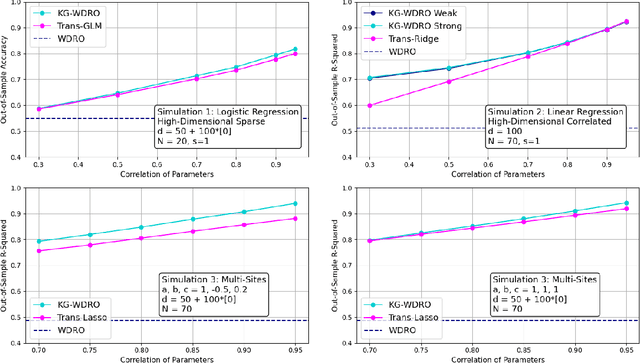
Transfer learning is a popular strategy to leverage external knowledge and improve statistical efficiency, particularly with a limited target sample. We propose a novel knowledge-guided Wasserstein Distributionally Robust Optimization (KG-WDRO) framework that adaptively incorporates multiple sources of external knowledge to overcome the conservativeness of vanilla WDRO, which often results in overly pessimistic shrinkage toward zero. Our method constructs smaller Wasserstein ambiguity sets by controlling the transportation along directions informed by the source knowledge. This strategy can alleviate perturbations on the predictive projection of the covariates and protect against information loss. Theoretically, we establish the equivalence between our WDRO formulation and the knowledge-guided shrinkage estimation based on collinear similarity, ensuring tractability and geometrizing the feasible set. This also reveals a novel and general interpretation for recent shrinkage-based transfer learning approaches from the perspective of distributional robustness. In addition, our framework can adjust for scaling differences in the regression models between the source and target and accommodates general types of regularization such as lasso and ridge. Extensive simulations demonstrate the superior performance and adaptivity of KG-WDRO in enhancing small-sample transfer learning.
GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement
Jun 17, 2024The evolution of speech technology has been spurred by the rapid increase in dataset sizes. Traditional speech models generally depend on a large amount of labeled training data, which is scarce for low-resource languages. This paper presents GigaSpeech 2, a large-scale, multi-domain, multilingual speech recognition corpus. It is designed for low-resource languages and does not rely on paired speech and text data. GigaSpeech 2 comprises about 30,000 hours of automatically transcribed speech, including Thai, Indonesian, and Vietnamese, gathered from unlabeled YouTube videos. We also introduce an automated pipeline for data crawling, transcription, and label refinement. Specifically, this pipeline uses Whisper for initial transcription and TorchAudio for forced alignment, combined with multi-dimensional filtering for data quality assurance. A modified Noisy Student Training is developed to further refine flawed pseudo labels iteratively, thus enhancing model performance. Experimental results on our manually transcribed evaluation set and two public test sets from Common Voice and FLEURS confirm our corpus's high quality and broad applicability. Notably, ASR models trained on GigaSpeech 2 can reduce the word error rate for Thai, Indonesian, and Vietnamese on our challenging and realistic YouTube test set by 25% to 40% compared to the Whisper large-v3 model, with merely 10% model parameters. Furthermore, our ASR models trained on Gigaspeech 2 yield superior performance compared to commercial services. We believe that our newly introduced corpus and pipeline will open a new avenue for low-resource speech recognition and significantly facilitate research in this area.
A Survey on Human-AI Teaming with Large Pre-Trained Models
Mar 07, 2024
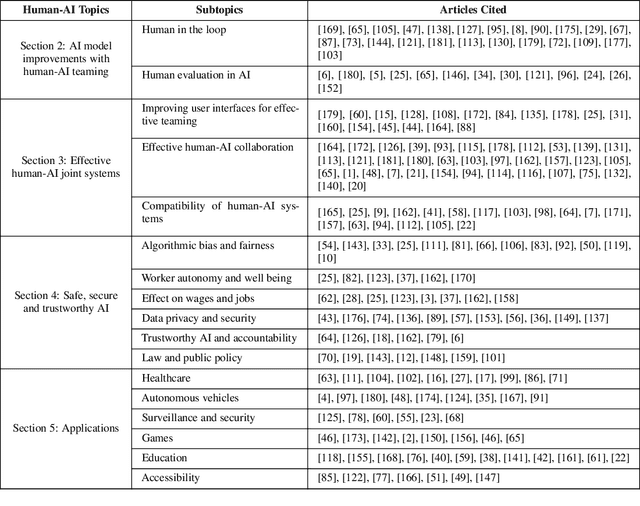
In the rapidly evolving landscape of artificial intelligence (AI), the collaboration between human intelligence and AI systems, known as Human-AI (HAI) Teaming, has emerged as a cornerstone for advancing problem-solving and decision-making processes. The advent of Large Pre-trained Models (LPtM) has significantly transformed this landscape, offering unprecedented capabilities by leveraging vast amounts of data to understand and predict complex patterns. This paper surveys the pivotal integration of LPtMs with HAI, emphasizing how these models enhance collaborative intelligence beyond traditional approaches. It examines the synergistic potential of LPtMs in augmenting human capabilities, discussing this collaboration for AI model improvements, effective teaming, ethical considerations, and their broad applied implications in various sectors. Through this exploration, the study sheds light on the transformative impact of LPtM-enhanced HAI Teaming, providing insights for future research, policy development, and strategic implementations aimed at harnessing the full potential of this collaboration for research and societal benefit.
How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection
Jan 18, 2023The introduction of ChatGPT has garnered widespread attention in both academic and industrial communities. ChatGPT is able to respond effectively to a wide range of human questions, providing fluent and comprehensive answers that significantly surpass previous public chatbots in terms of security and usefulness. On one hand, people are curious about how ChatGPT is able to achieve such strength and how far it is from human experts. On the other hand, people are starting to worry about the potential negative impacts that large language models (LLMs) like ChatGPT could have on society, such as fake news, plagiarism, and social security issues. In this work, we collected tens of thousands of comparison responses from both human experts and ChatGPT, with questions ranging from open-domain, financial, medical, legal, and psychological areas. We call the collected dataset the Human ChatGPT Comparison Corpus (HC3). Based on the HC3 dataset, we study the characteristics of ChatGPT's responses, the differences and gaps from human experts, and future directions for LLMs. We conducted comprehensive human evaluations and linguistic analyses of ChatGPT-generated content compared with that of humans, where many interesting results are revealed. After that, we conduct extensive experiments on how to effectively detect whether a certain text is generated by ChatGPT or humans. We build three different detection systems, explore several key factors that influence their effectiveness, and evaluate them in different scenarios. The dataset, code, and models are all publicly available at https://github.com/Hello-SimpleAI/chatgpt-comparison-detection.
IDEA: Interactive DoublE Attentions from Label Embedding for Text Classification
Sep 23, 2022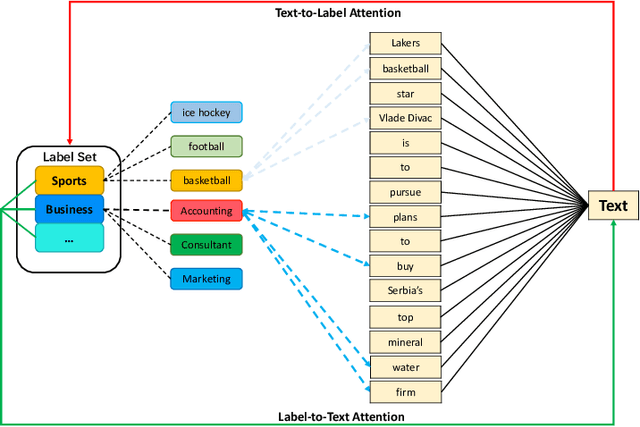
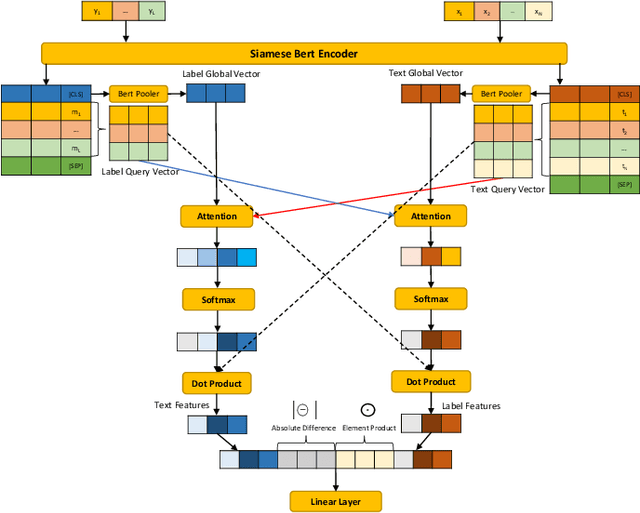
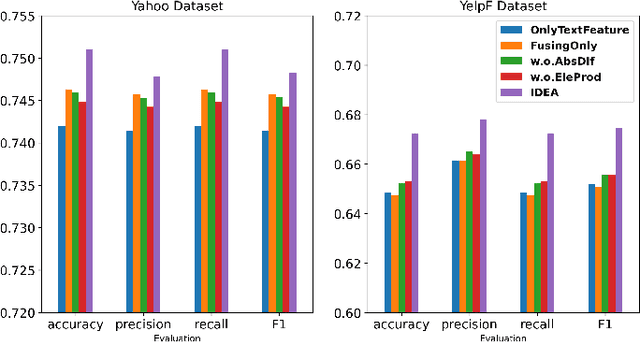
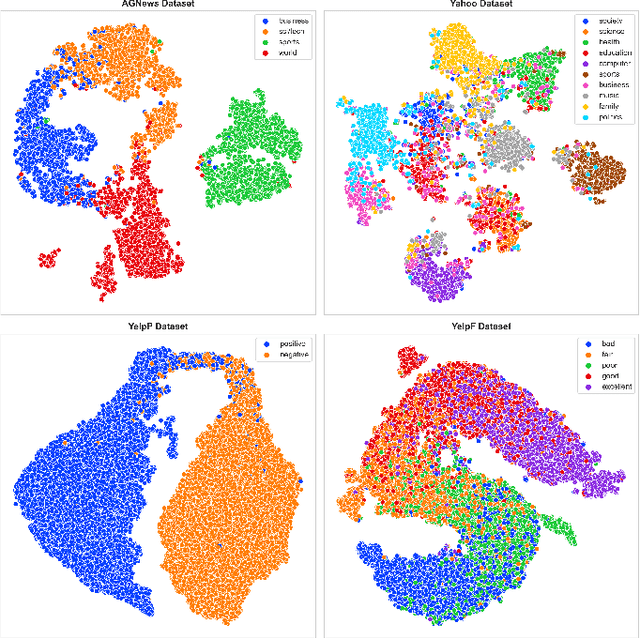
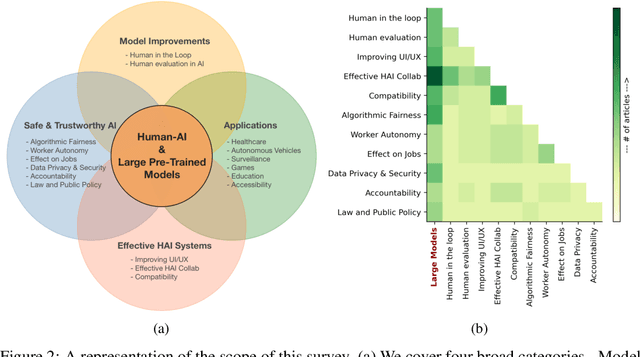
Current text classification methods typically encode the text merely into embedding before a naive or complicated classifier, which ignores the suggestive information contained in the label text. As a matter of fact, humans classify documents primarily based on the semantic meaning of the subcategories. We propose a novel model structure via siamese BERT and interactive double attentions named IDEA ( Interactive DoublE Attentions) to capture the information exchange of text and label names. Interactive double attentions enable the model to exploit the inter-class and intra-class information from coarse to fine, which involves distinguishing among all labels and matching the semantical subclasses of ground truth labels. Our proposed method outperforms the state-of-the-art methods using label texts significantly with more stable results.
SAS: A Simple, Accurate and Scalable Node Classification Algorithm
Apr 19, 2021
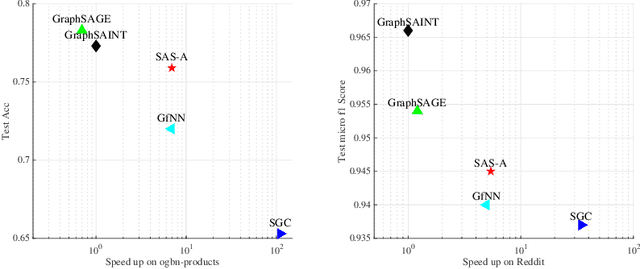
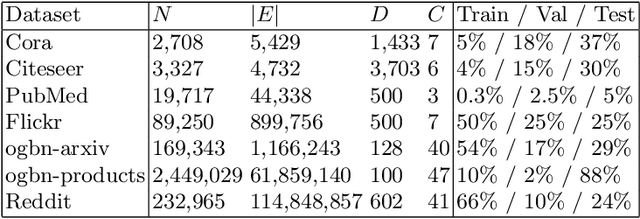
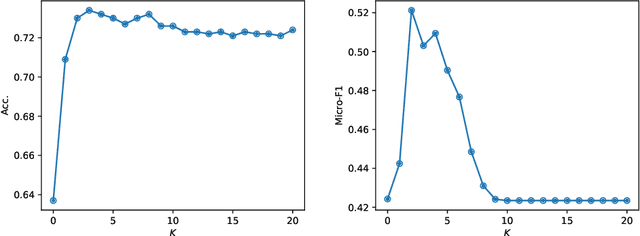
Graph neural networks have achieved state-of-the-art accuracy for graph node classification. However, GNNs are difficult to scale to large graphs, for example frequently encountering out-of-memory errors on even moderate size graphs. Recent works have sought to address this problem using a two-stage approach, which first aggregates data along graph edges, then trains a classifier without using additional graph information. These methods can run on much larger graphs and are orders of magnitude faster than GNNs, but achieve lower classification accuracy. We propose a novel two-stage algorithm based on a simple but effective observation: we should first train a classifier then aggregate, rather than the other way around. We show our algorithm is faster and can handle larger graphs than existing two-stage algorithms, while achieving comparable or higher accuracy than popular GNNs. We also present a theoretical basis to explain our algorithm's improved accuracy, by giving a synthetic nonlinear dataset in which performing aggregation before classification actually decreases accuracy compared to doing classification alone, while our classify then aggregate approach substantially improves accuracy compared to classification alone.
Decentralized Statistical Inference with Unrolled Graph Neural Networks
Apr 04, 2021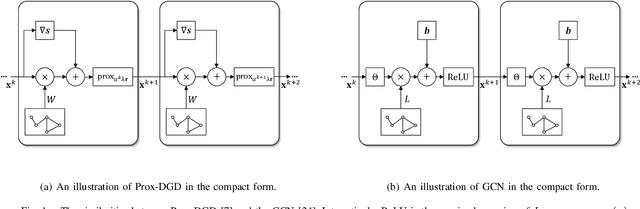

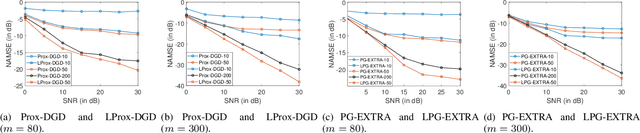
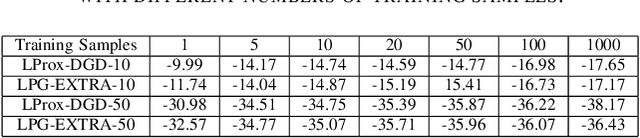
In this paper, we investigate the decentralized statistical inference problem, where a network of agents cooperatively recover a (structured) vector from private noisy samples without centralized coordination. Existing optimization-based algorithms suffer from issues of model mismatch and poor convergence speed, and thus their performance would be degraded, provided that the number of communication rounds is limited. This motivates us to propose a learning-based framework, which unrolls well-noted decentralized optimization algorithms (e.g., Prox-DGD and PG-EXTRA) into graph neural networks (GNNs). By minimizing the recovery error via end-to-end training, this learning-based framework resolves the model mismatch issue. Our convergence analysis (with PG-EXTRA as the base algorithm) reveals that the learned model parameters may accelerate the convergence and reduce the recovery error to a large extent. The simulation results demonstrate that the proposed GNN-based learning methods prominently outperform several state-of-the-art optimization-based algorithms in convergence speed and recovery error.
Automatic Data Augmentation via Deep Reinforcement Learning for Effective Kidney Tumor Segmentation
Feb 22, 2020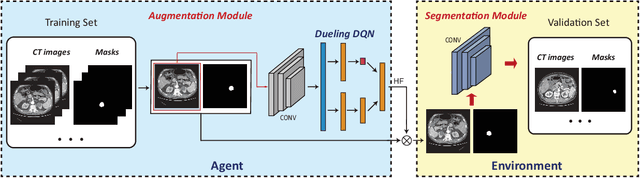
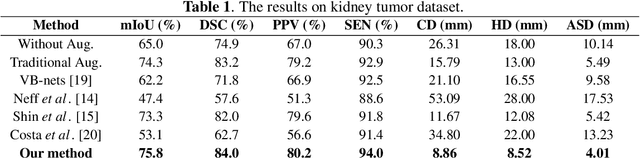
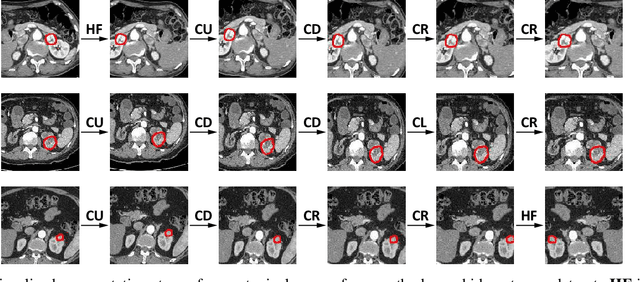
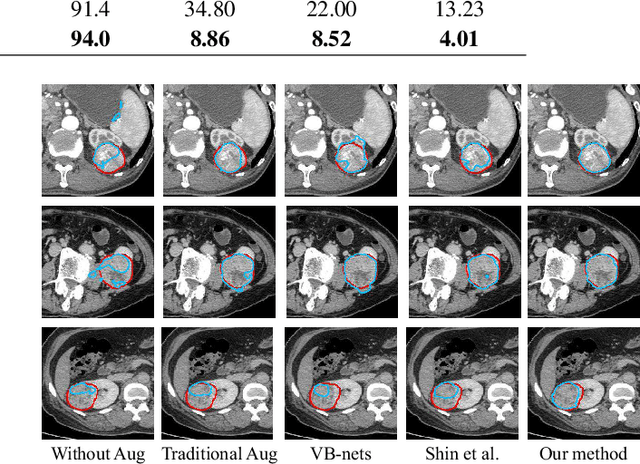
Conventional data augmentation realized by performing simple pre-processing operations (\eg, rotation, crop, \etc) has been validated for its advantage in enhancing the performance for medical image segmentation. However, the data generated by these conventional augmentation methods are random and sometimes harmful to the subsequent segmentation. In this paper, we developed a novel automatic learning-based data augmentation method for medical image segmentation which models the augmentation task as a trial-and-error procedure using deep reinforcement learning (DRL). In our method, we innovatively combine the data augmentation module and the subsequent segmentation module in an end-to-end training manner with a consistent loss. Specifically, the best sequential combination of different basic operations is automatically learned by directly maximizing the performance improvement (\ie, Dice ratio) on the available validation set. We extensively evaluated our method on CT kidney tumor segmentation which validated the promising results of our method.