 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Adaptation for Foundation Medical Segmentation Model without Parametric Updates
Apr 02, 2025Foundation medical segmentation models, with MedSAM being the most popular, have achieved promising performance across organs and lesions. However, MedSAM still suffers from compromised performance on specific lesions with intricate structures and appearance, as well as bounding box prompt-induced perturbations. Although current test-time adaptation (TTA) methods for medical image segmentation may tackle this issue, partial (e.g., batch normalization) or whole parametric updates restrict their effectiveness due to limited update signals or catastrophic forgetting in large models. Meanwhile, these approaches ignore the computational complexity during adaptation, which is particularly significant for modern foundation models. To this end, our theoretical analyses reveal that directly refining image embeddings is feasible to approach the same goal as parametric updates under the MedSAM architecture, which enables us to realize high computational efficiency and segmentation performance without the risk of catastrophic forgetting. Under this framework, we propose to encourage maximizing factorized conditional probabilities of the posterior prediction probability using a proposed distribution-approximated latent conditional random field loss combined with an entropy minimization loss. Experiments show that we achieve about 3\% Dice score improvements across three datasets while reducing computational complexity by over 7 times.
Enhancing Zero-Shot Image Recognition in Vision-Language Models through Human-like Concept Guidance
Mar 21, 2025
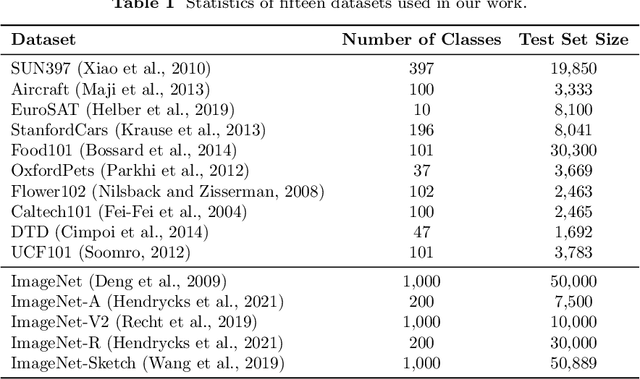


In zero-shot image recognition tasks, humans demonstrate remarkable flexibility in classifying unseen categories by composing known simpler concepts. However, existing vision-language models (VLMs), despite achieving significant progress through large-scale natural language supervision, often underperform in real-world applications because of sub-optimal prompt engineering and the inability to adapt effectively to target classes. To address these issues, we propose a Concept-guided Human-like Bayesian Reasoning (CHBR) framework. Grounded in Bayes' theorem, CHBR models the concept used in human image recognition as latent variables and formulates this task by summing across potential concepts, weighted by a prior distribution and a likelihood function. To tackle the intractable computation over an infinite concept space, we introduce an importance sampling algorithm that iteratively prompts large language models (LLMs) to generate discriminative concepts, emphasizing inter-class differences. We further propose three heuristic approaches involving Average Likelihood, Confidence Likelihood, and Test Time Augmentation (TTA) Likelihood, which dynamically refine the combination of concepts based on the test image. Extensive evaluations across fifteen datasets demonstrate that CHBR consistently outperforms existing state-of-the-art zero-shot generalization methods.
Q-PART: Quasi-Periodic Adaptive Regression with Test-time Training for Pediatric Left Ventricular Ejection Fraction Regression
Mar 06, 2025
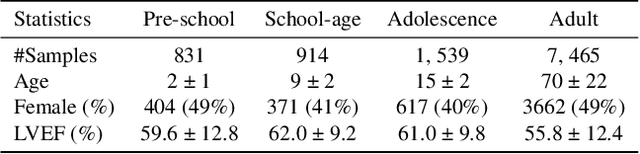
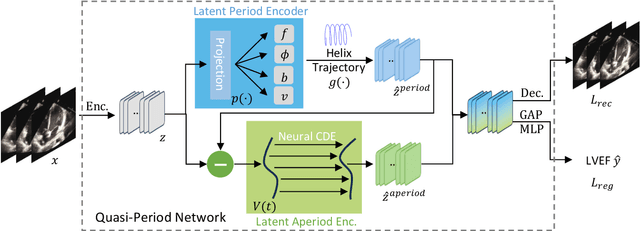
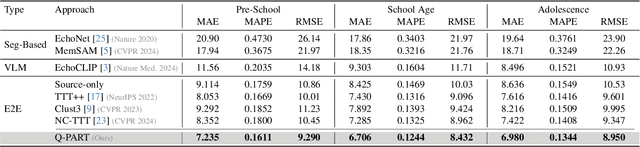
In this work, we address the challenge of adaptive pediatric Left Ventricular Ejection Fraction (LVEF) assessment. While Test-time Training (TTT) approaches show promise for this task, they suffer from two significant limitations. Existing TTT works are primarily designed for classification tasks rather than continuous value regression, and they lack mechanisms to handle the quasi-periodic nature of cardiac signals. To tackle these issues, we propose a novel \textbf{Q}uasi-\textbf{P}eriodic \textbf{A}daptive \textbf{R}egression with \textbf{T}est-time Training (Q-PART) framework. In the training stage, the proposed Quasi-Period Network decomposes the echocardiogram into periodic and aperiodic components within latent space by combining parameterized helix trajectories with Neural Controlled Differential Equations. During inference, our framework further employs a variance minimization strategy across image augmentations that simulate common quality issues in echocardiogram acquisition, along with differential adaptation rates for periodic and aperiodic components. Theoretical analysis is provided to demonstrate that our variance minimization objective effectively bounds the regression error under mild conditions. Furthermore, extensive experiments across three pediatric age groups demonstrate that Q-PART not only significantly outperforms existing approaches in pediatric LVEF prediction, but also exhibits strong clinical screening capability with high mAUROC scores (up to 0.9747) and maintains gender-fair performance across all metrics, validating its robustness and practical utility in pediatric echocardiography analysis.
Test-time adaptation for image compression with distribution regularization
Oct 16, 2024



Current test- or compression-time adaptation image compression (TTA-IC) approaches, which leverage both latent and decoder refinements as a two-step adaptation scheme, have potentially enhanced the rate-distortion (R-D) performance of learned image compression models on cross-domain compression tasks, \textit{e.g.,} from natural to screen content images. However, compared with the emergence of various decoder refinement variants, the latent refinement, as an inseparable ingredient, is barely tailored to cross-domain scenarios. To this end, we aim to develop an advanced latent refinement method by extending the effective hybrid latent refinement (HLR) method, which is designed for \textit{in-domain} inference improvement but shows noticeable degradation of the rate cost in \textit{cross-domain} tasks. Specifically, we first provide theoretical analyses, in a cue of marginalization approximation from in- to cross-domain scenarios, to uncover that the vanilla HLR suffers from an underlying mismatch between refined Gaussian conditional and hyperprior distributions, leading to deteriorated joint probability approximation of marginal distribution with increased rate consumption. To remedy this issue, we introduce a simple Bayesian approximation-endowed \textit{distribution regularization} to encourage learning a better joint probability approximation in a plug-and-play manner. Extensive experiments on six in- and cross-domain datasets demonstrate that our proposed method not only improves the R-D performance compared with other latent refinement counterparts, but also can be flexibly integrated into existing TTA-IC methods with incremental benefits.
Deep Signature: Characterization of Large-Scale Molecular Dynamics
Oct 03, 2024Understanding protein dynamics are essential for deciphering protein functional mechanisms and developing molecular therapies. However, the complex high-dimensional dynamics and interatomic interactions of biological processes pose significant challenge for existing computational techniques. In this paper, we approach this problem for the first time by introducing Deep Signature, a novel computationally tractable framework that characterizes complex dynamics and interatomic interactions based on their evolving trajectories. Specifically, our approach incorporates soft spectral clustering that locally aggregates cooperative dynamics to reduce the size of the system, as well as signature transform that collects iterated integrals to provide a global characterization of the non-smooth interactive dynamics. Theoretical analysis demonstrates that Deep Signature exhibits several desirable properties, including invariance to translation, near invariance to rotation, equivariance to permutation of atomic coordinates, and invariance under time reparameterization. Furthermore, experimental results on three benchmarks of biological processes verify that our approach can achieve superior performance compared to baseline methods.
Log Neural Controlled Differential Equations: The Lie Brackets Make a Difference
Feb 28, 2024The vector field of a controlled differential equation (CDE) describes the relationship between a control path and the evolution of a solution path. Neural CDEs (NCDEs) treat time series data as observations from a control path, parameterise a CDE's vector field using a neural network, and use the solution path as a continuously evolving hidden state. As their formulation makes them robust to irregular sampling rates, NCDEs are a powerful approach for modelling real-world data. Building on neural rough differential equations (NRDEs), we introduce Log-NCDEs, a novel and effective method for training NCDEs. The core component of Log-NCDEs is the Log-ODE method, a tool from the study of rough paths for approximating a CDE's solution. On a range of multivariate time series classification benchmarks, Log-NCDEs are shown to achieve a higher average test set accuracy than NCDEs, NRDEs, and two state-of-the-art models, S5 and the linear recurrent unit.
Learning Dynamic Graph Embeddings with Neural Controlled Differential Equations
Feb 22, 2023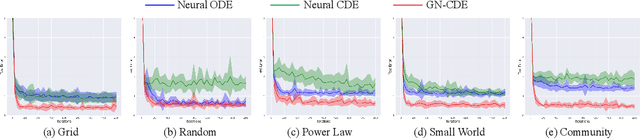

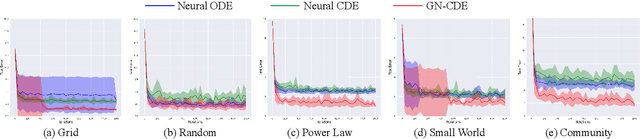

This paper focuses on representation learning for dynamic graphs with temporal interactions. A fundamental issue is that both the graph structure and the nodes own their own dynamics, and their blending induces intractable complexity in the temporal evolution over graphs. Drawing inspiration from the recent process of physical dynamic models in deep neural networks, we propose Graph Neural Controlled Differential Equation (GN-CDE) model, a generic differential model for dynamic graphs that characterise the continuously dynamic evolution of node embedding trajectories with a neural network parameterised vector field and the derivatives of interactions w.r.t. time. Our framework exhibits several desirable characteristics, including the ability to express dynamics on evolving graphs without integration by segments, the capability to calibrate trajectories with subsequent data, and robustness to missing observations. Empirical evaluation on a range of dynamic graph representation learning tasks demonstrates the superiority of our proposed approach compared to the baselines.
Generalizing to Evolving Domains with Latent Structure-Aware Sequential Autoencoder
May 16, 2022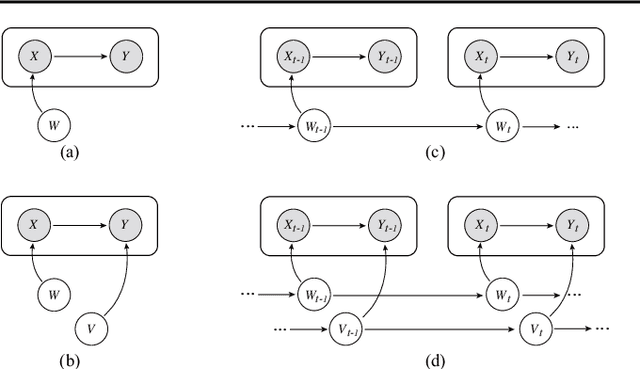
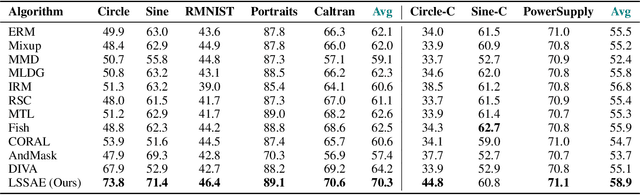
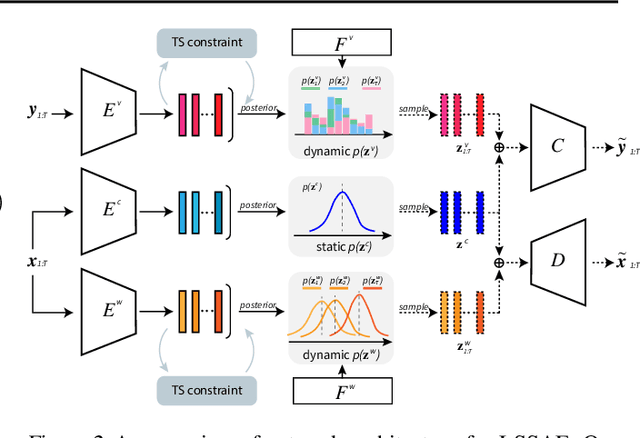
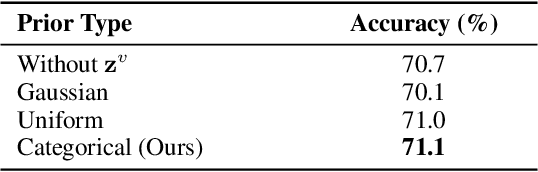
Domain generalization aims to improve the generalization capability of machine learning systems to out-of-distribution (OOD) data. Existing domain generalization techniques embark upon stationary and discrete environments to tackle the generalization issue caused by OOD data. However, many real-world tasks in non-stationary environments (e.g. self-driven car system, sensor measures) involve more complex and continuously evolving domain drift, which raises new challenges for the problem of domain generalization. In this paper, we formulate the aforementioned setting as the problem of evolving domain generalization. Specifically, we propose to introduce a probabilistic framework called Latent Structure-aware Sequential Autoencoder (LSSAE) to tackle the problem of evolving domain generalization via exploring the underlying continuous structure in the latent space of deep neural networks, where we aim to identify two major factors namely covariate shift and concept shift accounting for distribution shift in non-stationary environments. Experimental results on both synthetic and real-world datasets show that LSSAE can lead to superior performances based on the evolving domain generalization setting.
LibFewShot: A Comprehensive Library for Few-shot Learning
Sep 10, 2021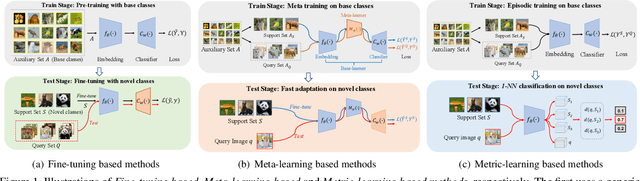
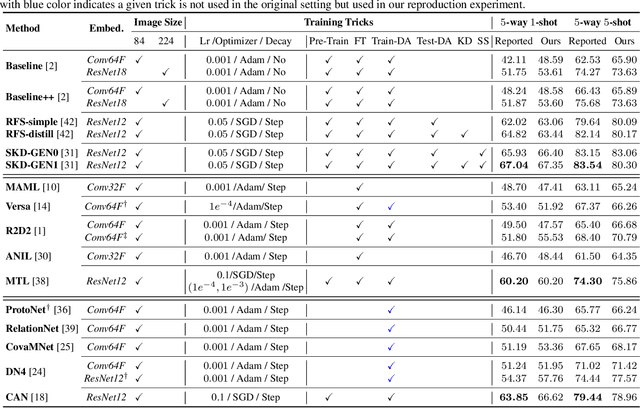
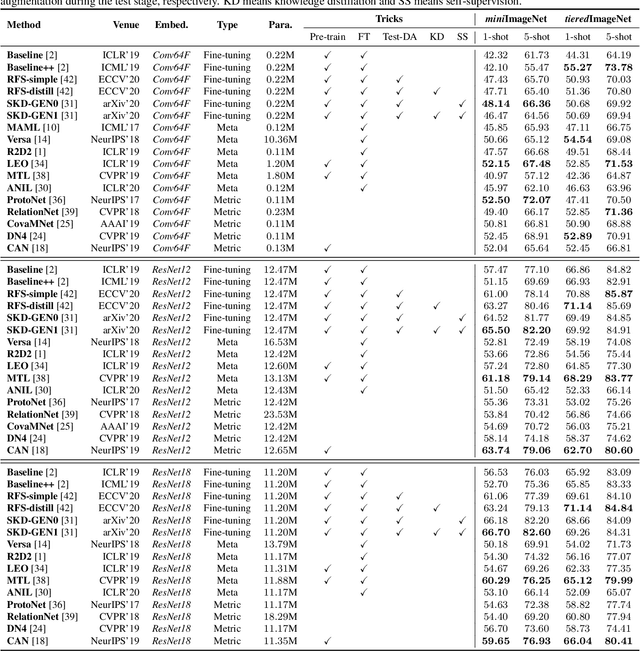
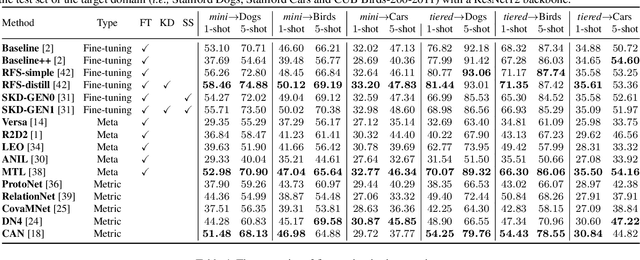
Few-shot learning, especially few-shot image classification, has received increasing attention and witnessed significant advances in recent years. Some recent studies implicitly show that many generic techniques or ``tricks'', such as data augmentation, pre-training, knowledge distillation, and self-supervision, may greatly boost the performance of a few-shot learning method. Moreover, different works may employ different software platforms, different training schedules, different backbone architectures and even different input image sizes, making fair comparisons difficult and practitioners struggle with reproducibility. To address these situations, we propose a comprehensive library for few-shot learning (LibFewShot) by re-implementing seventeen state-of-the-art few-shot learning methods in a unified framework with the same single codebase in PyTorch. Furthermore, based on LibFewShot, we provide comprehensive evaluations on multiple benchmark datasets with multiple backbone architectures to evaluate common pitfalls and effects of different training tricks. In addition, given the recent doubts on the necessity of meta- or episodic-training mechanism, our evaluation results show that such kind of mechanism is still necessary especially when combined with pre-training. We hope our work can not only lower the barriers for beginners to work on few-shot learning but also remove the effects of the nontrivial tricks to facilitate intrinsic research on few-shot learning. The source code is available from https://github.com/RL-VIG/LibFewShot.
Unsupervised Few-shot Learning via Distribution Shift-based Augmentation
Apr 13, 2020



Few-shot learning aims to learn a new concept when only a few training examples are available, which has been extensively explored in recent years. However, most of the current works heavily rely on a large-scale labeled auxiliary set to train their models in an episodic-training paradigm. Such a kind of supervised setting basically limits the widespread use of few-shot learning algorithms, especially in real-world applications. Instead, in this paper, we develop a novel framework called \emph{Unsupervised Few-shot Learning via Distribution Shift-based Data Augmentation} (ULDA), which pays attention to the distribution diversity inside each constructed pretext few-shot task when using data augmentation. Importantly, we highlight the value and importance of the distribution diversity in the augmentation-based pretext few-shot tasks. In ULDA, we systemically investigate the effects of different augmentation techniques and propose to strengthen the distribution diversity (or difference) between the query set and support set in each few-shot task, by augmenting these two sets separately (i.e. shifting). In this way, even incorporated with simple augmentation techniques (e.g. random crop, color jittering, or rotation), our ULDA can produce a significant improvement. In the experiments, few-shot models learned by ULDA can achieve superior generalization performance and obtain state-of-the-art results in a variety of established few-shot learning tasks on \emph{mini}ImageNet and \emph{tiered}ImageNet. %The code will be released soon. The source code is available in \textcolor{blue}{\emph{https://github.com/WonderSeven/ULDA}}.