 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Medical Image Restoration via Reliability Guided Learning in Frequency Domain
Apr 15, 2025



Medical image restoration tasks aim to recover high-quality images from degraded observations, exhibiting emergent desires in many clinical scenarios, such as low-dose CT image denoising, MRI super-resolution, and MRI artifact removal. Despite the success achieved by existing deep learning-based restoration methods with sophisticated modules, they struggle with rendering computationally-efficient reconstruction results. Moreover, they usually ignore the reliability of the restoration results, which is much more urgent in medical systems. To alleviate these issues, we present LRformer, a Lightweight Transformer-based method via Reliability-guided learning in the frequency domain. Specifically, inspired by the uncertainty quantification in Bayesian neural networks (BNNs), we develop a Reliable Lesion-Semantic Prior Producer (RLPP). RLPP leverages Monte Carlo (MC) estimators with stochastic sampling operations to generate sufficiently-reliable priors by performing multiple inferences on the foundational medical image segmentation model, MedSAM. Additionally, instead of directly incorporating the priors in the spatial domain, we decompose the cross-attention (CA) mechanism into real symmetric and imaginary anti-symmetric parts via fast Fourier transform (FFT), resulting in the design of the Guided Frequency Cross-Attention (GFCA) solver. By leveraging the conjugated symmetric property of FFT, GFCA reduces the computational complexity of naive CA by nearly half. Extensive experimental results in various tasks demonstrate the superiority of the proposed LRformer in both effectiveness and efficiency.
Disentangling Instruction Influence in Diffusion Transformers for Parallel Multi-Instruction-Guided Image Editing
Apr 07, 2025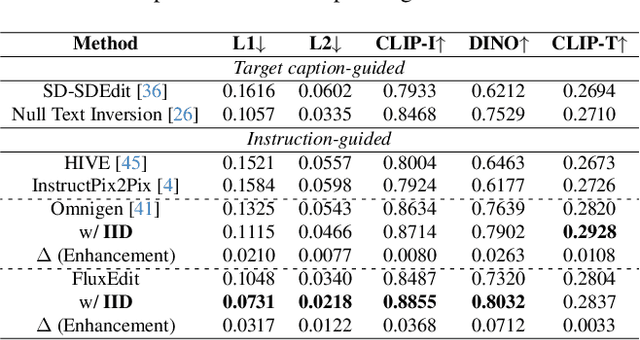
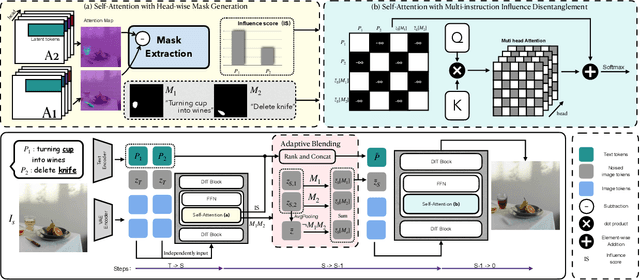
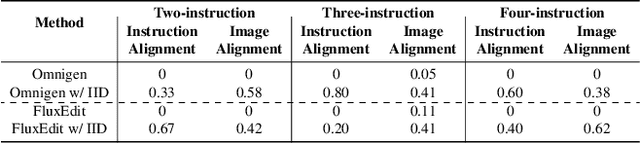

Instruction-guided image editing enables users to specify modifications using natural language, offering more flexibility and control. Among existing frameworks, Diffusion Transformers (DiTs) outperform U-Net-based diffusion models in scalability and performance. However, while real-world scenarios often require concurrent execution of multiple instructions, step-by-step editing suffers from accumulated errors and degraded quality, and integrating multiple instructions with a single prompt usually results in incomplete edits due to instruction conflicts. We propose Instruction Influence Disentanglement (IID), a novel framework enabling parallel execution of multiple instructions in a single denoising process, designed for DiT-based models. By analyzing self-attention mechanisms in DiTs, we identify distinctive attention patterns in multi-instruction settings and derive instruction-specific attention masks to disentangle each instruction's influence. These masks guide the editing process to ensure localized modifications while preserving consistency in non-edited regions. Extensive experiments on open-source and custom datasets demonstrate that IID reduces diffusion steps while improving fidelity and instruction completion compared to existing baselines. The codes will be publicly released upon the acceptance of the paper.
SPACE: SPike-Aware Consistency Enhancement for Test-Time Adaptation in Spiking Neural Networks
Apr 03, 2025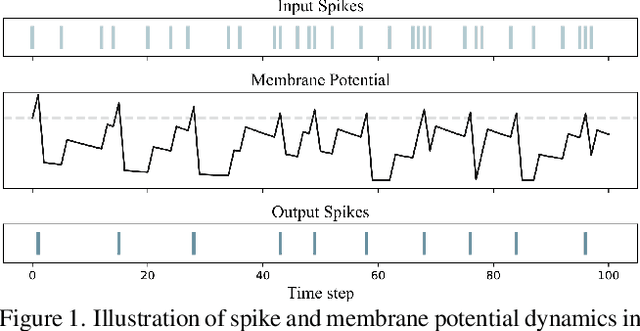

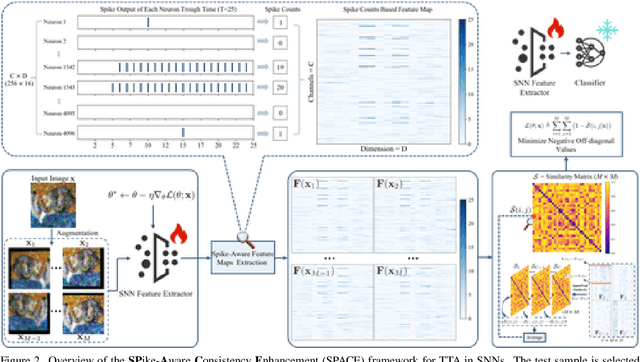

Spiking Neural Networks (SNNs), as a biologically plausible alternative to Artificial Neural Networks (ANNs), have demonstrated advantages in terms of energy efficiency, temporal processing, and biological plausibility. However, SNNs are highly sensitive to distribution shifts, which can significantly degrade their performance in real-world scenarios. Traditional test-time adaptation (TTA) methods designed for ANNs often fail to address the unique computational dynamics of SNNs, such as sparsity and temporal spiking behavior. To address these challenges, we propose $\textbf{SP}$ike-$\textbf{A}$ware $\textbf{C}$onsistency $\textbf{E}$nhancement (SPACE), the first source-free and single-instance TTA method specifically designed for SNNs. SPACE leverages the inherent spike dynamics of SNNs to maximize the consistency of spike-behavior-based local feature maps across augmented versions of a single test sample, enabling robust adaptation without requiring source data. We evaluate SPACE on multiple datasets, including CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and DVS Gesture-C. Furthermore, SPACE demonstrates strong generalization across different model architectures, achieving consistent performance improvements on both VGG9 and ResNet11. Experimental results show that SPACE outperforms state-of-the-art methods, highlighting its effectiveness and robustness in real-world settings.
Test-time Adaptation for Foundation Medical Segmentation Model without Parametric Updates
Apr 02, 2025Foundation medical segmentation models, with MedSAM being the most popular, have achieved promising performance across organs and lesions. However, MedSAM still suffers from compromised performance on specific lesions with intricate structures and appearance, as well as bounding box prompt-induced perturbations. Although current test-time adaptation (TTA) methods for medical image segmentation may tackle this issue, partial (e.g., batch normalization) or whole parametric updates restrict their effectiveness due to limited update signals or catastrophic forgetting in large models. Meanwhile, these approaches ignore the computational complexity during adaptation, which is particularly significant for modern foundation models. To this end, our theoretical analyses reveal that directly refining image embeddings is feasible to approach the same goal as parametric updates under the MedSAM architecture, which enables us to realize high computational efficiency and segmentation performance without the risk of catastrophic forgetting. Under this framework, we propose to encourage maximizing factorized conditional probabilities of the posterior prediction probability using a proposed distribution-approximated latent conditional random field loss combined with an entropy minimization loss. Experiments show that we achieve about 3\% Dice score improvements across three datasets while reducing computational complexity by over 7 times.
Enhancing Zero-Shot Image Recognition in Vision-Language Models through Human-like Concept Guidance
Mar 21, 2025In zero-shot image recognition tasks, humans demonstrate remarkable flexibility in classifying unseen categories by composing known simpler concepts. However, existing vision-language models (VLMs), despite achieving significant progress through large-scale natural language supervision, often underperform in real-world applications because of sub-optimal prompt engineering and the inability to adapt effectively to target classes. To address these issues, we propose a Concept-guided Human-like Bayesian Reasoning (CHBR) framework. Grounded in Bayes' theorem, CHBR models the concept used in human image recognition as latent variables and formulates this task by summing across potential concepts, weighted by a prior distribution and a likelihood function. To tackle the intractable computation over an infinite concept space, we introduce an importance sampling algorithm that iteratively prompts large language models (LLMs) to generate discriminative concepts, emphasizing inter-class differences. We further propose three heuristic approaches involving Average Likelihood, Confidence Likelihood, and Test Time Augmentation (TTA) Likelihood, which dynamically refine the combination of concepts based on the test image. Extensive evaluations across fifteen datasets demonstrate that CHBR consistently outperforms existing state-of-the-art zero-shot generalization methods.
Large Language Models for Lossless Image Compression: Next-Pixel Prediction in Language Space is All You Need
Nov 19, 2024We have recently witnessed that ``Intelligence" and `` Compression" are the two sides of the same coin, where the language large model (LLM) with unprecedented intelligence is a general-purpose lossless compressor for various data modalities. This attribute particularly appeals to the lossless image compression community, given the increasing need to compress high-resolution images in the current streaming media era. Consequently, a spontaneous envision emerges: Can the compression performance of the LLM elevate lossless image compression to new heights? However, our findings indicate that the naive application of LLM-based lossless image compressors suffers from a considerable performance gap compared with existing state-of-the-art (SOTA) codecs on common benchmark datasets. In light of this, we are dedicated to fulfilling the unprecedented intelligence (compression) capacity of the LLM for lossless image compression tasks, thereby bridging the gap between theoretical and practical compression performance. Specifically, we propose P$^{2}$-LLM, a next-pixel prediction-based LLM, which integrates various elaborated insights and methodologies, \textit{e.g.,} pixel-level priors, the in-context ability of LLM, and a pixel-level semantic preservation strategy, to enhance the understanding capacity of pixel sequences for better next-pixel predictions. Extensive experiments on benchmark datasets demonstrate that P$^{2}$-LLM can beat SOTA classical and learned codecs.
Test-time adaptation for image compression with distribution regularization
Oct 16, 2024



Current test- or compression-time adaptation image compression (TTA-IC) approaches, which leverage both latent and decoder refinements as a two-step adaptation scheme, have potentially enhanced the rate-distortion (R-D) performance of learned image compression models on cross-domain compression tasks, \textit{e.g.,} from natural to screen content images. However, compared with the emergence of various decoder refinement variants, the latent refinement, as an inseparable ingredient, is barely tailored to cross-domain scenarios. To this end, we aim to develop an advanced latent refinement method by extending the effective hybrid latent refinement (HLR) method, which is designed for \textit{in-domain} inference improvement but shows noticeable degradation of the rate cost in \textit{cross-domain} tasks. Specifically, we first provide theoretical analyses, in a cue of marginalization approximation from in- to cross-domain scenarios, to uncover that the vanilla HLR suffers from an underlying mismatch between refined Gaussian conditional and hyperprior distributions, leading to deteriorated joint probability approximation of marginal distribution with increased rate consumption. To remedy this issue, we introduce a simple Bayesian approximation-endowed \textit{distribution regularization} to encourage learning a better joint probability approximation in a plug-and-play manner. Extensive experiments on six in- and cross-domain datasets demonstrate that our proposed method not only improves the R-D performance compared with other latent refinement counterparts, but also can be flexibly integrated into existing TTA-IC methods with incremental benefits.
Domain Generalization with Small Data
Feb 09, 2024



In this work, we propose to tackle the problem of domain generalization in the context of \textit{insufficient samples}. Instead of extracting latent feature embeddings based on deterministic models, we propose to learn a domain-invariant representation based on the probabilistic framework by mapping each data point into probabilistic embeddings. Specifically, we first extend empirical maximum mean discrepancy (MMD) to a novel probabilistic MMD that can measure the discrepancy between mixture distributions (i.e., source domains) consisting of a series of latent distributions rather than latent points. Moreover, instead of imposing the contrastive semantic alignment (CSA) loss based on pairs of latent points, a novel probabilistic CSA loss encourages positive probabilistic embedding pairs to be closer while pulling other negative ones apart. Benefiting from the learned representation captured by probabilistic models, our proposed method can marriage the measurement on the \textit{distribution over distributions} (i.e., the global perspective alignment) and the distribution-based contrastive semantic alignment (i.e., the local perspective alignment). Extensive experimental results on three challenging medical datasets show the effectiveness of our proposed method in the context of insufficient data compared with state-of-the-art methods.
AutoAssign+: Automatic Shared Embedding Assignment in Streaming Recommendation
Aug 14, 2023In the domain of streaming recommender systems, conventional methods for addressing new user IDs or item IDs typically involve assigning initial ID embeddings randomly. However, this practice results in two practical challenges: (i) Items or users with limited interactive data may yield suboptimal prediction performance. (ii) Embedding new IDs or low-frequency IDs necessitates consistently expanding the embedding table, leading to unnecessary memory consumption. In light of these concerns, we introduce a reinforcement learning-driven framework, namely AutoAssign+, that facilitates Automatic Shared Embedding Assignment Plus. To be specific, AutoAssign+ utilizes an Identity Agent as an actor network, which plays a dual role: (i) Representing low-frequency IDs field-wise with a small set of shared embeddings to enhance the embedding initialization, and (ii) Dynamically determining which ID features should be retained or eliminated in the embedding table. The policy of the agent is optimized with the guidance of a critic network. To evaluate the effectiveness of our approach, we perform extensive experiments on three commonly used benchmark datasets. Our experiment results demonstrate that AutoAssign+ is capable of significantly enhancing recommendation performance by mitigating the cold-start problem. Furthermore, our framework yields a reduction in memory usage of approximately 20-30%, verifying its practical effectiveness and efficiency for streaming recommender systems.
Robust Cross-domain CT Image Reconstruction via Bayesian Noise Uncertainty Alignment
Feb 26, 2023



In this work, we tackle the problem of robust computed tomography (CT) reconstruction issue under a cross-domain scenario, i.e., the training CT data as the source domain and the testing CT data as the target domain are collected from different anatomical regions. Due to the mismatches of the scan region and corresponding scan protocols, there is usually a difference of noise distributions between source and target domains (a.k.a. noise distribution shifts), resulting in a catastrophic deterioration of the reconstruction performance on target domain. To render a robust cross-domain CT reconstruction performance, instead of using deterministic models (e.g., convolutional neural network), a Bayesian-endowed probabilistic framework is introduced into robust cross-domain CT reconstruction task due to its impressive robustness. Under this probabilistic framework, we propose to alleviate the noise distribution shifts between source and target domains via implicit noise modeling schemes in the latent space and image space, respectively. Specifically, a novel Bayesian noise uncertainty alignment (BNUA) method is proposed to conduct implicit noise distribution modeling and alignment in the latent space. Moreover, an adversarial learning manner is imposed to reduce the discrepancy of noise distribution between two domains in the image space via a novel residual distribution alignment (RDA). Extensive experiments on the head and abdomen scans show that our proposed method can achieve a better performance of robust cross-domain CT reconstruction than existing approaches in terms of both quantitative and qualitative results.