 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Segment Anything Model with Visual Mamba for Diagnosing Placenta Accreta Spectrum
May 30, 2026Placenta Accreta Spectrum (PAS) is a rare but highly dangerous obstetric disease. Early and accurate PAS diagnosis is critical for maternal health. Traditional PAS diagnosis relies on experienced doctors by analyzing the cesarean history and Magnetic Resonance Imaging (MRI) data. However, district-level hospitals often lack the expertise and resources for accurate PAS diagnosis. To address these challenges, we establish the first MRI-based PAS dataset, which includes both fine-grained segmentation and classification annotations. Meanwhile, diagnosing PAS can be significantly enhanced by segmenting lesion areas from MRI images of the uterus. To achieve automatic PAS diagnosis, we propose 3DSAMba, a novel feature learning framework for effective lesion segmentation. More specifically, we first design a 3D Segment Anything Model (SAM) and incorporate medical domain information into the model through an efficient adapter mechanism. In addition, we introduce a Multi-Level Aggregation Mamba (MLAM) to aggregate feature maps across different levels and a Fusion State Space Model (FSSM) to fuse multi-scale features from both the encoder and decoder. Finally, we apply segmentation masks to the original MRI images through element-wise multiplication, effectively isolating lesion areas for more accurate PAS diagnosis. Extensive experiments validate that our framework significantly improves the PAS diagnostic performance. To facilitate further research in PAS diagnosis, we have released the dataset and source code at https://github.com/Drchip61/PASD.
HFP-SAM: Hierarchical Frequency Prompted SAM for Efficient Marine Animal Segmentation
Mar 13, 2026Marine Animal Segmentation (MAS) aims at identifying and segmenting marine animals from complex marine environments. Most of previous deep learning-based MAS methods struggle with the long-distance modeling issue. Recently, Segment Anything Model (SAM) has gained popularity in general image segmentation. However, it lacks of perceiving fine-grained details and frequency information. To this end, we propose a novel learning framework, named Hierarchical Frequency Prompted SAM (HFP-SAM) for high-performance MAS. First, we design a Frequency Guided Adapter (FGA) to efficiently inject marine scene information into the frozen SAM backbone through frequency domain prior masks. Additionally, we introduce a Frequency-aware Point Selection (FPS) to generate highlighted regions through frequency analysis. These regions are combined with the coarse predictions of SAM to generate point prompts and integrate into SAM's decoder for fine predictions. Finally, to obtain comprehensive segmentation masks, we introduce a Full-View Mamba (FVM) to efficiently extract spatial and channel contextual information with linear computational complexity. Extensive experiments on four public datasets demonstrate the superior performance of our approach. The source code is publicly available at https://github.com/Drchip61/TIP-HFP-SAM.
RAGTrack: Language-aware RGBT Tracking with Retrieval-Augmented Generation
Mar 04, 2026RGB-Thermal (RGBT) tracking aims to achieve robust object localization across diverse environmental conditions by fusing visible and thermal infrared modalities. However, existing RGBT trackers rely solely on initial-frame visual information for target modeling, failing to adapt to appearance variations due to the absence of language guidance. Furthermore, current methods suffer from redundant search regions and heterogeneous modality gaps, causing background distraction. To address these issues, we first introduce textual descriptions into RGBT tracking benchmarks. This is accomplished through a pipeline that leverages Multi-modal Large Language Models (MLLMs) to automatically produce texual annotations. Afterwards, we propose RAGTrack, a novel Retrieval-Augmented Generation framework for robust RGBT tracking. To this end, we introduce a Multi-modal Transformer Encoder (MTE) for unified visual-language modeling. Then, we design an Adaptive Token Fusion (ATF) to select target-relevant tokens and perform channel exchanges based on cross-modal correlations, mitigating search redundancies and modality gaps. Finally, we propose a Context-aware Reasoning Module (CRM) to maintain a dynamic knowledge base and employ a Retrieval-Augmented Generation (RAG) to enable temporal linguistic reasoning for robust target modeling. Extensive experiments on four RGBT benchmarks demonstrate that our framework achieves state-of-the-art performance across various challenging scenarios. The source code is available https://github.com/IdolLab/RAGTrack.
Interactive Spatial-Frequency Fusion Mamba for Multi-Modal Image Fusion
Feb 04, 2026Multi-Modal Image Fusion (MMIF) aims to combine images from different modalities to produce fused images, retaining texture details and preserving significant information. Recently, some MMIF methods incorporate frequency domain information to enhance spatial features. However, these methods typically rely on simple serial or parallel spatial-frequency fusion without interaction. In this paper, we propose a novel Interactive Spatial-Frequency Fusion Mamba (ISFM) framework for MMIF. Specifically, we begin with a Modality-Specific Extractor (MSE) to extract features from different modalities. It models long-range dependencies across the image with linear computational complexity. To effectively leverage frequency information, we then propose a Multi-scale Frequency Fusion (MFF). It adaptively integrates low-frequency and high-frequency components across multiple scales, enabling robust representations of frequency features. More importantly, we further propose an Interactive Spatial-Frequency Fusion (ISF). It incorporates frequency features to guide spatial features across modalities, enhancing complementary representations. Extensive experiments are conducted on six MMIF datasets. The experimental results demonstrate that our ISFM can achieve better performances than other state-of-the-art methods. The source code is available at https://github.com/Namn23/ISFM.
VReID-XFD: Video-based Person Re-identification at Extreme Far Distance Challenge Results
Jan 04, 2026Person re-identification (ReID) across aerial and ground views at extreme far distances introduces a distinct operating regime where severe resolution degradation, extreme viewpoint changes, unstable motion cues, and clothing variation jointly undermine the appearance-based assumptions of existing ReID systems. To study this regime, we introduce VReID-XFD, a video-based benchmark and community challenge for extreme far-distance (XFD) aerial-to-ground person re-identification. VReID-XFD is derived from the DetReIDX dataset and comprises 371 identities, 11,288 tracklets, and 11.75 million frames, captured across altitudes from 5.8 m to 120 m, viewing angles from oblique (30 degrees) to nadir (90 degrees), and horizontal distances up to 120 m. The benchmark supports aerial-to-aerial, aerial-to-ground, and ground-to-aerial evaluation under strict identity-disjoint splits, with rich physical metadata. The VReID-XFD-25 Challenge attracted 10 teams with hundreds of submissions. Systematic analysis reveals monotonic performance degradation with altitude and distance, a universal disadvantage of nadir views, and a trade-off between peak performance and robustness. Even the best-performing SAS-PReID method achieves only 43.93 percent mAP in the aerial-to-ground setting. The dataset, annotations, and official evaluation protocols are publicly available at https://www.it.ubi.pt/DetReIDX/ .
Parameter Aware Mamba Model for Multi-task Dense Prediction
Nov 18, 2025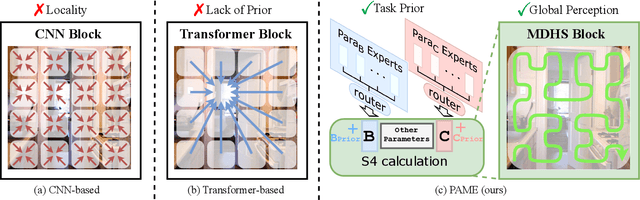
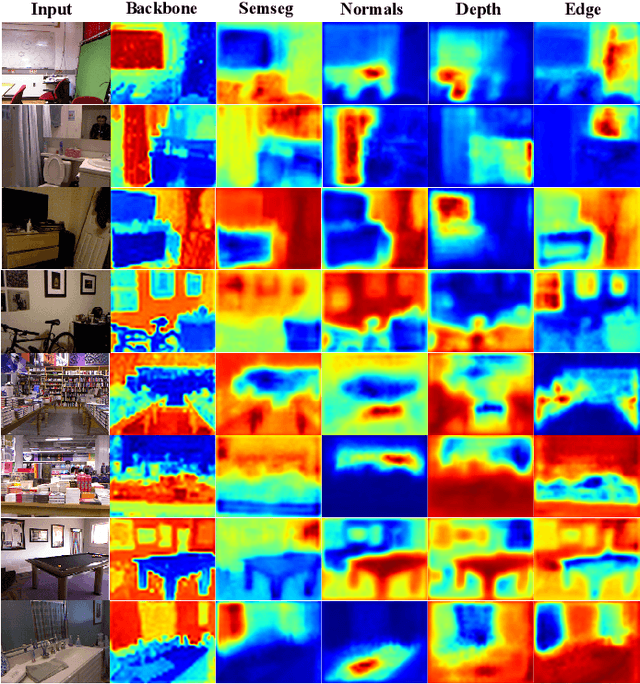
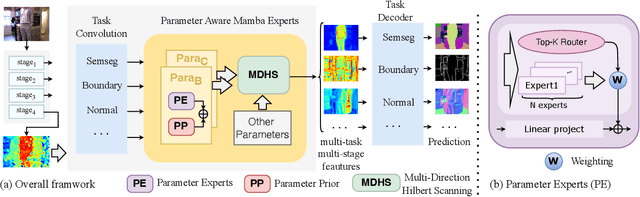
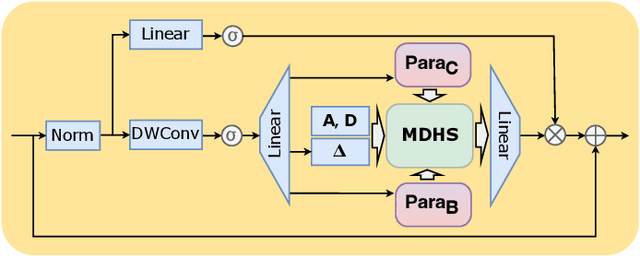
Understanding the inter-relations and interactions between tasks is crucial for multi-task dense prediction. Existing methods predominantly utilize convolutional layers and attention mechanisms to explore task-level interactions. In this work, we introduce a novel decoder-based framework, Parameter Aware Mamba Model (PAMM), specifically designed for dense prediction in multi-task learning setting. Distinct from approaches that employ Transformers to model holistic task relationships, PAMM leverages the rich, scalable parameters of state space models to enhance task interconnectivity. It features dual state space parameter experts that integrate and set task-specific parameter priors, capturing the intrinsic properties of each task. This approach not only facilitates precise multi-task interactions but also allows for the global integration of task priors through the structured state space sequence model (S4). Furthermore, we employ the Multi-Directional Hilbert Scanning method to construct multi-angle feature sequences, thereby enhancing the sequence model's perceptual capabilities for 2D data. Extensive experiments on the NYUD-v2 and PASCAL-Context benchmarks demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/CQC-gogopro/PAMM.
VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Nov 11, 2025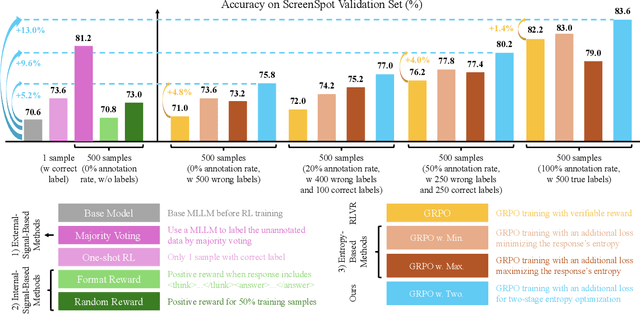



Reinforcement Learning with Verifiable Rewards (RLVR) for Multimodal Large Language Models (MLLMs) is highly dependent on high-quality labeled data, which is often scarce and prone to substantial annotation noise in real-world scenarios. Existing unsupervised RLVR methods, including pure entropy minimization, can overfit to incorrect labels and limit the crucial reward ranking signal for Group-Relative Policy Optimization (GRPO). To address these challenges and enhance noise tolerance, we propose a novel two-stage, token-level entropy optimization method for RLVR. This approach dynamically guides the model from exploration to exploitation during training. In the initial exploration phase, token-level entropy maximization promotes diverse and stochastic output generation, serving as a strong regularizer that prevents premature convergence to noisy labels and ensures sufficient intra-group variation, which enables more reliable reward gradient estimation in GRPO. As training progresses, the method transitions into the exploitation phase, where token-level entropy minimization encourages the model to produce confident and deterministic outputs, thereby consolidating acquired knowledge and refining prediction accuracy. Empirically, across three MLLM backbones - Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2.5-VL-3B - spanning diverse noise settings and multiple tasks, our phased strategy consistently outperforms prior approaches by unifying and enhancing external, internal, and entropy-based methods, delivering robust and superior performance across the board.
Spatial-Frequency Enhanced Mamba for Multi-Modal Image Fusion
Nov 10, 2025Multi-Modal Image Fusion (MMIF) aims to integrate complementary image information from different modalities to produce informative images. Previous deep learning-based MMIF methods generally adopt Convolutional Neural Networks (CNNs) or Transformers for feature extraction. However, these methods deliver unsatisfactory performances due to the limited receptive field of CNNs and the high computational cost of Transformers. Recently, Mamba has demonstrated a powerful potential for modeling long-range dependencies with linear complexity, providing a promising solution to MMIF. Unfortunately, Mamba lacks full spatial and frequency perceptions, which are very important for MMIF. Moreover, employing Image Reconstruction (IR) as an auxiliary task has been proven beneficial for MMIF. However, a primary challenge is how to leverage IR efficiently and effectively. To address the above issues, we propose a novel framework named Spatial-Frequency Enhanced Mamba Fusion (SFMFusion) for MMIF. More specifically, we first propose a three-branch structure to couple MMIF and IR, which can retain complete contents from source images. Then, we propose the Spatial-Frequency Enhanced Mamba Block (SFMB), which can enhance Mamba in both spatial and frequency domains for comprehensive feature extraction. Finally, we propose the Dynamic Fusion Mamba Block (DFMB), which can be deployed across different branches for dynamic feature fusion. Extensive experiments show that our method achieves better results than most state-of-the-art methods on six MMIF datasets. The source code is available at https://github.com/SunHui1216/SFMFusion.
SD-ReID: View-aware Stable Diffusion for Aerial-Ground Person Re-Identification
Apr 13, 2025Aerial-Ground Person Re-IDentification (AG-ReID) aims to retrieve specific persons across cameras with different viewpoints. Previous works focus on designing discriminative ReID models to maintain identity consistency despite drastic changes in camera viewpoints. The core idea behind these methods is quite natural, but designing a view-robust network is a very challenging task. Moreover, they overlook the contribution of view-specific features in enhancing the model's capability to represent persons. To address these issues, we propose a novel two-stage feature learning framework named SD-ReID for AG-ReID, which takes advantage of the powerful understanding capacity of generative models, e.g., Stable Diffusion (SD), to generate view-specific features between different viewpoints. In the first stage, we train a simple ViT-based model to extract coarse-grained representations and controllable conditions. Then, in the second stage, we fine-tune the SD model to learn complementary representations guided by the controllable conditions. Furthermore, we propose the View-Refine Decoder (VRD) to obtain additional controllable conditions to generate missing cross-view features. Finally, we use the coarse-grained representations and all-view features generated by SD to retrieve target persons. Extensive experiments on the AG-ReID benchmarks demonstrate the effectiveness of our proposed SD-ReID. The source code will be available upon acceptance.