 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
Living the Novel: A System for Generating Self-Training Timeline-Aware Conversational Agents from Novels
Dec 08, 2025



We present the Living Novel, an end-to-end system that transforms any literary work into an immersive, multi-character conversational experience. This system is designed to solve two fundamental challenges for LLM-driven characters. Firstly, generic LLMs suffer from persona drift, often failing to stay in character. Secondly, agents often exhibit abilities that extend beyond the constraints of the story's world and logic, leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking). To address these challenges, we introduce a novel two-stage training pipeline. Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity. Our Coherence and Robustness Enhancing (CRE) stage then employs a story-time-aware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints. We validate our system through a multi-phase evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea. A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study. Our DPA pipeline helps our specialized model outperform GPT-4o on persona-specific metrics, and our CRE stage achieves near-perfect performance in coherence and robustness measures. Our study surfaces practical design guidelines for AI-driven narrative systems: we find that character-first self-training is foundational for believability, while explicit story-time constraints are crucial for sustaining coherent, interruption-resilient mobile-web experiences.
Parameter Aware Mamba Model for Multi-task Dense Prediction
Nov 18, 2025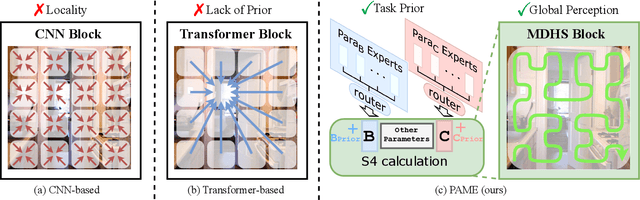
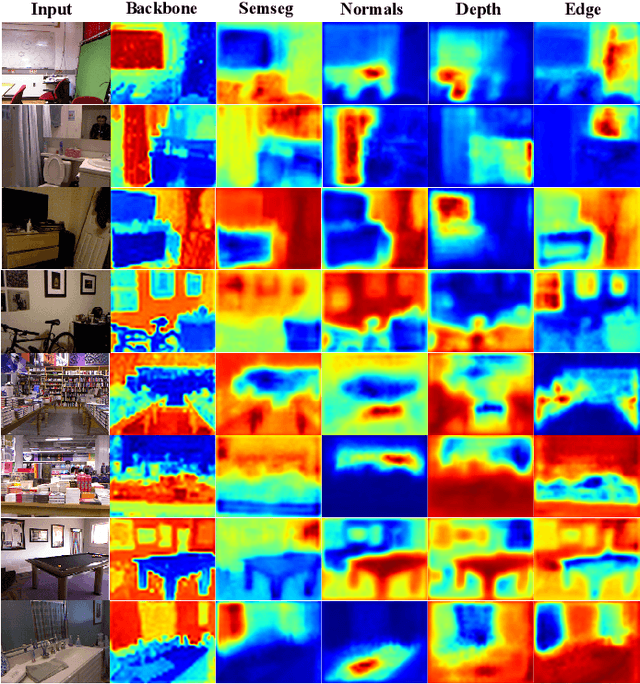
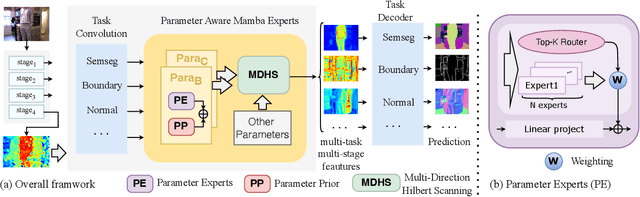
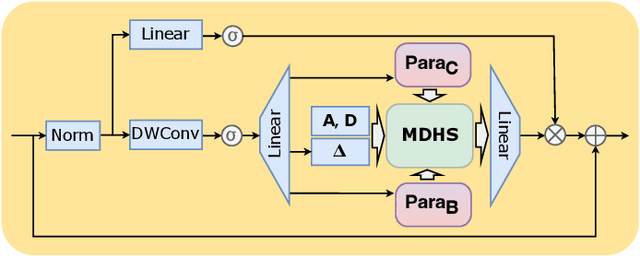
Understanding the inter-relations and interactions between tasks is crucial for multi-task dense prediction. Existing methods predominantly utilize convolutional layers and attention mechanisms to explore task-level interactions. In this work, we introduce a novel decoder-based framework, Parameter Aware Mamba Model (PAMM), specifically designed for dense prediction in multi-task learning setting. Distinct from approaches that employ Transformers to model holistic task relationships, PAMM leverages the rich, scalable parameters of state space models to enhance task interconnectivity. It features dual state space parameter experts that integrate and set task-specific parameter priors, capturing the intrinsic properties of each task. This approach not only facilitates precise multi-task interactions but also allows for the global integration of task priors through the structured state space sequence model (S4). Furthermore, we employ the Multi-Directional Hilbert Scanning method to construct multi-angle feature sequences, thereby enhancing the sequence model's perceptual capabilities for 2D data. Extensive experiments on the NYUD-v2 and PASCAL-Context benchmarks demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/CQC-gogopro/PAMM.
The Devil is in Temporal Token: High Quality Video Reasoning Segmentation
Jan 15, 2025



Existing methods for Video Reasoning Segmentation rely heavily on a single special token to represent the object in the keyframe or the entire video, inadequately capturing spatial complexity and inter-frame motion. To overcome these challenges, we propose VRS-HQ, an end-to-end video reasoning segmentation approach that leverages Multimodal Large Language Models (MLLMs) to inject rich spatiotemporal features into hierarchical tokens.Our key innovations include a Temporal Dynamic Aggregation (TDA) and a Token-driven Keyframe Selection (TKS). Specifically, we design frame-level <SEG> and temporal-level <TAK> tokens that utilize MLLM's autoregressive learning to effectively capture both local and global information. Subsequently, we apply a similarity-based weighted fusion and frame selection strategy, then utilize SAM2 to perform keyframe segmentation and propagation. To enhance keyframe localization accuracy, the TKS filters keyframes based on SAM2's occlusion scores during inference. VRS-HQ achieves state-of-the-art performance on ReVOS, surpassing VISA by 5.9%/12.5%/9.1% in J&F scores across the three subsets. These results highlight the strong temporal reasoning and segmentation capabilities of our method. Code and model weights will be released at VRS-HQ.
AVS-Mamba: Exploring Temporal and Multi-modal Mamba for Audio-Visual Segmentation
Jan 14, 2025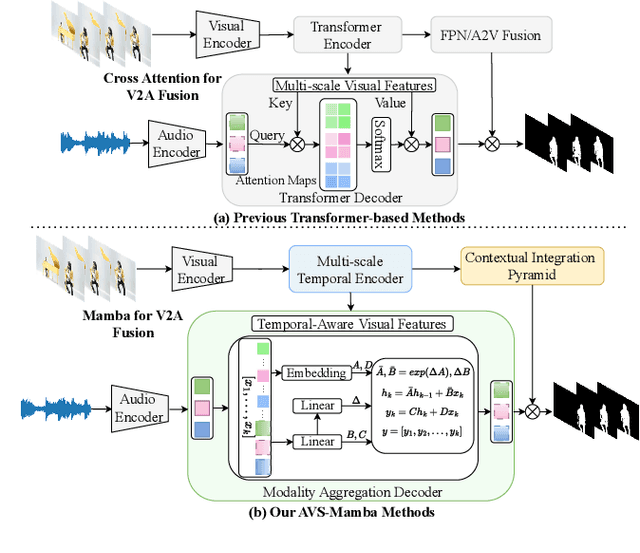

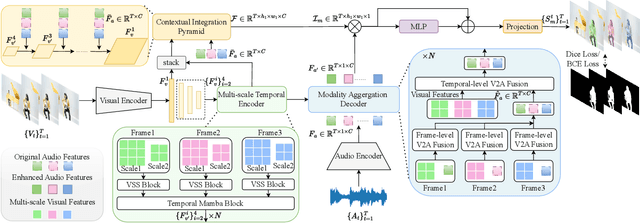
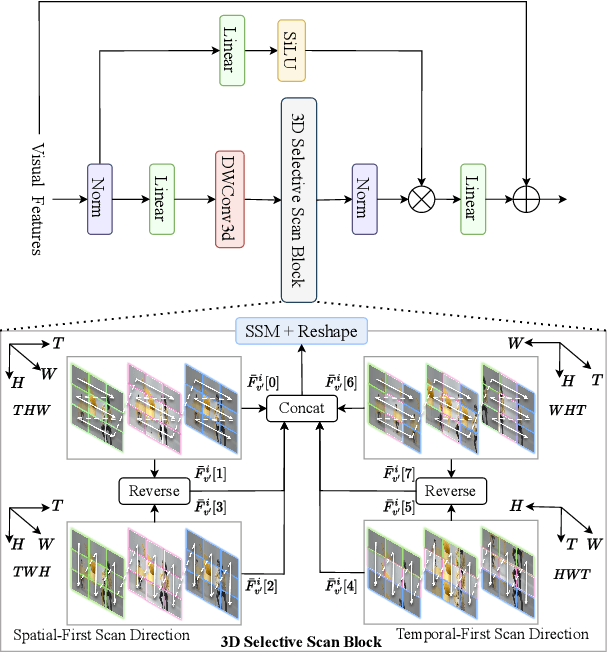
The essence of audio-visual segmentation (AVS) lies in locating and delineating sound-emitting objects within a video stream. While Transformer-based methods have shown promise, their handling of long-range dependencies struggles due to quadratic computational costs, presenting a bottleneck in complex scenarios. To overcome this limitation and facilitate complex multi-modal comprehension with linear complexity, we introduce AVS-Mamba, a selective state space model to address the AVS task. Our framework incorporates two key components for video understanding and cross-modal learning: Temporal Mamba Block for sequential video processing and Vision-to-Audio Fusion Block for advanced audio-vision integration. Building on this, we develop the Multi-scale Temporal Encoder, aimed at enhancing the learning of visual features across scales, facilitating the perception of intra- and inter-frame information. To perform multi-modal fusion, we propose the Modality Aggregation Decoder, leveraging the Vision-to-Audio Fusion Block to integrate visual features into audio features across both frame and temporal levels. Further, we adopt the Contextual Integration Pyramid to perform audio-to-vision spatial-temporal context collaboration. Through these innovative contributions, our approach achieves new state-of-the-art results on the AVSBench-object and AVSBench-semantic datasets. Our source code and model weights are available at AVS-Mamba.