 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: An LLM-driven Self Reflective Agentic Framework for Fraud Detection
Jun 06, 2026Fraud detection in payment, e-commerce, and telecommunications systems requires accuracy at the individual level, robustness under severe class imbalance, and ease of understanding for risk managers. Existing methods fall at least one of these requirements: automated machine learning systems search a fixed numerical space without semantic awareness of the dataset; graph neural network-based methods require pre-defined relational graphs and remain opaque at the individual-decision level; and the design of general-purpose large language model (LLM) agents does not consider the recall and precision constraints specific to real-world fraud detection. In this paper, we propose SAGE, the first end-to-end LLM-driven multi-agent framework for fraud detection. SAGE coordinates three dedicated agents that make decisions based on a six-layer Data Diagnostic Tree (DDT) and a Markov decision process guided by natural-language gradients, automatically optimizing the model under a fraud-specific reward. On five fraud datasets and five LLM backbones, SAGE wins $96.00\%$ of method--dataset comparisons and improves F1 by an average of $40.86\%$ over baselines. The code is available at https://github.com/yichenC1c/SAGE.
Revisiting Salient Object Detection from an Observer-Centric Perspective
Feb 06, 2026Salient object detection is inherently a subjective problem, as observers with different priors may perceive different objects as salient. However, existing methods predominantly formulate it as an objective prediction task with a single groundtruth segmentation map for each image, which renders the problem under-determined and fundamentally ill-posed. To address this issue, we propose Observer-Centric Salient Object Detection (OC-SOD), where salient regions are predicted by considering not only the visual cues but also the observer-specific factors such as their preferences or intents. As a result, this formulation captures the intrinsic ambiguity and diversity of human perception, enabling personalized and context-aware saliency prediction. By leveraging multi-modal large language models, we develop an efficient data annotation pipeline and construct the first OC-SOD dataset named OC-SODBench, comprising 33k training, validation and test images with 152k textual prompts and object pairs. Built upon this new dataset, we further design OC-SODAgent, an agentic baseline which performs OC-SOD via a human-like "Perceive-Reflect-Adjust" process. Extensive experiments on our proposed OC-SODBench have justified the effectiveness of our contribution. Through this observer-centric perspective, we aim to bridge the gap between human perception and computational modeling, offering a more realistic and flexible understanding of what makes an object truly "salient." Code and dataset are publicly available at: https://github.com/Dustzx/OC_SOD
Think3D: Thinking with Space for Spatial Reasoning
Jan 19, 2026Understanding and reasoning about the physical world requires spatial intelligence: the ability to interpret geometry, perspective, and spatial relations beyond 2D perception. While recent vision large models (VLMs) excel at visual understanding, they remain fundamentally 2D perceivers and struggle with genuine 3D reasoning. We introduce Think3D, a framework that enables VLM agents to think with 3D space. By leveraging 3D reconstruction models that recover point clouds and camera poses from images or videos, Think3D allows the agent to actively manipulate space through camera-based operations and ego/global-view switching, transforming spatial reasoning into an interactive 3D chain-of-thought process. Without additional training, Think3D significantly improves the spatial reasoning performance of advanced models such as GPT-4.1 and Gemini 2.5 Pro, yielding average gains of +7.8% on BLINK Multi-view and MindCube, and +4.7% on VSI-Bench. We further show that smaller models, which struggle with spatial exploration, benefit significantly from a reinforcement learning policy that enables the model to select informative viewpoints and operations. With RL, the benefit from tool usage increases from +0.7% to +6.8%. Our findings demonstrate that training-free, tool-augmented spatial exploration is a viable path toward more flexible and human-like 3D reasoning in multimodal agents, establishing a new dimension of multimodal intelligence. Code and weights are released at https://github.com/zhangzaibin/spagent.
AR-MOT: Autoregressive Multi-object Tracking
Jan 05, 2026As multi-object tracking (MOT) tasks continue to evolve toward more general and multi-modal scenarios, the rigid and task-specific architectures of existing MOT methods increasingly hinder their applicability across diverse tasks and limit flexibility in adapting to new tracking formulations. Most approaches rely on fixed output heads and bespoke tracking pipelines, making them difficult to extend to more complex or instruction-driven tasks. To address these limitations, we propose AR-MOT, a novel autoregressive paradigm that formulates MOT as a sequence generation task within a large language model (LLM) framework. This design enables the model to output structured results through flexible sequence construction, without requiring any task-specific heads. To enhance region-level visual perception, we introduce an Object Tokenizer based on a pretrained detector. To mitigate the misalignment between global and regional features, we propose a Region-Aware Alignment (RAA) module, and to support long-term tracking, we design a Temporal Memory Fusion (TMF) module that caches historical object tokens. AR-MOT offers strong potential for extensibility, as new modalities or instructions can be integrated by simply modifying the output sequence format without altering the model architecture. Extensive experiments on MOT17 and DanceTrack validate the feasibility of our approach, achieving performance comparable to state-of-the-art methods while laying the foundation for more general and flexible MOT systems.
Optimal Labeler Assignment and Sampling for Active Learning in the Presence of Imperfect Labels
Dec 14, 2025Active Learning (AL) has garnered significant interest across various application domains where labeling training data is costly. AL provides a framework that helps practitioners query informative samples for annotation by oracles (labelers). However, these labels often contain noise due to varying levels of labeler accuracy. Additionally, uncertain samples are more prone to receiving incorrect labels because of their complexity. Learning from imperfectly labeled data leads to an inaccurate classifier. We propose a novel AL framework to construct a robust classification model by minimizing noise levels. Our approach includes an assignment model that optimally assigns query points to labelers, aiming to minimize the maximum possible noise within each cycle. Additionally, we introduce a new sampling method to identify the best query points, reducing the impact of label noise on classifier performance. Our experiments demonstrate that our approach significantly improves classification performance compared to several benchmark methods.
Beyond Classification Accuracy: Neural-MedBench and the Need for Deeper Reasoning Benchmarks
Sep 26, 2025Recent advances in vision-language models (VLMs) have achieved remarkable performance on standard medical benchmarks, yet their true clinical reasoning ability remains unclear. Existing datasets predominantly emphasize classification accuracy, creating an evaluation illusion in which models appear proficient while still failing at high-stakes diagnostic reasoning. We introduce Neural-MedBench, a compact yet reasoning-intensive benchmark specifically designed to probe the limits of multimodal clinical reasoning in neurology. Neural-MedBench integrates multi-sequence MRI scans, structured electronic health records, and clinical notes, and encompasses three core task families: differential diagnosis, lesion recognition, and rationale generation. To ensure reliable evaluation, we develop a hybrid scoring pipeline that combines LLM-based graders, clinician validation, and semantic similarity metrics. Through systematic evaluation of state-of-the-art VLMs, including GPT-4o, Claude-4, and MedGemma, we observe a sharp performance drop compared to conventional datasets. Error analysis shows that reasoning failures, rather than perceptual errors, dominate model shortcomings. Our findings highlight the necessity of a Two-Axis Evaluation Framework: breadth-oriented large datasets for statistical generalization, and depth-oriented, compact benchmarks such as Neural-MedBench for reasoning fidelity. We release Neural-MedBench at https://neuromedbench.github.io/ as an open and extensible diagnostic testbed, which guides the expansion of future benchmarks and enables rigorous yet cost-effective assessment of clinically trustworthy AI.
Efficiently Building a Domain-Specific Large Language Model from Scratch: A Case Study of a Classical Chinese Large Language Model
May 17, 2025General-purpose large language models demonstrate notable capabilities in language comprehension and generation, achieving results that are comparable to, or even surpass, human performance in many language information processing tasks. Nevertheless, when general models are applied to some specific domains, e.g., Classical Chinese texts, their effectiveness is often unsatisfactory, and fine-tuning open-source foundational models similarly struggles to adequately incorporate domain-specific knowledge. To address this challenge, this study developed a large language model, AI Taiyan, specifically designed for understanding and generating Classical Chinese. Experiments show that with a reasonable model design, data processing, foundational training, and fine-tuning, satisfactory results can be achieved with only 1.8 billion parameters. In key tasks related to Classical Chinese information processing such as punctuation, identification of allusions, explanation of word meanings, and translation between ancient and modern Chinese, this model exhibits a clear advantage over both general-purpose large models and domain-specific traditional models, achieving levels close to or surpassing human baselines. This research provides a reference for the efficient construction of specialized domain-specific large language models. Furthermore, the paper discusses the application of this model in fields such as the collation of ancient texts, dictionary editing, and language research, combined with case studies.
Learning Universal Features for Generalizable Image Forgery Localization
Apr 10, 2025In recent years, advanced image editing and generation methods have rapidly evolved, making detecting and locating forged image content increasingly challenging. Most existing image forgery detection methods rely on identifying the edited traces left in the image. However, because the traces of different forgeries are distinct, these methods can identify familiar forgeries included in the training data but struggle to handle unseen ones. In response, we present an approach for Generalizable Image Forgery Localization (GIFL). Once trained, our model can detect both seen and unseen forgeries, providing a more practical and efficient solution to counter false information in the era of generative AI. Our method focuses on learning general features from the pristine content rather than traces of specific forgeries, which are relatively consistent across different types of forgeries and therefore can be used as universal features to locate unseen forgeries. Additionally, as existing image forgery datasets are still dominated by traditional hand-crafted forgeries, we construct a new dataset consisting of images edited by various popular deep generative image editing methods to further encourage research in detecting images manipulated by deep generative models. Extensive experimental results show that the proposed approach outperforms state-of-the-art methods in the detection of unseen forgeries and also demonstrates competitive results for seen forgeries. The code and dataset are available at https://github.com/ZhaoHengrun/GIFL.
Mono2Stereo: A Benchmark and Empirical Study for Stereo Conversion
Mar 28, 2025With the rapid proliferation of 3D devices and the shortage of 3D content, stereo conversion is attracting increasing attention. Recent works introduce pretrained Diffusion Models (DMs) into this task. However, due to the scarcity of large-scale training data and comprehensive benchmarks, the optimal methodologies for employing DMs in stereo conversion and the accurate evaluation of stereo effects remain largely unexplored. In this work, we introduce the Mono2Stereo dataset, providing high-quality training data and benchmark to support in-depth exploration of stereo conversion. With this dataset, we conduct an empirical study that yields two primary findings. 1) The differences between the left and right views are subtle, yet existing metrics consider overall pixels, failing to concentrate on regions critical to stereo effects. 2) Mainstream methods adopt either one-stage left-to-right generation or warp-and-inpaint pipeline, facing challenges of degraded stereo effect and image distortion respectively. Based on these findings, we introduce a new evaluation metric, Stereo Intersection-over-Union, which prioritizes disparity and achieves a high correlation with human judgments on stereo effect. Moreover, we propose a strong baseline model, harmonizing the stereo effect and image quality simultaneously, and notably surpassing current mainstream methods. Our code and data will be open-sourced to promote further research in stereo conversion. Our models are available at mono2stereo-bench.github.io.
AVS-Mamba: Exploring Temporal and Multi-modal Mamba for Audio-Visual Segmentation
Jan 14, 2025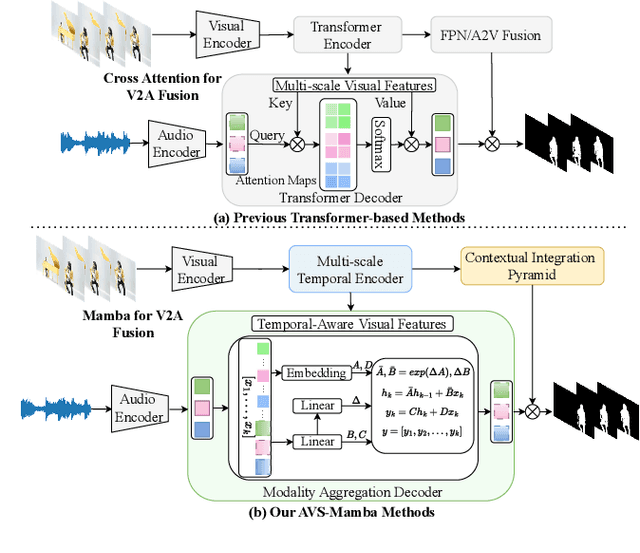

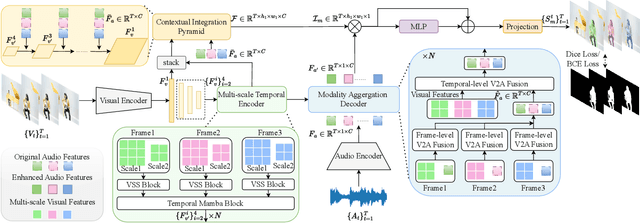
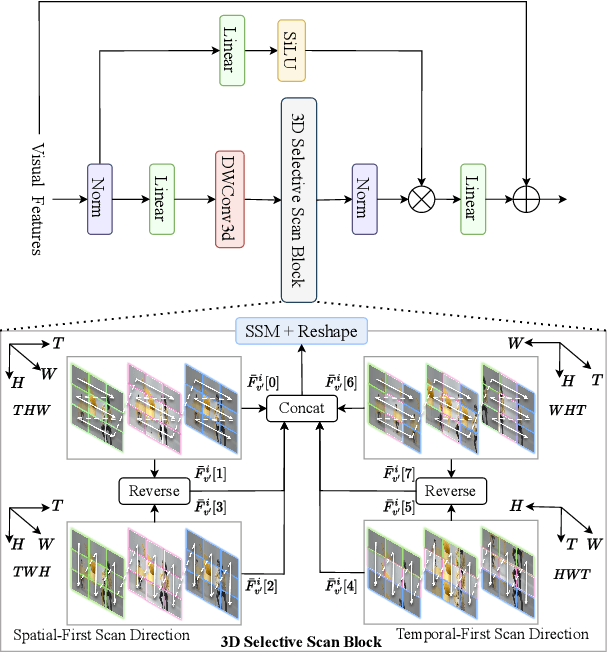
The essence of audio-visual segmentation (AVS) lies in locating and delineating sound-emitting objects within a video stream. While Transformer-based methods have shown promise, their handling of long-range dependencies struggles due to quadratic computational costs, presenting a bottleneck in complex scenarios. To overcome this limitation and facilitate complex multi-modal comprehension with linear complexity, we introduce AVS-Mamba, a selective state space model to address the AVS task. Our framework incorporates two key components for video understanding and cross-modal learning: Temporal Mamba Block for sequential video processing and Vision-to-Audio Fusion Block for advanced audio-vision integration. Building on this, we develop the Multi-scale Temporal Encoder, aimed at enhancing the learning of visual features across scales, facilitating the perception of intra- and inter-frame information. To perform multi-modal fusion, we propose the Modality Aggregation Decoder, leveraging the Vision-to-Audio Fusion Block to integrate visual features into audio features across both frame and temporal levels. Further, we adopt the Contextual Integration Pyramid to perform audio-to-vision spatial-temporal context collaboration. Through these innovative contributions, our approach achieves new state-of-the-art results on the AVSBench-object and AVSBench-semantic datasets. Our source code and model weights are available at AVS-Mamba.