 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLDesigner: Leveraging Multi-Modal LLMs as Designer for Enhanced Aesthetic Text Glyph Layouts
Nov 18, 2024

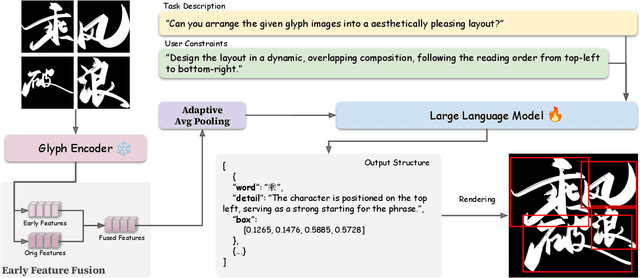
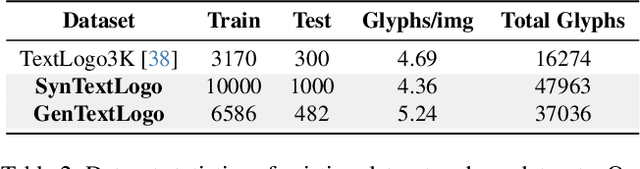
Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this specific task which needs to take precise textural details and user constraints into consideration, but only on the broader tasks such as document/poster layout generation. In this paper, we propose a VLM-based framework that generates content-aware text logo layouts by integrating multi-modal inputs with user constraints, supporting a more flexible and stable layout design in real-world applications. We introduce two model techniques to reduce the computation for processing multiple glyph images simultaneously, while does not face performance degradation. To support instruction-tuning of out model, we construct two extensive text logo datasets, which are 5x more larger than the existing public dataset. Except for the geometric annotations (e.g. text masks and character recognition), we also compliment with comprehensive layout descriptions in natural language format, for more effective training to have reasoning ability when dealing with complex layouts and custom user constraints. Experimental studies demonstrate the effectiveness of our proposed model and datasets, when comparing with previous methods in various benchmarks to evaluate geometric aesthetics and human preferences. The code and datasets will be publicly available.
Multi-modal Instruction Tuned LLMs with Fine-grained Visual Perception
Mar 05, 2024Multimodal Large Language Model (MLLMs) leverages Large Language Models as a cognitive framework for diverse visual-language tasks. Recent efforts have been made to equip MLLMs with visual perceiving and grounding capabilities. However, there still remains a gap in providing fine-grained pixel-level perceptions and extending interactions beyond text-specific inputs. In this work, we propose {\bf{AnyRef}}, a general MLLM model that can generate pixel-wise object perceptions and natural language descriptions from multi-modality references, such as texts, boxes, images, or audio. This innovation empowers users with greater flexibility to engage with the model beyond textual and regional prompts, without modality-specific designs. Through our proposed refocusing mechanism, the generated grounding output is guided to better focus on the referenced object, implicitly incorporating additional pixel-level supervision. This simple modification utilizes attention scores generated during the inference of LLM, eliminating the need for extra computations while exhibiting performance enhancements in both grounding masks and referring expressions. With only publicly available training data, our model achieves state-of-the-art results across multiple benchmarks, including diverse modality referring segmentation and region-level referring expression generation.
Towards Deeply Unified Depth-aware Panoptic Segmentation with Bi-directional Guidance Learning
Aug 14, 2023Depth-aware panoptic segmentation is an emerging topic in computer vision which combines semantic and geometric understanding for more robust scene interpretation. Recent works pursue unified frameworks to tackle this challenge but mostly still treat it as two individual learning tasks, which limits their potential for exploring cross-domain information. We propose a deeply unified framework for depth-aware panoptic segmentation, which performs joint segmentation and depth estimation both in a per-segment manner with identical object queries. To narrow the gap between the two tasks, we further design a geometric query enhancement method, which is able to integrate scene geometry into object queries using latent representations. In addition, we propose a bi-directional guidance learning approach to facilitate cross-task feature learning by taking advantage of their mutual relations. Our method sets the new state of the art for depth-aware panoptic segmentation on both Cityscapes-DVPS and SemKITTI-DVPS datasets. Moreover, our guidance learning approach is shown to deliver performance improvement even under incomplete supervision labels.