 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Jun 28, 2024
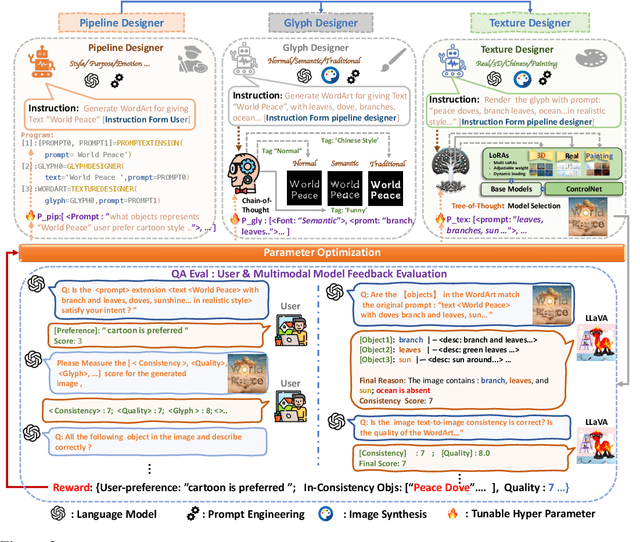
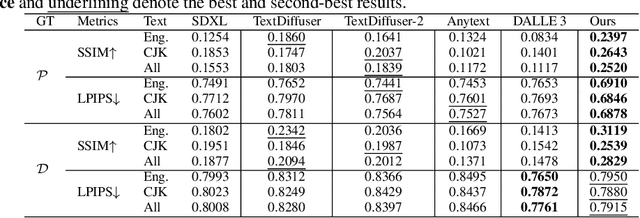
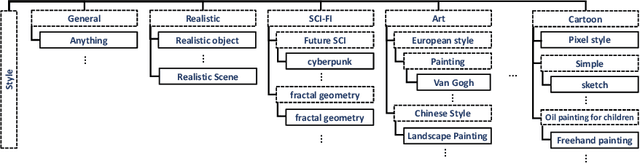
MetaDesigner revolutionizes artistic typography synthesis by leveraging the strengths of Large Language Models (LLMs) to drive a design paradigm centered around user engagement. At the core of this framework lies a multi-agent system comprising the Pipeline, Glyph, and Texture agents, which collectively enable the creation of customized WordArt, ranging from semantic enhancements to the imposition of complex textures. MetaDesigner incorporates a comprehensive feedback mechanism that harnesses insights from multimodal models and user evaluations to refine and enhance the design process iteratively. Through this feedback loop, the system adeptly tunes hyperparameters to align with user-defined stylistic and thematic preferences, generating WordArt that not only meets but exceeds user expectations of visual appeal and contextual relevance. Empirical validations highlight MetaDesigner's capability to effectively serve diverse WordArt applications, consistently producing aesthetically appealing and context-sensitive results.
VirtualModel: Generating Object-ID-retentive Human-object Interaction Image by Diffusion Model for E-commerce Marketing
May 16, 2024Due to the significant advances in large-scale text-to-image generation by diffusion model (DM), controllable human image generation has been attracting much attention recently. Existing works, such as Controlnet [36], T2I-adapter [20] and HumanSD [10] have demonstrated good abilities in generating human images based on pose conditions, they still fail to meet the requirements of real e-commerce scenarios. These include (1) the interaction between the shown product and human should be considered, (2) human parts like face/hand/arm/foot and the interaction between human model and product should be hyper-realistic, and (3) the identity of the product shown in advertising should be exactly consistent with the product itself. To this end, in this paper, we first define a new human image generation task for e-commerce marketing, i.e., Object-ID-retentive Human-object Interaction image Generation (OHG), and then propose a VirtualModel framework to generate human images for product shown, which supports displays of any categories of products and any types of human-object interaction. As shown in Figure 1, VirtualModel not only outperforms other methods in terms of accurate pose control and image quality but also allows for the display of user-specified product objects by maintaining the product-ID consistency and enhancing the plausibility of human-object interaction. Codes and data will be released.
RobustMVS: Single Domain Generalized Deep Multi-view Stereo
May 15, 2024



Despite the impressive performance of Multi-view Stereo (MVS) approaches given plenty of training samples, the performance degradation when generalizing to unseen domains has not been clearly explored yet. In this work, we focus on the domain generalization problem in MVS. To evaluate the generalization results, we build a novel MVS domain generalization benchmark including synthetic and real-world datasets. In contrast to conventional domain generalization benchmarks, we consider a more realistic but challenging scenario, where only one source domain is available for training. The MVS problem can be analogized back to the feature matching task, and maintaining robust feature consistency among views is an important factor for improving generalization performance. To address the domain generalization problem in MVS, we propose a novel MVS framework, namely RobustMVS. A DepthClustering-guided Whitening (DCW) loss is further introduced to preserve the feature consistency among different views, which decorrelates multi-view features from viewpoint-specific style information based on geometric priors from depth maps. The experimental results further show that our method achieves superior performance on the domain generalization benchmark.
SmartControl: Enhancing ControlNet for Handling Rough Visual Conditions
Apr 09, 2024Human visual imagination usually begins with analogies or rough sketches. For example, given an image with a girl playing guitar before a building, one may analogously imagine how it seems like if Iron Man playing guitar before Pyramid in Egypt. Nonetheless, visual condition may not be precisely aligned with the imaginary result indicated by text prompt, and existing layout-controllable text-to-image (T2I) generation models is prone to producing degraded generated results with obvious artifacts. To address this issue, we present a novel T2I generation method dubbed SmartControl, which is designed to modify the rough visual conditions for adapting to text prompt. The key idea of our SmartControl is to relax the visual condition on the areas that are conflicted with text prompts. In specific, a Control Scale Predictor (CSP) is designed to identify the conflict regions and predict the local control scales, while a dataset with text prompts and rough visual conditions is constructed for training CSP. It is worth noting that, even with a limited number (e.g., 1,000~2,000) of training samples, our SmartControl can generalize well to unseen objects. Extensive experiments on four typical visual condition types clearly show the efficacy of our SmartControl against state-of-the-arts. Source code, pre-trained models, and datasets are available at https://github.com/liuxiaoyu1104/SmartControl.
DreamView: Injecting View-specific Text Guidance into Text-to-3D Generation
Apr 09, 2024



Text-to-3D generation, which synthesizes 3D assets according to an overall text description, has significantly progressed. However, a challenge arises when the specific appearances need customizing at designated viewpoints but referring solely to the overall description for generating 3D objects. For instance, ambiguity easily occurs when producing a T-shirt with distinct patterns on its front and back using a single overall text guidance. In this work, we propose DreamView, a text-to-image approach enabling multi-view customization while maintaining overall consistency by adaptively injecting the view-specific and overall text guidance through a collaborative text guidance injection module, which can also be lifted to 3D generation via score distillation sampling. DreamView is trained with large-scale rendered multi-view images and their corresponding view-specific texts to learn to balance the separate content manipulation in each view and the global consistency of the overall object, resulting in a dual achievement of customization and consistency. Consequently, DreamView empowers artists to design 3D objects creatively, fostering the creation of more innovative and diverse 3D assets. Code and model will be released at https://github.com/iSEE-Laboratory/DreamView.
ShoeModel: Learning to Wear on the User-specified Shoes via Diffusion Model
Apr 07, 2024



With the development of the large-scale diffusion model, Artificial Intelligence Generated Content (AIGC) techniques are popular recently. However, how to truly make it serve our daily lives remains an open question. To this end, in this paper, we focus on employing AIGC techniques in one filed of E-commerce marketing, i.e., generating hyper-realistic advertising images for displaying user-specified shoes by human. Specifically, we propose a shoe-wearing system, called Shoe-Model, to generate plausible images of human legs interacting with the given shoes. It consists of three modules: (1) shoe wearable-area detection module (WD), (2) leg-pose synthesis module (LpS) and the final (3) shoe-wearing image generation module (SW). Them three are performed in ordered stages. Compared to baselines, our ShoeModel is shown to generalize better to different type of shoes and has ability of keeping the ID-consistency of the given shoes, as well as automatically producing reasonable interactions with human. Extensive experiments show the effectiveness of our proposed shoe-wearing system. Figure 1 shows the input and output examples of our ShoeModel.
Strictly-ID-Preserved and Controllable Accessory Advertising Image Generation
Apr 07, 2024



Customized generative text-to-image models have the ability to produce images that closely resemble a given subject. However, in the context of generating advertising images for e-commerce scenarios, it is crucial that the generated subject's identity aligns perfectly with the product being advertised. In order to address the need for strictly-ID preserved advertising image generation, we have developed a Control-Net based customized image generation pipeline and have taken earring model advertising as an example. Our approach facilitates a seamless interaction between the earrings and the model's face, while ensuring that the identity of the earrings remains intact. Furthermore, to achieve a diverse and controllable display, we have proposed a multi-branch cross-attention architecture, which allows for control over the scale, pose, and appearance of the model, going beyond the limitations of text prompts. Our method manages to achieve fine-grained control of the generated model's face, resulting in controllable and captivating advertising effects.
VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
Mar 08, 2024Text-to-image diffusion models (T2I) have demonstrated unprecedented capabilities in creating realistic and aesthetic images. On the contrary, text-to-video diffusion models (T2V) still lag far behind in frame quality and text alignment, owing to insufficient quality and quantity of training videos. In this paper, we introduce VideoElevator, a training-free and plug-and-play method, which elevates the performance of T2V using superior capabilities of T2I. Different from conventional T2V sampling (i.e., temporal and spatial modeling), VideoElevator explicitly decomposes each sampling step into temporal motion refining and spatial quality elevating. Specifically, temporal motion refining uses encapsulated T2V to enhance temporal consistency, followed by inverting to the noise distribution required by T2I. Then, spatial quality elevating harnesses inflated T2I to directly predict less noisy latent, adding more photo-realistic details. We have conducted experiments in extensive prompts under the combination of various T2V and T2I. The results show that VideoElevator not only improves the performance of T2V baselines with foundational T2I, but also facilitates stylistic video synthesis with personalized T2I. Our code is available at https://github.com/YBYBZhang/VideoElevator.
Multi-modal Instruction Tuned LLMs with Fine-grained Visual Perception
Mar 05, 2024Multimodal Large Language Model (MLLMs) leverages Large Language Models as a cognitive framework for diverse visual-language tasks. Recent efforts have been made to equip MLLMs with visual perceiving and grounding capabilities. However, there still remains a gap in providing fine-grained pixel-level perceptions and extending interactions beyond text-specific inputs. In this work, we propose {\bf{AnyRef}}, a general MLLM model that can generate pixel-wise object perceptions and natural language descriptions from multi-modality references, such as texts, boxes, images, or audio. This innovation empowers users with greater flexibility to engage with the model beyond textual and regional prompts, without modality-specific designs. Through our proposed refocusing mechanism, the generated grounding output is guided to better focus on the referenced object, implicitly incorporating additional pixel-level supervision. This simple modification utilizes attention scores generated during the inference of LLM, eliminating the need for extra computations while exhibiting performance enhancements in both grounding masks and referring expressions. With only publicly available training data, our model achieves state-of-the-art results across multiple benchmarks, including diverse modality referring segmentation and region-level referring expression generation.
DivAvatar: Diverse 3D Avatar Generation with a Single Prompt
Feb 27, 2024



Text-to-Avatar generation has recently made significant strides due to advancements in diffusion models. However, most existing work remains constrained by limited diversity, producing avatars with subtle differences in appearance for a given text prompt. We design DivAvatar, a novel framework that generates diverse avatars, empowering 3D creatives with a multitude of distinct and richly varied 3D avatars from a single text prompt. Different from most existing work that exploits scene-specific 3D representations such as NeRF, DivAvatar finetunes a 3D generative model (i.e., EVA3D), allowing diverse avatar generation from simply noise sampling in inference time. DivAvatar has two key designs that help achieve generation diversity and visual quality. The first is a noise sampling technique during training phase which is critical in generating diverse appearances. The second is a semantic-aware zoom mechanism and a novel depth loss, the former producing appearances of high textual fidelity by separate fine-tuning of specific body parts and the latter improving geometry quality greatly by smoothing the generated mesh in the features space. Extensive experiments show that DivAvatar is highly versatile in generating avatars of diverse appearances.