 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyStory: Towards Unified Single and Multiple Subject Personalization in Text-to-Image Generation
Jan 16, 2025



Recently, large-scale generative models have demonstrated outstanding text-to-image generation capabilities. However, generating high-fidelity personalized images with specific subjects still presents challenges, especially in cases involving multiple subjects. In this paper, we propose AnyStory, a unified approach for personalized subject generation. AnyStory not only achieves high-fidelity personalization for single subjects, but also for multiple subjects, without sacrificing subject fidelity. Specifically, AnyStory models the subject personalization problem in an "encode-then-route" manner. In the encoding step, AnyStory utilizes a universal and powerful image encoder, i.e., ReferenceNet, in conjunction with CLIP vision encoder to achieve high-fidelity encoding of subject features. In the routing step, AnyStory utilizes a decoupled instance-aware subject router to accurately perceive and predict the potential location of the corresponding subject in the latent space, and guide the injection of subject conditions. Detailed experimental results demonstrate the excellent performance of our method in retaining subject details, aligning text descriptions, and personalizing for multiple subjects. The project page is at https://aigcdesigngroup.github.io/AnyStory/ .
AdaptiveDrag: Semantic-Driven Dragging on Diffusion-Based Image Editing
Oct 16, 2024



Recently, several point-based image editing methods (e.g., DragDiffusion, FreeDrag, DragNoise) have emerged, yielding precise and high-quality results based on user instructions. However, these methods often make insufficient use of semantic information, leading to less desirable results. In this paper, we proposed a novel mask-free point-based image editing method, AdaptiveDrag, which provides a more flexible editing approach and generates images that better align with user intent. Specifically, we design an auto mask generation module using super-pixel division for user-friendliness. Next, we leverage a pre-trained diffusion model to optimize the latent, enabling the dragging of features from handle points to target points. To ensure a comprehensive connection between the input image and the drag process, we have developed a semantic-driven optimization. We design adaptive steps that are supervised by the positions of the points and the semantic regions derived from super-pixel segmentation. This refined optimization process also leads to more realistic and accurate drag results. Furthermore, to address the limitations in the generative consistency of the diffusion model, we introduce an innovative corresponding loss during the sampling process. Building on these effective designs, our method delivers superior generation results using only the single input image and the handle-target point pairs. Extensive experiments have been conducted and demonstrate that the proposed method outperforms others in handling various drag instructions (e.g., resize, movement, extension) across different domains (e.g., animals, human face, land space, clothing).
VirtualModel: Generating Object-ID-retentive Human-object Interaction Image by Diffusion Model for E-commerce Marketing
May 16, 2024Due to the significant advances in large-scale text-to-image generation by diffusion model (DM), controllable human image generation has been attracting much attention recently. Existing works, such as Controlnet [36], T2I-adapter [20] and HumanSD [10] have demonstrated good abilities in generating human images based on pose conditions, they still fail to meet the requirements of real e-commerce scenarios. These include (1) the interaction between the shown product and human should be considered, (2) human parts like face/hand/arm/foot and the interaction between human model and product should be hyper-realistic, and (3) the identity of the product shown in advertising should be exactly consistent with the product itself. To this end, in this paper, we first define a new human image generation task for e-commerce marketing, i.e., Object-ID-retentive Human-object Interaction image Generation (OHG), and then propose a VirtualModel framework to generate human images for product shown, which supports displays of any categories of products and any types of human-object interaction. As shown in Figure 1, VirtualModel not only outperforms other methods in terms of accurate pose control and image quality but also allows for the display of user-specified product objects by maintaining the product-ID consistency and enhancing the plausibility of human-object interaction. Codes and data will be released.
ShoeModel: Learning to Wear on the User-specified Shoes via Diffusion Model
Apr 07, 2024



With the development of the large-scale diffusion model, Artificial Intelligence Generated Content (AIGC) techniques are popular recently. However, how to truly make it serve our daily lives remains an open question. To this end, in this paper, we focus on employing AIGC techniques in one filed of E-commerce marketing, i.e., generating hyper-realistic advertising images for displaying user-specified shoes by human. Specifically, we propose a shoe-wearing system, called Shoe-Model, to generate plausible images of human legs interacting with the given shoes. It consists of three modules: (1) shoe wearable-area detection module (WD), (2) leg-pose synthesis module (LpS) and the final (3) shoe-wearing image generation module (SW). Them three are performed in ordered stages. Compared to baselines, our ShoeModel is shown to generalize better to different type of shoes and has ability of keeping the ID-consistency of the given shoes, as well as automatically producing reasonable interactions with human. Extensive experiments show the effectiveness of our proposed shoe-wearing system. Figure 1 shows the input and output examples of our ShoeModel.
Strictly-ID-Preserved and Controllable Accessory Advertising Image Generation
Apr 07, 2024



Customized generative text-to-image models have the ability to produce images that closely resemble a given subject. However, in the context of generating advertising images for e-commerce scenarios, it is crucial that the generated subject's identity aligns perfectly with the product being advertised. In order to address the need for strictly-ID preserved advertising image generation, we have developed a Control-Net based customized image generation pipeline and have taken earring model advertising as an example. Our approach facilitates a seamless interaction between the earrings and the model's face, while ensuring that the identity of the earrings remains intact. Furthermore, to achieve a diverse and controllable display, we have proposed a multi-branch cross-attention architecture, which allows for control over the scale, pose, and appearance of the model, going beyond the limitations of text prompts. Our method manages to achieve fine-grained control of the generated model's face, resulting in controllable and captivating advertising effects.
Virtual Classification: Modulating Domain-Specific Knowledge for Multidomain Crowd Counting
Feb 06, 2024



Multidomain crowd counting aims to learn a general model for multiple diverse datasets. However, deep networks prefer modeling distributions of the dominant domains instead of all domains, which is known as domain bias. In this study, we propose a simple-yet-effective Modulating Domain-specific Knowledge Network (MDKNet) to handle the domain bias issue in multidomain crowd counting. MDKNet is achieved by employing the idea of `modulating', enabling deep network balancing and modeling different distributions of diverse datasets with little bias. Specifically, we propose an Instance-specific Batch Normalization (IsBN) module, which serves as a base modulator to refine the information flow to be adaptive to domain distributions. To precisely modulating the domain-specific information, the Domain-guided Virtual Classifier (DVC) is then introduced to learn a domain-separable latent space. This space is employed as an input guidance for the IsBN modulator, such that the mixture distributions of multiple datasets can be well treated. Extensive experiments performed on popular benchmarks, including Shanghai-tech A/B, QNRF and NWPU, validate the superiority of MDKNet in tackling multidomain crowd counting and the effectiveness for multidomain learning. Code is available at \url{https://github.com/csguomy/MDKNet}.
* Multidomain learning; Domain-guided virtual classifier; Instance-specific batch normalization
Regressor-Segmenter Mutual Prompt Learning for Crowd Counting
Dec 04, 2023Crowd counting has achieved significant progress by training regressors to predict instance positions. In heavily crowded scenarios, however, regressors are challenged by uncontrollable annotation variance, which causes density map bias and context information inaccuracy. In this study, we propose mutual prompt learning (mPrompt), which leverages a regressor and a segmenter as guidance for each other, solving bias and inaccuracy caused by annotation variance while distinguishing foreground from background. In specific, mPrompt leverages point annotations to tune the segmenter and predict pseudo head masks in a way of point prompt learning. It then uses the predicted segmentation masks, which serve as spatial constraint, to rectify biased point annotations as context prompt learning. mPrompt defines a way of mutual information maximization from prompt learning, mitigating the impact of annotation variance while improving model accuracy. Experiments show that mPrompt significantly reduces the Mean Average Error (MAE), demonstrating the potential to be general framework for down-stream vision tasks.
DAMO-StreamNet: Optimizing Streaming Perception in Autonomous Driving
Apr 05, 2023



Real-time perception, or streaming perception, is a crucial aspect of autonomous driving that has yet to be thoroughly explored in existing research. To address this gap, we present DAMO-StreamNet, an optimized framework that combines recent advances from the YOLO series with a comprehensive analysis of spatial and temporal perception mechanisms, delivering a cutting-edge solution. The key innovations of DAMO-StreamNet are: (1) A robust neck structure incorporating deformable convolution, enhancing the receptive field and feature alignment capabilities. (2) A dual-branch structure that integrates short-path semantic features and long-path temporal features, improving motion state prediction accuracy. (3) Logits-level distillation for efficient optimization, aligning the logits of teacher and student networks in semantic space. (4) A real-time forecasting mechanism that updates support frame features with the current frame, ensuring seamless streaming perception during inference. Our experiments demonstrate that DAMO-StreamNet surpasses existing state-of-the-art methods, achieving 37.8% (normal size (600, 960)) and 43.3% (large size (1200, 1920)) sAP without using extra data. This work not only sets a new benchmark for real-time perception but also provides valuable insights for future research. Additionally, DAMO-StreamNet can be applied to various autonomous systems, such as drones and robots, paving the way for real-time perception. The code is available at https://github.com/zhiqic/DAMO-StreamNet.
Learning Polysemantic Spoof Trace: A Multi-Modal Disentanglement Network for Face Anti-spoofing
Dec 07, 2022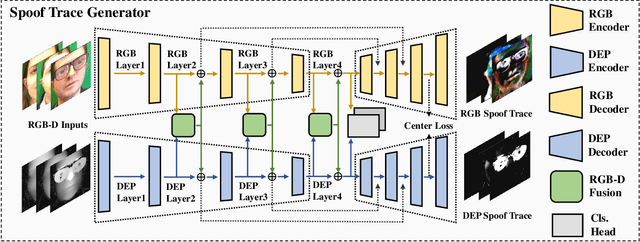
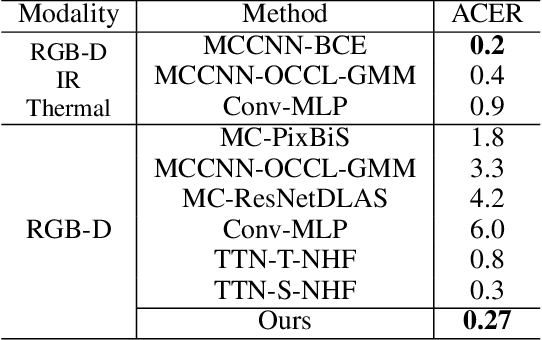
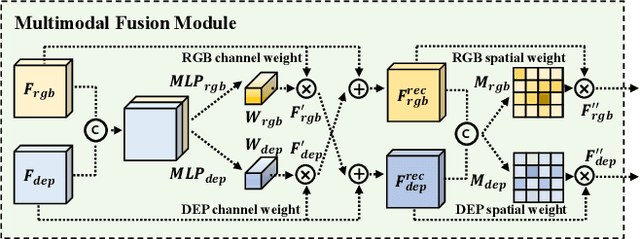
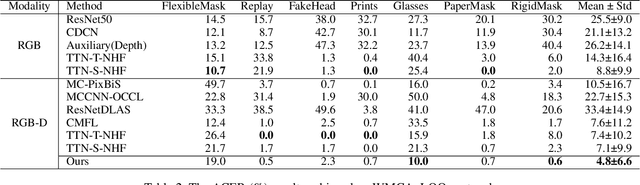
Along with the widespread use of face recognition systems, their vulnerability has become highlighted. While existing face anti-spoofing methods can be generalized between attack types, generic solutions are still challenging due to the diversity of spoof characteristics. Recently, the spoof trace disentanglement framework has shown great potential for coping with both seen and unseen spoof scenarios, but the performance is largely restricted by the single-modal input. This paper focuses on this issue and presents a multi-modal disentanglement model which targetedly learns polysemantic spoof traces for more accurate and robust generic attack detection. In particular, based on the adversarial learning mechanism, a two-stream disentangling network is designed to estimate spoof patterns from the RGB and depth inputs, respectively. In this case, it captures complementary spoofing clues inhering in different attacks. Furthermore, a fusion module is exploited, which recalibrates both representations at multiple stages to promote the disentanglement in each individual modality. It then performs cross-modality aggregation to deliver a more comprehensive spoof trace representation for prediction. Extensive evaluations are conducted on multiple benchmarks, demonstrating that learning polysemantic spoof traces favorably contributes to anti-spoofing with more perceptible and interpretable results.
Dense Learning based Semi-Supervised Object Detection
Apr 15, 2022
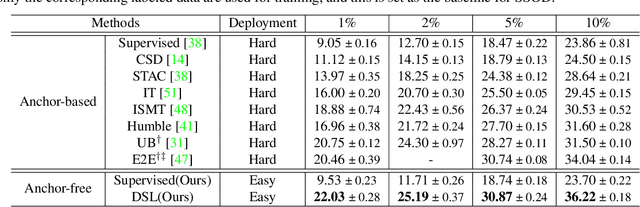

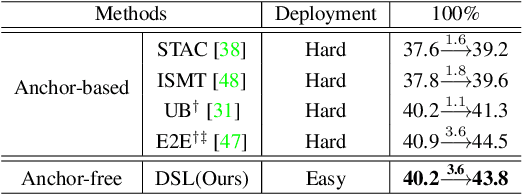
Semi-supervised object detection (SSOD) aims to facilitate the training and deployment of object detectors with the help of a large amount of unlabeled data. Though various self-training based and consistency-regularization based SSOD methods have been proposed, most of them are anchor-based detectors, ignoring the fact that in many real-world applications anchor-free detectors are more demanded. In this paper, we intend to bridge this gap and propose a DenSe Learning (DSL) based anchor-free SSOD algorithm. Specifically, we achieve this goal by introducing several novel techniques, including an Adaptive Filtering strategy for assigning multi-level and accurate dense pixel-wise pseudo-labels, an Aggregated Teacher for producing stable and precise pseudo-labels, and an uncertainty-consistency-regularization term among scales and shuffled patches for improving the generalization capability of the detector. Extensive experiments are conducted on MS-COCO and PASCAL-VOC, and the results show that our proposed DSL method records new state-of-the-art SSOD performance, surpassing existing methods by a large margin. Codes can be found at \textcolor{blue}{https://github.com/chenbinghui1/DSL}.