 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Jun 28, 2024
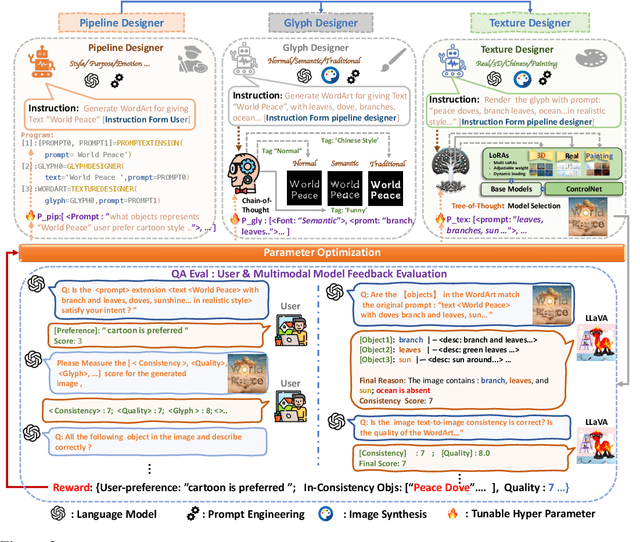
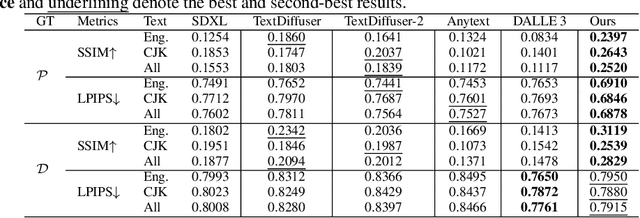
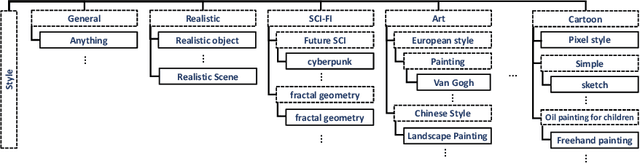
MetaDesigner revolutionizes artistic typography synthesis by leveraging the strengths of Large Language Models (LLMs) to drive a design paradigm centered around user engagement. At the core of this framework lies a multi-agent system comprising the Pipeline, Glyph, and Texture agents, which collectively enable the creation of customized WordArt, ranging from semantic enhancements to the imposition of complex textures. MetaDesigner incorporates a comprehensive feedback mechanism that harnesses insights from multimodal models and user evaluations to refine and enhance the design process iteratively. Through this feedback loop, the system adeptly tunes hyperparameters to align with user-defined stylistic and thematic preferences, generating WordArt that not only meets but exceeds user expectations of visual appeal and contextual relevance. Empirical validations highlight MetaDesigner's capability to effectively serve diverse WordArt applications, consistently producing aesthetically appealing and context-sensitive results.
VirtualModel: Generating Object-ID-retentive Human-object Interaction Image by Diffusion Model for E-commerce Marketing
May 16, 2024Due to the significant advances in large-scale text-to-image generation by diffusion model (DM), controllable human image generation has been attracting much attention recently. Existing works, such as Controlnet [36], T2I-adapter [20] and HumanSD [10] have demonstrated good abilities in generating human images based on pose conditions, they still fail to meet the requirements of real e-commerce scenarios. These include (1) the interaction between the shown product and human should be considered, (2) human parts like face/hand/arm/foot and the interaction between human model and product should be hyper-realistic, and (3) the identity of the product shown in advertising should be exactly consistent with the product itself. To this end, in this paper, we first define a new human image generation task for e-commerce marketing, i.e., Object-ID-retentive Human-object Interaction image Generation (OHG), and then propose a VirtualModel framework to generate human images for product shown, which supports displays of any categories of products and any types of human-object interaction. As shown in Figure 1, VirtualModel not only outperforms other methods in terms of accurate pose control and image quality but also allows for the display of user-specified product objects by maintaining the product-ID consistency and enhancing the plausibility of human-object interaction. Codes and data will be released.
DyRoNet: A Low-Rank Adapter Enhanced Dynamic Routing Network for Streaming Perception
Mar 15, 2024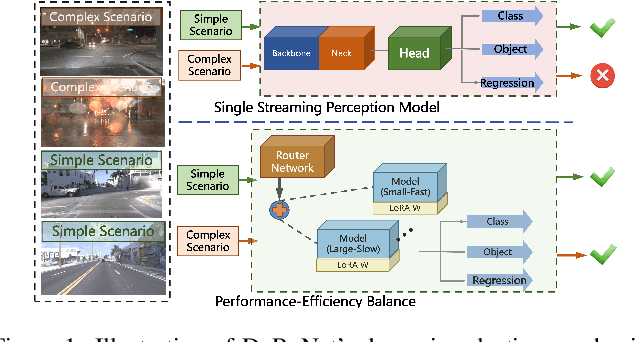
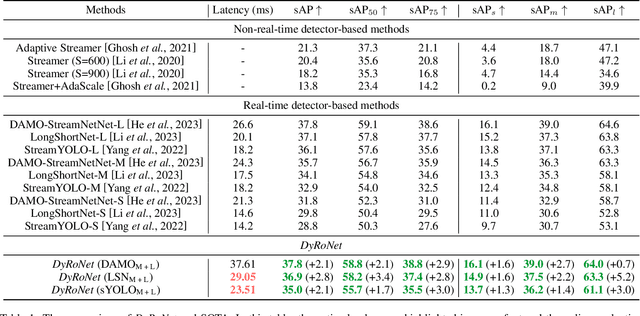
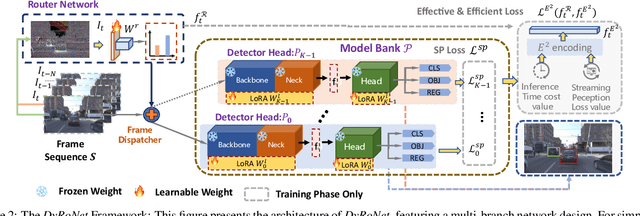
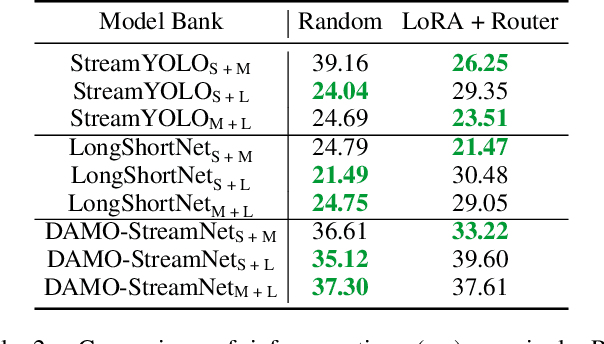
The quest for real-time, accurate environmental perception is pivotal in the evolution of autonomous driving technologies. In response to this challenge, we present DyRoNet, a Dynamic Router Network that innovates by incorporating low-rank dynamic routing to enhance streaming perception. DyRoNet distinguishes itself by seamlessly integrating a diverse array of specialized pre-trained branch networks, each meticulously fine-tuned for specific environmental contingencies, thus facilitating an optimal balance between response latency and detection precision. Central to DyRoNet's architecture is the Speed Router module, which employs an intelligent routing mechanism to dynamically allocate input data to the most suitable branch network, thereby ensuring enhanced performance adaptability in real-time scenarios. Through comprehensive evaluations, DyRoNet demonstrates superior adaptability and significantly improved performance over existing methods, efficiently catering to a wide variety of environmental conditions and setting new benchmarks in streaming perception accuracy and efficiency. Beyond establishing a paradigm in autonomous driving perception, DyRoNet also offers engineering insights and lays a foundational framework for future advancements in streaming perception. For further information and updates on the project, visit https://tastevision.github.io/DyRoNet/.
WordArt Designer API: User-Driven Artistic Typography Synthesis with Large Language Models on ModelScope
Jan 12, 2024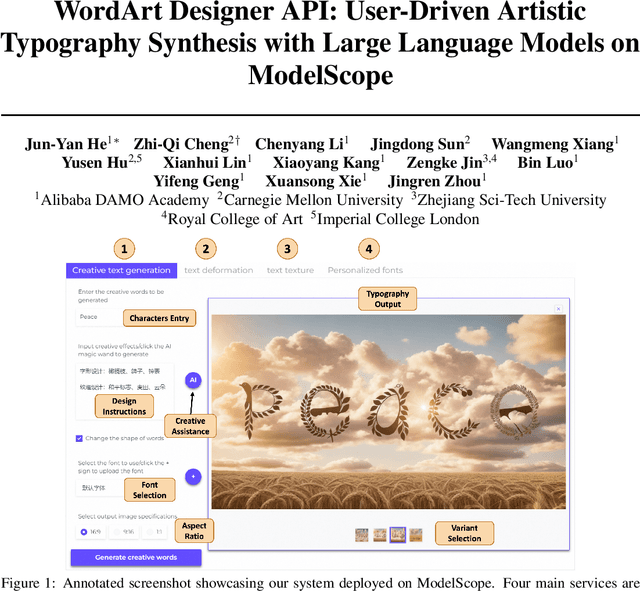


This paper introduces the WordArt Designer API, a novel framework for user-driven artistic typography synthesis utilizing Large Language Models (LLMs) on ModelScope. We address the challenge of simplifying artistic typography for non-professionals by offering a dynamic, adaptive, and computationally efficient alternative to traditional rigid templates. Our approach leverages the power of LLMs to understand and interpret user input, facilitating a more intuitive design process. We demonstrate through various case studies how users can articulate their aesthetic preferences and functional requirements, which the system then translates into unique and creative typographic designs. Our evaluations indicate significant improvements in user satisfaction, design flexibility, and creative expression over existing systems. The WordArt Designer API not only democratizes the art of typography but also opens up new possibilities for personalized digital communication and design.
AnyText: Multilingual Visual Text Generation And Editing
Nov 07, 2023



Diffusion model based Text-to-Image has achieved impressive achievements recently. Although current technology for synthesizing images is highly advanced and capable of generating images with high fidelity, it is still possible to give the show away when focusing on the text area in the generated image. To address this issue, we introduce AnyText, a diffusion-based multilingual visual text generation and editing model, that focuses on rendering accurate and coherent text in the image. AnyText comprises a diffusion pipeline with two primary elements: an auxiliary latent module and a text embedding module. The former uses inputs like text glyph, position, and masked image to generate latent features for text generation or editing. The latter employs an OCR model for encoding stroke data as embeddings, which blend with image caption embeddings from the tokenizer to generate texts that seamlessly integrate with the background. We employed text-control diffusion loss and text perceptual loss for training to further enhance writing accuracy. AnyText can write characters in multiple languages, to the best of our knowledge, this is the first work to address multilingual visual text generation. It is worth mentioning that AnyText can be plugged into existing diffusion models from the community for rendering or editing text accurately. After conducting extensive evaluation experiments, our method has outperformed all other approaches by a significant margin. Additionally, we contribute the first large-scale multilingual text images dataset, AnyWord-3M, containing 3 million image-text pairs with OCR annotations in multiple languages. Based on AnyWord-3M dataset, we propose AnyText-benchmark for the evaluation of visual text generation accuracy and quality. Our project will be open-sourced on https://github.com/tyxsspa/AnyText to improve and promote the development of text generation technology.
WordArt Designer: User-Driven Artistic Typography Synthesis using Large Language Models
Oct 20, 2023



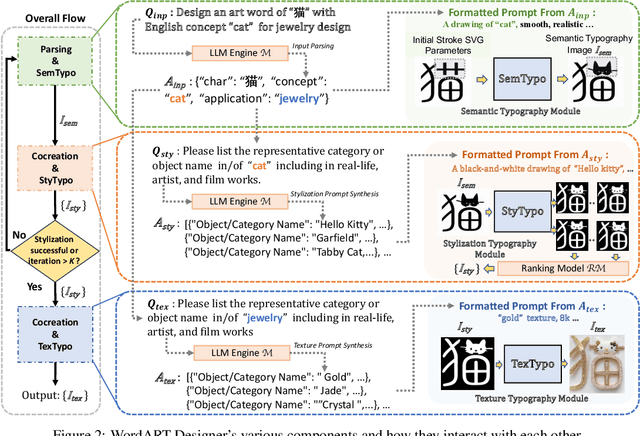
This paper introduces "WordArt Designer", a user-driven framework for artistic typography synthesis, relying on Large Language Models (LLM). The system incorporates four key modules: the "LLM Engine", "SemTypo", "StyTypo", and "TexTypo" modules. 1) The "LLM Engine", empowered by LLM (e.g., GPT-3.5-turbo), interprets user inputs and generates actionable prompts for the other modules, thereby transforming abstract concepts into tangible designs. 2) The "SemTypo module" optimizes font designs using semantic concepts, striking a balance between artistic transformation and readability. 3) Building on the semantic layout provided by the "SemTypo module", the "StyTypo module" creates smooth, refined images. 4) The "TexTypo module" further enhances the design's aesthetics through texture rendering, enabling the generation of inventive textured fonts. Notably, "WordArt Designer" highlights the fusion of generative AI with artistic typography. Experience its capabilities on ModelScope: https://www.modelscope.cn/studios/WordArt/WordArt.
Refined Temporal Pyramidal Compression-and-Amplification Transformer for 3D Human Pose Estimation
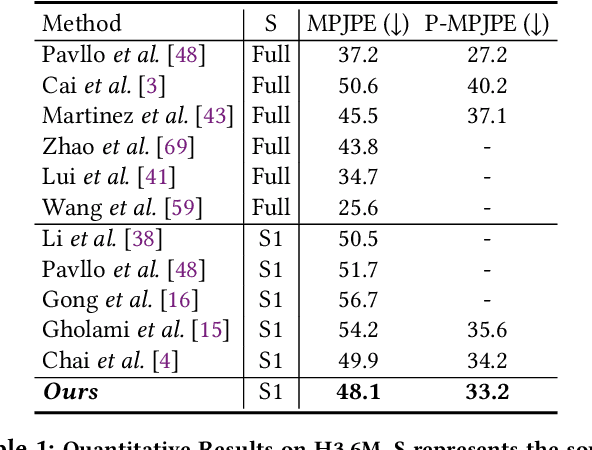
Sep 06, 2023Accurately estimating the 3D pose of humans in video sequences requires both accuracy and a well-structured architecture. With the success of transformers, we introduce the Refined Temporal Pyramidal Compression-and-Amplification (RTPCA) transformer. Exploiting the temporal dimension, RTPCA extends intra-block temporal modeling via its Temporal Pyramidal Compression-and-Amplification (TPCA) structure and refines inter-block feature interaction with a Cross-Layer Refinement (XLR) module. In particular, TPCA block exploits a temporal pyramid paradigm, reinforcing key and value representation capabilities and seamlessly extracting spatial semantics from motion sequences. We stitch these TPCA blocks with XLR that promotes rich semantic representation through continuous interaction of queries, keys, and values. This strategy embodies early-stage information with current flows, addressing typical deficits in detail and stability seen in other transformer-based methods. We demonstrate the effectiveness of RTPCA by achieving state-of-the-art results on Human3.6M, HumanEva-I, and MPI-INF-3DHP benchmarks with minimal computational overhead. The source code is available at https://github.com/hbing-l/RTPCA.
PoSynDA: Multi-Hypothesis Pose Synthesis Domain Adaptation for Robust 3D Human Pose Estimation
Aug 18, 2023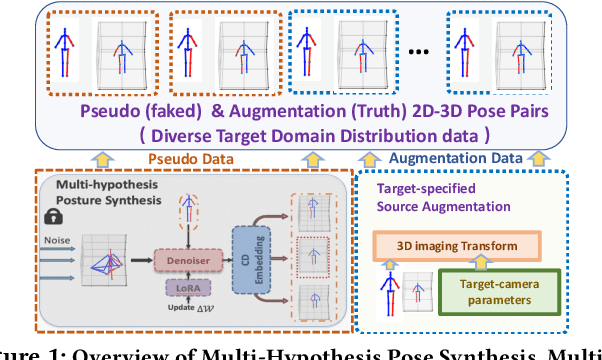
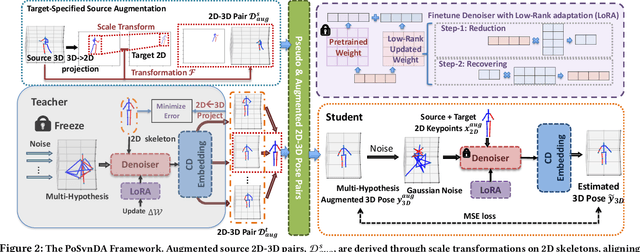
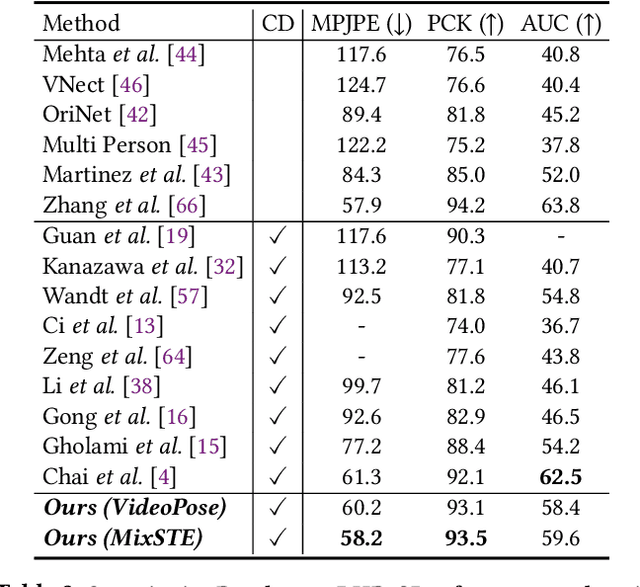
The current 3D human pose estimators face challenges in adapting to new datasets due to the scarcity of 2D-3D pose pairs in target domain training sets. We present the \textit{Multi-Hypothesis \textbf{P}ose \textbf{Syn}thesis \textbf{D}omain \textbf{A}daptation} (\textbf{PoSynDA}) framework to overcome this issue without extensive target domain annotation. Utilizing a diffusion-centric structure, PoSynDA simulates the 3D pose distribution in the target domain, filling the data diversity gap. By incorporating a multi-hypothesis network, it creates diverse pose hypotheses and aligns them with the target domain. Target-specific source augmentation obtains the target domain distribution data from the source domain by decoupling the scale and position parameters. The teacher-student paradigm and low-rank adaptation further refine the process. PoSynDA demonstrates competitive performance on benchmarks, such as Human3.6M, MPI-INF-3DHP, and 3DPW, even comparable with the target-trained MixSTE model~\cite{zhang2022mixste}. This work paves the way for the practical application of 3D human pose estimation. The code is available at https://github.com/hbing-l/PoSynDA.
A Benchmark for Chinese-English Scene Text Image Super-resolution
Aug 07, 2023

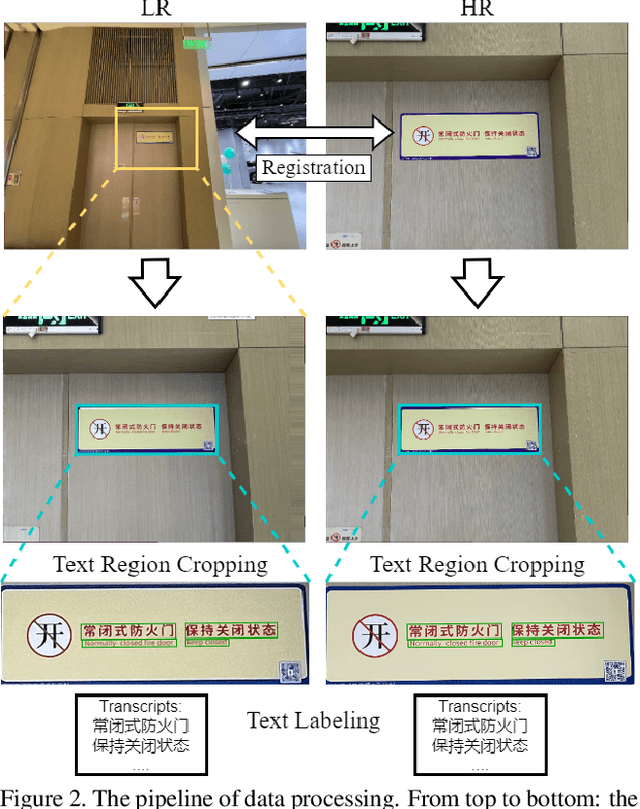

Scene Text Image Super-resolution (STISR) aims to recover high-resolution (HR) scene text images with visually pleasant and readable text content from the given low-resolution (LR) input. Most existing works focus on recovering English texts, which have relatively simple character structures, while little work has been done on the more challenging Chinese texts with diverse and complex character structures. In this paper, we propose a real-world Chinese-English benchmark dataset, namely Real-CE, for the task of STISR with the emphasis on restoring structurally complex Chinese characters. The benchmark provides 1,935/783 real-world LR-HR text image pairs~(contains 33,789 text lines in total) for training/testing in 2$\times$ and 4$\times$ zooming modes, complemented by detailed annotations, including detection boxes and text transcripts. Moreover, we design an edge-aware learning method, which provides structural supervision in image and feature domains, to effectively reconstruct the dense structures of Chinese characters. We conduct experiments on the proposed Real-CE benchmark and evaluate the existing STISR models with and without our edge-aware loss. The benchmark, including data and source code, is available at https://github.com/mjq11302010044/Real-CE.
KeyPosS: Plug-and-Play Facial Landmark Detection through GPS-Inspired True-Range Multilateration
May 25, 2023



In the realm of facial analysis, accurate landmark detection is crucial for various applications, ranging from face recognition and expression analysis to animation. Conventional heatmap or coordinate regression-based techniques, however, often face challenges in terms of computational burden and quantization errors. To address these issues, we present the KeyPoint Positioning System (KeyPosS), a groundbreaking facial landmark detection framework that stands out from existing methods. For the first time, KeyPosS employs the True-range Multilateration algorithm, a technique originally used in GPS systems, to achieve rapid and precise facial landmark detection without relying on computationally intensive regression approaches. The framework utilizes a fully convolutional network to predict a distance map, which computes the distance between a Point of Interest (POI) and multiple anchor points. These anchor points are ingeniously harnessed to triangulate the POI's position through the True-range Multilateration algorithm. Notably, the plug-and-play nature of KeyPosS enables seamless integration into any decoding stage, ensuring a versatile and adaptable solution. We conducted a thorough evaluation of KeyPosS's performance by benchmarking it against state-of-the-art models on four different datasets. The results show that KeyPosS substantially outperforms leading methods in low-resolution settings while requiring a minimal time overhead. The code is available at https://github.com/zhiqic/KeyPosS.