 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeHC-RL: Temporal-aware Hierarchical Cognitive Reinforcement Learning for Enhancing LLMs' Social Intelligence
May 30, 2025Recently, Large Language Models (LLMs) have made significant progress in IQ-related domains that require careful thinking, such as mathematics and coding. However, enhancing LLMs' cognitive development in social domains, particularly from a post-training perspective, remains underexplored. Recognizing that the social world follows a distinct timeline and requires a richer blend of cognitive modes (from intuitive reactions (System 1) and surface-level thinking to deliberate thinking (System 2)) than mathematics, which primarily relies on System 2 cognition (careful, step-by-step reasoning), we introduce Temporal-aware Hierarchical Cognitive Reinforcement Learning (TimeHC-RL) for enhancing LLMs' social intelligence. In our experiments, we systematically explore improving LLMs' social intelligence and validate the effectiveness of the TimeHC-RL method, through five other post-training paradigms and two test-time intervention paradigms on eight datasets with diverse data patterns. Experimental results reveal the superiority of our proposed TimeHC-RL method compared to the widely adopted System 2 RL method. It gives the 7B backbone model wings, enabling it to rival the performance of advanced models like DeepSeek-R1 and OpenAI-O3. Additionally, the systematic exploration from post-training and test-time interventions perspectives to improve LLMs' social intelligence has uncovered several valuable insights.
ChARM: Character-based Act-adaptive Reward Modeling for Advanced Role-Playing Language Agents
May 29, 2025
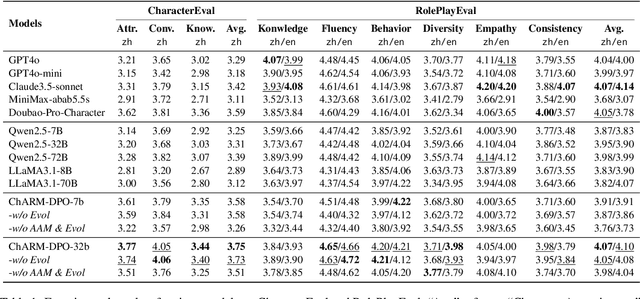
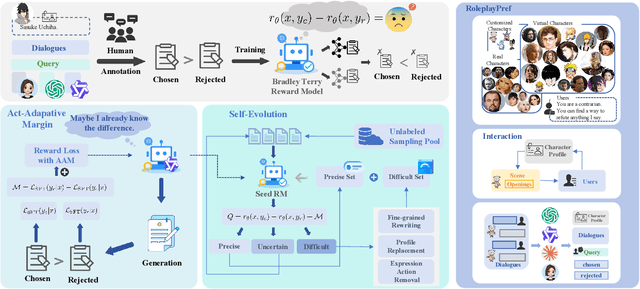
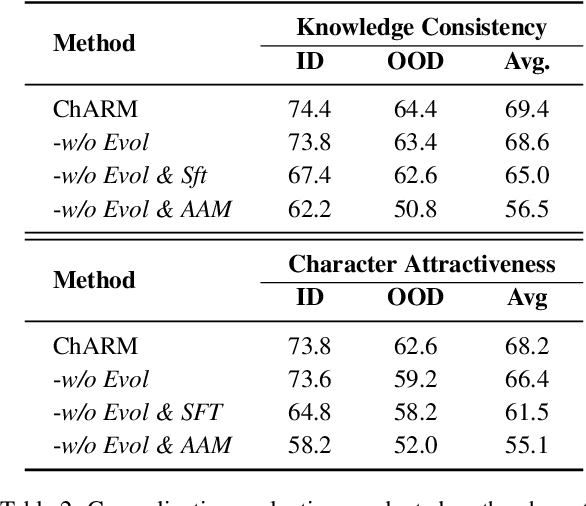
Role-Playing Language Agents (RPLAs) aim to simulate characters for realistic and engaging human-computer interactions. However, traditional reward models often struggle with scalability and adapting to subjective conversational preferences. We propose ChARM, a Character-based Act-adaptive Reward Model, addressing these challenges through two innovations: (1) an act-adaptive margin that significantly enhances learning efficiency and generalizability, and (2) a self-evolution mechanism leveraging large-scale unlabeled data to improve training coverage. Additionally, we introduce RoleplayPref, the first large-scale preference dataset specifically for RPLAs, featuring 1,108 characters, 13 subcategories, and 16,888 bilingual dialogues, alongside RoleplayEval, a dedicated evaluation benchmark. Experimental results show a 13% improvement over the conventional Bradley-Terry model in preference rankings. Furthermore, applying ChARM-generated rewards to preference learning techniques (e.g., direct preference optimization) achieves state-of-the-art results on CharacterEval and RoleplayEval. Code and dataset are available at https://github.com/calubkk/ChARM.
Reverse Preference Optimization for Complex Instruction Following
May 28, 2025Instruction following (IF) is a critical capability for large language models (LLMs). However, handling complex instructions with multiple constraints remains challenging. Previous methods typically select preference pairs based on the number of constraints they satisfy, introducing noise where chosen examples may fail to follow some constraints and rejected examples may excel in certain respects over the chosen ones. To address the challenge of aligning with multiple preferences, we propose a simple yet effective method called Reverse Preference Optimization (RPO). It mitigates noise in preference pairs by dynamically reversing the constraints within the instruction to ensure the chosen response is perfect, alleviating the burden of extensive sampling and filtering to collect perfect responses. Besides, reversal also enlarges the gap between chosen and rejected responses, thereby clarifying the optimization direction and making it more robust to noise. We evaluate RPO on two multi-turn IF benchmarks, Sysbench and Multi-IF, demonstrating average improvements over the DPO baseline of 4.6 and 2.5 points (on Llama-3.1 8B), respectively. Moreover, RPO scales effectively across model sizes (8B to 70B parameters), with the 70B RPO model surpassing GPT-4o.
Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning
May 07, 2025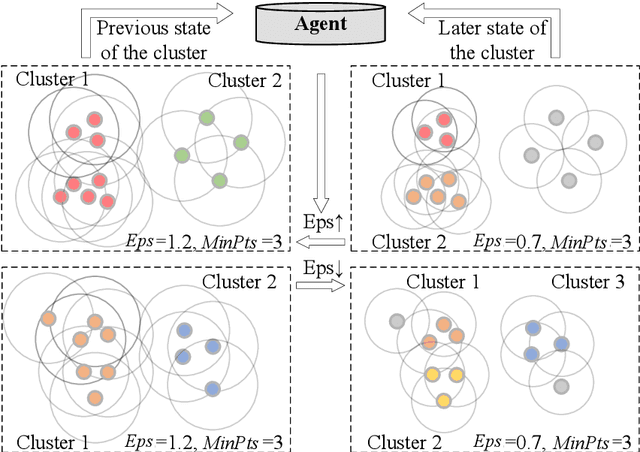

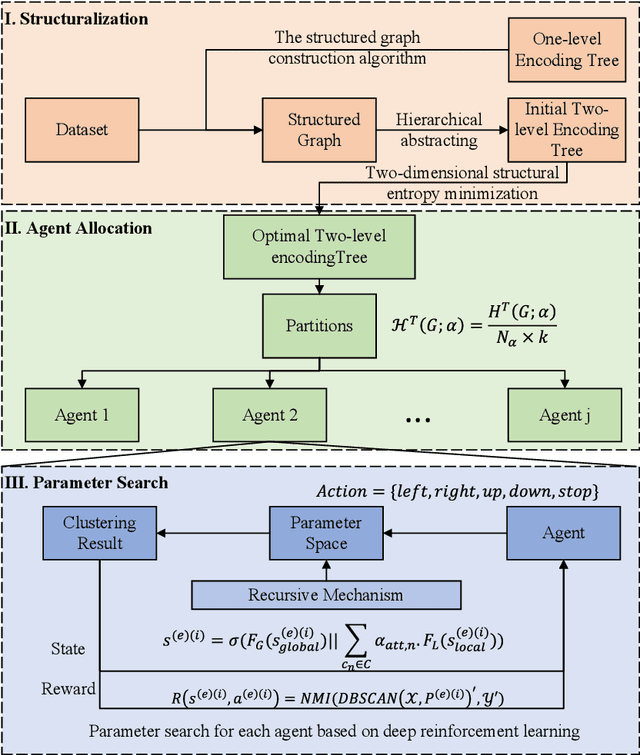

DBSCAN, a well-known density-based clustering algorithm, has gained widespread popularity and usage due to its effectiveness in identifying clusters of arbitrary shapes and handling noisy data. However, it encounters challenges in producing satisfactory cluster results when confronted with datasets of varying density scales, a common scenario in real-world applications. In this paper, we propose a novel Adaptive and Robust DBSCAN with Multi-agent Reinforcement Learning cluster framework, namely AR-DBSCAN. First, we model the initial dataset as a two-level encoding tree and categorize the data vertices into distinct density partitions according to the information uncertainty determined in the encoding tree. Each partition is then assigned to an agent to find the best clustering parameters without manual assistance. The allocation is density-adaptive, enabling AR-DBSCAN to effectively handle diverse density distributions within the dataset by utilizing distinct agents for different partitions. Second, a multi-agent deep reinforcement learning guided automatic parameter searching process is designed. The process of adjusting the parameter search direction by perceiving the clustering environment is modeled as a Markov decision process. Using a weakly-supervised reward training policy network, each agent adaptively learns the optimal clustering parameters by interacting with the clusters. Third, a recursive search mechanism adaptable to the data's scale is presented, enabling efficient and controlled exploration of large parameter spaces. Extensive experiments are conducted on nine artificial datasets and a real-world dataset. The results of offline and online tasks show that AR-DBSCAN not only improves clustering accuracy by up to 144.1% and 175.3% in the NMI and ARI metrics, respectively, but also is capable of robustly finding dominant parameters.
Multi-View Attention Syntactic Enhanced Graph Convolutional Network for Aspect-based Sentiment Analysis
Jan 27, 2025



Aspect-based Sentiment Analysis (ABSA) is the task aimed at predicting the sentiment polarity of aspect words within sentences. Recently, incorporating graph neural networks (GNNs) to capture additional syntactic structure information in the dependency tree derived from syntactic dependency parsing has been proven to be an effective paradigm for boosting ABSA. Despite GNNs enhancing model capability by fusing more types of information, most works only utilize a single topology view of the dependency tree or simply conflate different perspectives of information without distinction, which limits the model performance. To address these challenges, in this paper, we propose a new multi-view attention syntactic enhanced graph convolutional network (MASGCN) that weighs different syntactic information of views using attention mechanisms. Specifically, we first construct distance mask matrices from the dependency tree to obtain multiple subgraph views for GNNs. To aggregate features from different views, we propose a multi-view attention mechanism to calculate the attention weights of views. Furthermore, to incorporate more syntactic information, we fuse the dependency type information matrix into the adjacency matrices and present a structural entropy loss to learn the dependency type adjacency matrix. Comprehensive experiments on four benchmark datasets demonstrate that our model outperforms state-of-the-art methods. The codes and datasets are available at https://github.com/SELGroup/MASGCN.
TARGA: Targeted Synthetic Data Generation for Practical Reasoning over Structured Data
Dec 27, 2024



Semantic parsing, which converts natural language questions into logic forms, plays a crucial role in reasoning within structured environments. However, existing methods encounter two significant challenges: reliance on extensive manually annotated datasets and limited generalization capability to unseen examples. To tackle these issues, we propose Targeted Synthetic Data Generation (TARGA), a practical framework that dynamically generates high-relevance synthetic data without manual annotation. Starting from the pertinent entities and relations of a given question, we probe for the potential relevant queries through layer-wise expansion and cross-layer combination. Then we generate corresponding natural language questions for these constructed queries to jointly serve as the synthetic demonstrations for in-context learning. Experiments on multiple knowledge base question answering (KBQA) datasets demonstrate that TARGA, using only a 7B-parameter model, substantially outperforms existing non-fine-tuned methods that utilize close-sourced model, achieving notable improvements in F1 scores on GrailQA(+7.7) and KBQA-Agent(+12.2). Furthermore, TARGA also exhibits superior sample efficiency, robustness, and generalization capabilities under non-I.I.D. settings.
Structural Entropy Guided Probabilistic Coding
Dec 12, 2024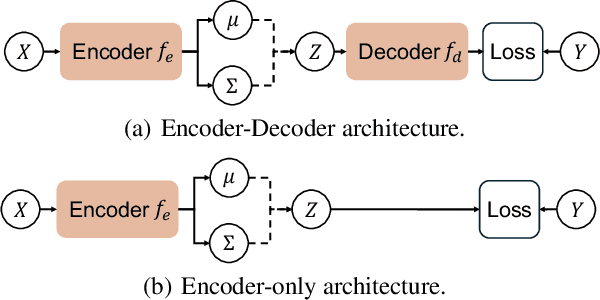



Probabilistic embeddings have several advantages over deterministic embeddings as they map each data point to a distribution, which better describes the uncertainty and complexity of data. Many works focus on adjusting the distribution constraint under the Information Bottleneck (IB) principle to enhance representation learning. However, these proposed regularization terms only consider the constraint of each latent variable, omitting the structural information between latent variables. In this paper, we propose a novel structural entropy-guided probabilistic coding model, named SEPC. Specifically, we incorporate the relationship between latent variables into the optimization by proposing a structural entropy regularization loss. Besides, as traditional structural information theory is not well-suited for regression tasks, we propose a probabilistic encoding tree, transferring regression tasks to classification tasks while diminishing the influence of the transformation. Experimental results across 12 natural language understanding tasks, including both classification and regression tasks, demonstrate the superior performance of SEPC compared to other state-of-the-art models in terms of effectiveness, generalization capability, and robustness to label noise. The codes and datasets are available at https://github.com/SELGroup/SEPC.
Windowed Dictionary Design for Delay-Aware OMP Channel Estimation under Fractional Doppler
Dec 02, 2024Delay-Doppler (DD) signal processing has emerged as a powerful tool for analyzing multipath and time-varying channel effects. Due to the inherent sparsity of the wireless channel in the DD domain, compressed sensing (CS) based techniques, such as orthogonal matching pursuit (OMP), are commonly used for channel estimation. However, many of these methods assume integer Doppler shifts, which can lead to performance degradation in the presence of fractional Doppler. In this paper, we propose a windowed dictionary design technique while we develop a delay-aware orthogonal matching pursuit (DA-OMP) algorithm that mitigates the impact of fractional Doppler shifts on DD domain channel estimation. First, we apply receiver windowing to reduce the correlation between the columns of our proposed dictionary matrix. Second, we introduce a delay-aware interference block to quantify the interference caused by fractional Doppler. This approach removes the need for a pre-determined stopping criterion, which is typically based on the number of propagation paths, in conventional OMP algorithm. Our simulation results confirm the effective performance of our proposed DA-OMP algorithm using the proposed windowed dictionary in terms of normalized mean square error (NMSE) of the channel estimate. In particular, our proposed DA-OMP algorithm demonstrates substantial gains compared to standard OMP algorithm in terms of channel estimation NMSE with and without windowed dictionary.
Solving Integrated Process Planning and Scheduling Problem via Graph Neural Network Based Deep Reinforcement Learning
Sep 02, 2024The Integrated Process Planning and Scheduling (IPPS) problem combines process route planning and shop scheduling to achieve high efficiency in manufacturing and maximize resource utilization, which is crucial for modern manufacturing systems. Traditional methods using Mixed Integer Linear Programming (MILP) and heuristic algorithms can not well balance solution quality and speed when solving IPPS. In this paper, we propose a novel end-to-end Deep Reinforcement Learning (DRL) method. We model the IPPS problem as a Markov Decision Process (MDP) and employ a Heterogeneous Graph Neural Network (GNN) to capture the complex relationships among operations, machines, and jobs. To optimize the scheduling strategy, we use Proximal Policy Optimization (PPO). Experimental results show that, compared to traditional methods, our approach significantly improves solution efficiency and quality in large-scale IPPS instances, providing superior scheduling strategies for modern intelligent manufacturing systems.
QueryAgent: A Reliable and Efficient Reasoning Framework with Environmental Feedback based Self-Correction
Mar 18, 2024



Employing Large Language Models (LLMs) for semantic parsing has achieved remarkable success. However, we find existing methods fall short in terms of reliability and efficiency when hallucinations are encountered. In this paper, we address these challenges with a framework called QueryAgent, which solves a question step-by-step and performs step-wise self-correction. We introduce an environmental feedback-based self-correction method called ERASER. Unlike traditional approaches, ERASER leverages rich environmental feedback in the intermediate steps to perform selective and differentiated self-correction only when necessary. Experimental results demonstrate that QueryAgent notably outperforms all previous few-shot methods using only one example on GrailQA and GraphQ by 7.0 and 15.0 F1. Moreover, our approach exhibits superiority in terms of efficiency, including runtime, query overhead, and API invocation costs. By leveraging ERASER, we further improve another baseline (i.e., AgentBench) by approximately 10 points, revealing the strong transferability of our approach.