 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgD: Progressive Multi-scale Decoding with Dynamic Graphs for Joint Multi-agent Motion Forecasting
Sep 11, 2025Accurate motion prediction of surrounding agents is crucial for the safe planning of autonomous vehicles. Recent advancements have extended prediction techniques from individual agents to joint predictions of multiple interacting agents, with various strategies to address complex interactions within future motions of agents. However, these methods overlook the evolving nature of these interactions. To address this limitation, we propose a novel progressive multi-scale decoding strategy, termed ProgD, with the help of dynamic heterogeneous graph-based scenario modeling. In particular, to explicitly and comprehensively capture the evolving social interactions in future scenarios, given their inherent uncertainty, we design a progressive modeling of scenarios with dynamic heterogeneous graphs. With the unfolding of such dynamic heterogeneous graphs, a factorized architecture is designed to process the spatio-temporal dependencies within future scenarios and progressively eliminate uncertainty in future motions of multiple agents. Furthermore, a multi-scale decoding procedure is incorporated to improve on the future scenario modeling and consistent prediction of agents' future motion. The proposed ProgD achieves state-of-the-art performance on the INTERACTION multi-agent prediction benchmark, ranking $1^{st}$, and the Argoverse 2 multi-world forecasting benchmark.
LogitSpec: Accelerating Retrieval-based Speculative Decoding via Next Next Token Speculation
Jul 02, 2025Speculative decoding (SD), where a small draft model is employed to propose draft tokens in advance and then the target model validates them in parallel, has emerged as a promising technique for LLM inference acceleration. Many endeavors to improve SD are to eliminate the need for a draft model and generate draft tokens in a retrieval-based manner in order to further alleviate the drafting overhead and significantly reduce the difficulty in deployment and applications. However, retrieval-based SD relies on a matching paradigm to retrieval the most relevant reference as the draft tokens, where these methods often fail to find matched and accurate draft tokens. To address this challenge, we propose LogitSpec to effectively expand the retrieval range and find the most relevant reference as drafts. Our LogitSpec is motivated by the observation that the logit of the last token can not only predict the next token, but also speculate the next next token. Specifically, LogitSpec generates draft tokens in two steps: (1) utilizing the last logit to speculate the next next token; (2) retrieving relevant reference for both the next token and the next next token. LogitSpec is training-free and plug-and-play, which can be easily integrated into existing LLM inference frameworks. Extensive experiments on a wide range of text generation benchmarks demonstrate that LogitSpec can achieve up to 2.61 $\times$ speedup and 3.28 mean accepted tokens per decoding step. Our code is available at https://github.com/smart-lty/LogitSpec.
TimeHC-RL: Temporal-aware Hierarchical Cognitive Reinforcement Learning for Enhancing LLMs' Social Intelligence
May 30, 2025Recently, Large Language Models (LLMs) have made significant progress in IQ-related domains that require careful thinking, such as mathematics and coding. However, enhancing LLMs' cognitive development in social domains, particularly from a post-training perspective, remains underexplored. Recognizing that the social world follows a distinct timeline and requires a richer blend of cognitive modes (from intuitive reactions (System 1) and surface-level thinking to deliberate thinking (System 2)) than mathematics, which primarily relies on System 2 cognition (careful, step-by-step reasoning), we introduce Temporal-aware Hierarchical Cognitive Reinforcement Learning (TimeHC-RL) for enhancing LLMs' social intelligence. In our experiments, we systematically explore improving LLMs' social intelligence and validate the effectiveness of the TimeHC-RL method, through five other post-training paradigms and two test-time intervention paradigms on eight datasets with diverse data patterns. Experimental results reveal the superiority of our proposed TimeHC-RL method compared to the widely adopted System 2 RL method. It gives the 7B backbone model wings, enabling it to rival the performance of advanced models like DeepSeek-R1 and OpenAI-O3. Additionally, the systematic exploration from post-training and test-time interventions perspectives to improve LLMs' social intelligence has uncovered several valuable insights.
O$^2$-Searcher: A Searching-based Agent Model for Open-Domain Open-Ended Question Answering
May 22, 2025

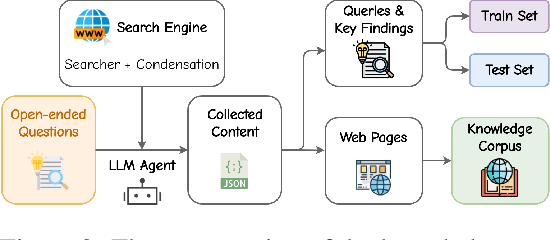

Large Language Models (LLMs), despite their advancements, are fundamentally limited by their static parametric knowledge, hindering performance on tasks requiring open-domain up-to-date information. While enabling LLMs to interact with external knowledge environments is a promising solution, current efforts primarily address closed-end problems. Open-ended questions, which characterized by lacking a standard answer or providing non-unique and diverse answers, remain underexplored. To bridge this gap, we present O$^2$-Searcher, a novel search agent leveraging reinforcement learning to effectively tackle both open-ended and closed-ended questions in the open domain. O$^2$-Searcher leverages an efficient, locally simulated search environment for dynamic knowledge acquisition, effectively decoupling the external world knowledge from model's sophisticated reasoning processes. It employs a unified training mechanism with meticulously designed reward functions, enabling the agent to identify problem types and adapt different answer generation strategies. Furthermore, to evaluate performance on complex open-ended tasks, we construct O$^2$-QA, a high-quality benchmark featuring 300 manually curated, multi-domain open-ended questions with associated web page caches. Extensive experiments show that O$^2$-Searcher, using only a 3B model, significantly surpasses leading LLM agents on O$^2$-QA. It also achieves SOTA results on various closed-ended QA benchmarks against similarly-sized models, while performing on par with much larger ones.
Improving Unsupervised Task-driven Models of Ventral Visual Stream via Relative Position Predictivity
May 13, 2025Based on the concept that ventral visual stream (VVS) mainly functions for object recognition, current unsupervised task-driven methods model VVS by contrastive learning, and have achieved good brain similarity. However, we believe functions of VVS extend beyond just object recognition. In this paper, we introduce an additional function involving VVS, named relative position (RP) prediction. We first theoretically explain contrastive learning may be unable to yield the model capability of RP prediction. Motivated by this, we subsequently integrate RP learning with contrastive learning, and propose a new unsupervised task-driven method to model VVS, which is more inline with biological reality. We conduct extensive experiments, demonstrating that: (i) our method significantly improves downstream performance of object recognition while enhancing RP predictivity; (ii) RP predictivity generally improves the model brain similarity. Our results provide strong evidence for the involvement of VVS in location perception (especially RP prediction) from a computational perspective.
Learning-Augmented Algorithms for Boolean Satisfiability
May 09, 2025Learning-augmented algorithms are a prominent recent development in beyond worst-case analysis. In this framework, a problem instance is provided with a prediction (``advice'') from a machine-learning oracle, which provides partial information about an optimal solution, and the goal is to design algorithms that leverage this advice to improve worst-case performance. We study the classic Boolean satisfiability (SAT) decision and optimization problems within this framework using two forms of advice. ``Subset advice" provides a random $\epsilon$ fraction of the variables from an optimal assignment, whereas ``label advice" provides noisy predictions for all variables in an optimal assignment. For the decision problem $k$-SAT, by using the subset advice we accelerate the exponential running time of the PPSZ family of algorithms due to Paturi, Pudlak, Saks and Zane, which currently represent the state of the art in the worst case. We accelerate the running time by a multiplicative factor of $2^{-c}$ in the base of the exponent, where $c$ is a function of $\epsilon$ and $k$. For the optimization problem, we show how to incorporate subset advice in a black-box fashion with any $\alpha$-approximation algorithm, improving the approximation ratio to $\alpha + (1 - \alpha)\epsilon$. Specifically, we achieve approximations of $0.94 + \Omega(\epsilon)$ for MAX-$2$-SAT, $7/8 + \Omega(\epsilon)$ for MAX-$3$-SAT, and $0.79 + \Omega(\epsilon)$ for MAX-SAT. Moreover, for label advice, we obtain near-optimal approximation for instances with large average degree, thereby generalizing recent results on MAX-CUT and MAX-$2$-LIN.
Safety-Critical Traffic Simulation with Adversarial Transfer of Driving Intentions
Mar 07, 2025Traffic simulation, complementing real-world data with a long-tail distribution, allows for effective evaluation and enhancement of the ability of autonomous vehicles to handle accident-prone scenarios. Simulating such safety-critical scenarios is nontrivial, however, from log data that are typically regular scenarios, especially in consideration of dynamic adversarial interactions between the future motions of autonomous vehicles and surrounding traffic participants. To address it, this paper proposes an innovative and efficient strategy, termed IntSim, that explicitly decouples the driving intentions of surrounding actors from their motion planning for realistic and efficient safety-critical simulation. We formulate the adversarial transfer of driving intention as an optimization problem, facilitating extensive exploration of diverse attack behaviors and efficient solution convergence. Simultaneously, intention-conditioned motion planning benefits from powerful deep models and large-scale real-world data, permitting the simulation of realistic motion behaviors for actors. Specially, through adapting driving intentions based on environments, IntSim facilitates the flexible realization of dynamic adversarial interactions with autonomous vehicles. Finally, extensive open-loop and closed-loop experiments on real-world datasets, including nuScenes and Waymo, demonstrate that the proposed IntSim achieves state-of-the-art performance in simulating realistic safety-critical scenarios and further improves planners in handling such scenarios.
CSTA: Spatial-Temporal Causal Adaptive Learning for Exemplar-Free Video Class-Incremental Learning
Jan 13, 2025



Continual learning aims to acquire new knowledge while retaining past information. Class-incremental learning (CIL) presents a challenging scenario where classes are introduced sequentially. For video data, the task becomes more complex than image data because it requires learning and preserving both spatial appearance and temporal action involvement. To address this challenge, we propose a novel exemplar-free framework that equips separate spatiotemporal adapters to learn new class patterns, accommodating the incremental information representation requirements unique to each class. While separate adapters are proven to mitigate forgetting and fit unique requirements, naively applying them hinders the intrinsic connection between spatial and temporal information increments, affecting the efficiency of representing newly learned class information. Motivated by this, we introduce two key innovations from a causal perspective. First, a causal distillation module is devised to maintain the relation between spatial-temporal knowledge for a more efficient representation. Second, a causal compensation mechanism is proposed to reduce the conflicts during increment and memorization between different types of information. Extensive experiments conducted on benchmark datasets demonstrate that our framework can achieve new state-of-the-art results, surpassing current example-based methods by 4.2% in accuracy on average.
X as Supervision: Contending with Depth Ambiguity in Unsupervised Monocular 3D Pose Estimation
Nov 20, 2024Recent unsupervised methods for monocular 3D pose estimation have endeavored to reduce dependence on limited annotated 3D data, but most are solely formulated in 2D space, overlooking the inherent depth ambiguity issue. Due to the information loss in 3D-to-2D projection, multiple potential depths may exist, yet only some of them are plausible in human structure. To tackle depth ambiguity, we propose a novel unsupervised framework featuring a multi-hypothesis detector and multiple tailored pretext tasks. The detector extracts multiple hypotheses from a heatmap within a local window, effectively managing the multi-solution problem. Furthermore, the pretext tasks harness 3D human priors from the SMPL model to regularize the solution space of pose estimation, aligning it with the empirical distribution of 3D human structures. This regularization is partially achieved through a GCN-based discriminator within the discriminative learning, and is further complemented with synthetic images through rendering, ensuring plausible estimations. Consequently, our approach demonstrates state-of-the-art unsupervised 3D pose estimation performance on various human datasets. Further evaluations on data scale-up and one animal dataset highlight its generalization capabilities. Code will be available at https://github.com/Charrrrrlie/X-as-Supervision.
Code Vulnerability Repair with Large Language Model using Context-Aware Prompt Tuning
Sep 27, 2024
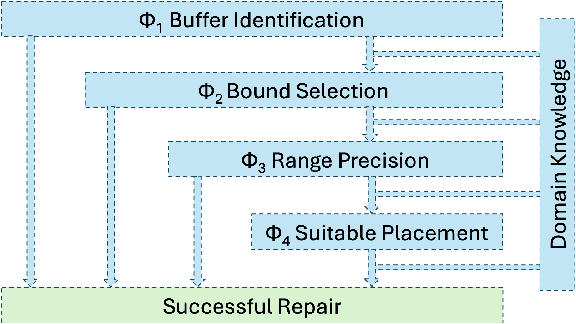

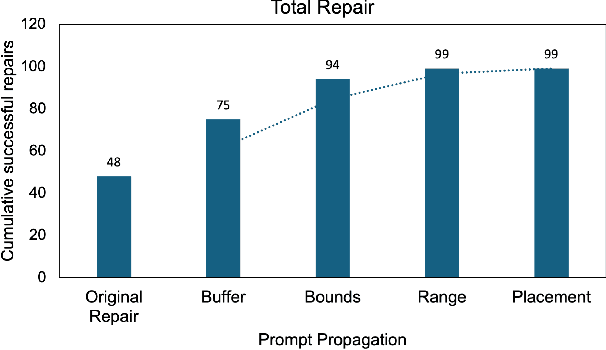
Large Language Models (LLMs) have shown significant challenges in detecting and repairing vulnerable code, particularly when dealing with vulnerabilities involving multiple aspects, such as variables, code flows, and code structures. In this study, we utilize GitHub Copilot as the LLM and focus on buffer overflow vulnerabilities. Our experiments reveal a notable gap in Copilot's abilities when dealing with buffer overflow vulnerabilities, with a 76% vulnerability detection rate but only a 15% vulnerability repair rate. To address this issue, we propose context-aware prompt tuning techniques designed to enhance LLM performance in repairing buffer overflow. By injecting a sequence of domain knowledge about the vulnerability, including various security and code contexts, we demonstrate that Copilot's successful repair rate increases to 63%, representing more than four times the improvement compared to repairs without domain knowledge.