 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Unsupervised Task-driven Models of Ventral Visual Stream via Relative Position Predictivity
May 13, 2025Based on the concept that ventral visual stream (VVS) mainly functions for object recognition, current unsupervised task-driven methods model VVS by contrastive learning, and have achieved good brain similarity. However, we believe functions of VVS extend beyond just object recognition. In this paper, we introduce an additional function involving VVS, named relative position (RP) prediction. We first theoretically explain contrastive learning may be unable to yield the model capability of RP prediction. Motivated by this, we subsequently integrate RP learning with contrastive learning, and propose a new unsupervised task-driven method to model VVS, which is more inline with biological reality. We conduct extensive experiments, demonstrating that: (i) our method significantly improves downstream performance of object recognition while enhancing RP predictivity; (ii) RP predictivity generally improves the model brain similarity. Our results provide strong evidence for the involvement of VVS in location perception (especially RP prediction) from a computational perspective.
Self-Attentive Spatio-Temporal Calibration for Precise Intermediate Layer Matching in ANN-to-SNN Distillation
Jan 14, 2025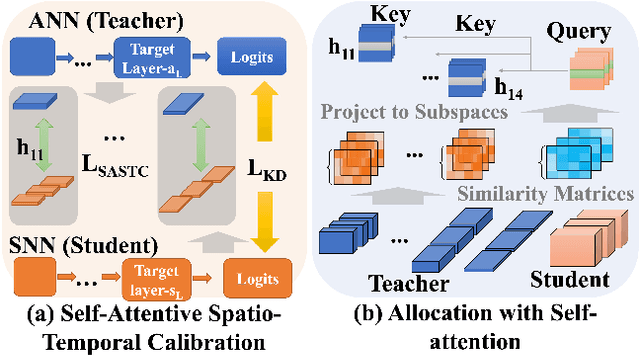

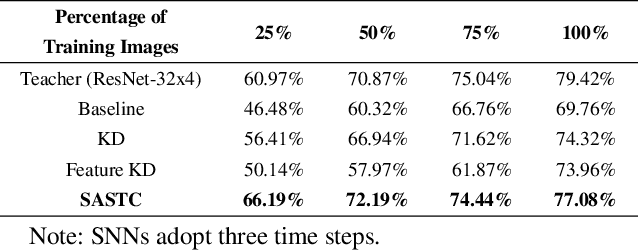
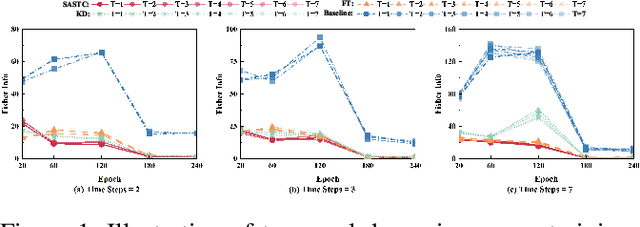
Spiking Neural Networks (SNNs) are promising for low-power computation due to their event-driven mechanism but often suffer from lower accuracy compared to Artificial Neural Networks (ANNs). ANN-to-SNN knowledge distillation can improve SNN performance, but previous methods either focus solely on label information, missing valuable intermediate layer features, or use a layer-wise approach that neglects spatial and temporal semantic inconsistencies, leading to performance degradation.To address these limitations, we propose a novel method called self-attentive spatio-temporal calibration (SASTC). SASTC uses self-attention to identify semantically aligned layer pairs between ANN and SNN, both spatially and temporally. This enables the autonomous transfer of relevant semantic information. Extensive experiments show that SASTC outperforms existing methods, effectively solving the mismatching problem. Superior accuracy results include 95.12% on CIFAR-10, 79.40% on CIFAR-100 with 2 time steps, and 68.69% on ImageNet with 4 time steps for static datasets, and 97.92% on DVS-Gesture and 83.60% on DVS-CIFAR10 for neuromorphic datasets. This marks the first time SNNs have outperformed ANNs on both CIFAR-10 and CIFAR-100, shedding the new light on the potential applications of SNNs.
LaSNN: Layer-wise ANN-to-SNN Distillation for Effective and Efficient Training in Deep Spiking Neural Networks
Apr 17, 2023

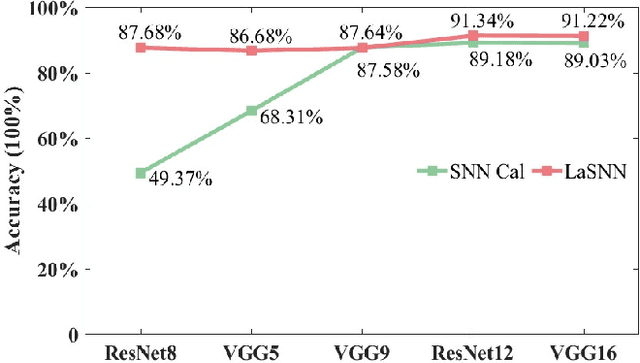

Spiking Neural Networks (SNNs) are biologically realistic and practically promising in low-power computation because of their event-driven mechanism. Usually, the training of SNNs suffers accuracy loss on various tasks, yielding an inferior performance compared with ANNs. A conversion scheme is proposed to obtain competitive accuracy by mapping trained ANNs' parameters to SNNs with the same structures. However, an enormous number of time steps are required for these converted SNNs, thus losing the energy-efficient benefit. Utilizing both the accuracy advantages of ANNs and the computing efficiency of SNNs, a novel SNN training framework is proposed, namely layer-wise ANN-to-SNN knowledge distillation (LaSNN). In order to achieve competitive accuracy and reduced inference latency, LaSNN transfers the learning from a well-trained ANN to a small SNN by distilling the knowledge other than converting the parameters of ANN. The information gap between heterogeneous ANN and SNN is bridged by introducing the attention scheme, the knowledge in an ANN is effectively compressed and then efficiently transferred by utilizing our layer-wise distillation paradigm. We conduct detailed experiments to demonstrate the effectiveness, efficacy, and scalability of LaSNN on three benchmark data sets (CIFAR-10, CIFAR-100, and Tiny ImageNet). We achieve competitive top-1 accuracy compared to ANNs and 20x faster inference than converted SNNs with similar performance. More importantly, LaSNN is dexterous and extensible that can be effortlessly developed for SNNs with different architectures/depths and input encoding methods, contributing to their potential development.